一、Set
1.1 Set集合简介
Set接口也继承自Collection接口,同时也继承了Collection接口的全部方法。它有如下特点:
1、Set集合不允许存放重复元素,所以在向Set集合中添加元素,我们需要针对元素进行重写equals()
2、Set集合在存放元素时,可以是有序的,也可以是无序的(具体要根据使用的子类的类型来定义)
3、无法使用 下标 的方式来进行检索元素
Set接口的具体子类
实现Set接口的类包括AbstractSet、ConcurrentSkipListSet、CopyOnWriteArraySet、EnumSet、HashSet、JobStateReasons、LinkedHashSet、TreeSet,但是最常用的是HashSet和TreeSet类
1.2 HashSets
HashSet 类是基于哈希算法的Set接口实现,结构为数组+链表+红黑树
1.2.1 HashSet集合的特点
1、Hashset 是无序的
2、它可以通过比较hash值,以及比较equals() 来判断,集合中是否已经存在 相同的元素,如果有,就不需要再进行存放
3、它允许包含null元素
1.2.2 HashSet的使用和底层细节
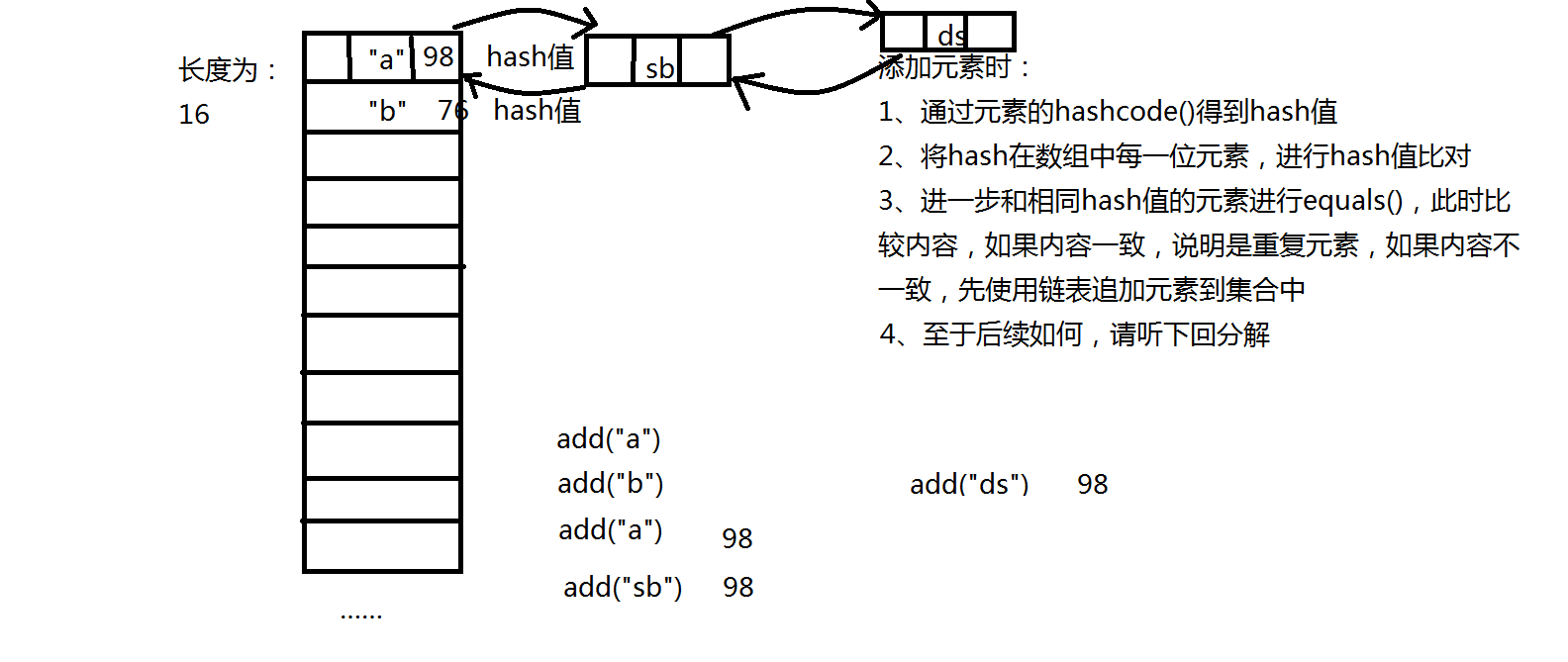
Set<String> data = new Hash<String>();
但是new 该集合的时候,内部实际上用到了HashMap,并采用HashMap的key去重方案,完成对集合中元素的去重
1.2.3 HashSet的常用API
package com.woniuxy.java21.study;import java.util.HashSet;import java.util.Set;public class HashSetStudy {public static void main(String[] args) {// TODO Auto-generated method stubstudy01();}/**** HashSet的基本用法*/private static void study01() {// TODO Auto-generated method stubSet<String> data = new HashSet<String>();//添加元素data.add("a");data.add("a");data.add("a");data.add("b");data.add("c");//获得集合中元素的个数System.out.println(data.size());//判断集合中是否拥有某一个元素System.out.println(data.contains("b"));//遍历(1) foreach// for (String string : data) {// System.out.println(string);// }//遍历(2)迭代器// Iterator iterator = data.iterator();// while(iterator.hasNext()) {// String str = (String) iterator.next();// System.out.println(str);// if("a".equals(str)) {// //移除元素的方法// iterator.remove();// }// }data.remove("a");System.out.println(data.size());}}
1.3 TreeSet
TreeSet同样实现了Set接口,例外还实现SortedSet接口,从而实现了:既可以去重,又可以排序,结构为:红黑树
1.3.1 TreeSet的特点:
1、它内部的元素在存放时,有一定的存储顺序
2、它同样不能存放重复元素
3、无法存放null元素
1.3.2 TreeSet的用法和常用API
package com.woniuxy.java21.study;import java.util.Iterator;import java.util.Set;import java.util.TreeSet;public class TreeSetStudy {public static void main(String[] args) {// TODO Auto-generated method stub//定义TreeSet的集合TreeSet<String> data = new TreeSet<String>();data.add("a");data.add("c");data.add("a");data.add("d");data.add("b");//得到集合长度System.out.println(data.size());//判断集合中是否包含某一个元素System.out.println(data.contains("a"));//判断集合是否为空System.out.println(data.isEmpty());// data.remove("a");//取得第1个元素System.out.println(data.first());//取得最后1个元素System.out.println(data.last());//严格返回比“b” 大的,该集合中的最小元素,如果没有此元素则返回 null (比我大的,但是又是最靠近我的)System.out.println(data.higher("b"));//返回比我小的,也是最靠近我的System.out.println(data.lower("b"));//取得集合中,比我小的所有元素System.out.println(data.headSet("c"));//取得集合中,比我大的所有元素(但是包含自己)System.out.println(data.tailSet("b"));//遍历(1)foreach// for (String string : data) {// System.out.println(string);// }//遍历(2)迭代器// Iterator<String> iterator = data.iterator();// while(iterator.hasNext()) {//// String str = iterator.next();//// System.out.println(str);// }}}
1.3.3 TreeSet的排序规则
自然排序
在JDK类库中,有一部分类实现了Comparable接口,例如Integer、Double、String等等。Comparable接口在java.lang包中,该接口有一个compareTo(Object o)方法,返回整型数据。对于表达式x.compareTo(y),如果返回值为0,则表示x和y相等;如果返回值大于0,则表示x大于y;如果返回值小于0,则表示x小于y。TreeSet集合调用对象的compareTo()方法比较集合中的大小,然后进行升序排列,这种方式称为自然排序
如果元素要参与自然排序,需要实现一个接口Comparable
白话:凡是元素自带了排序规则的,都是属于自然排序
eg: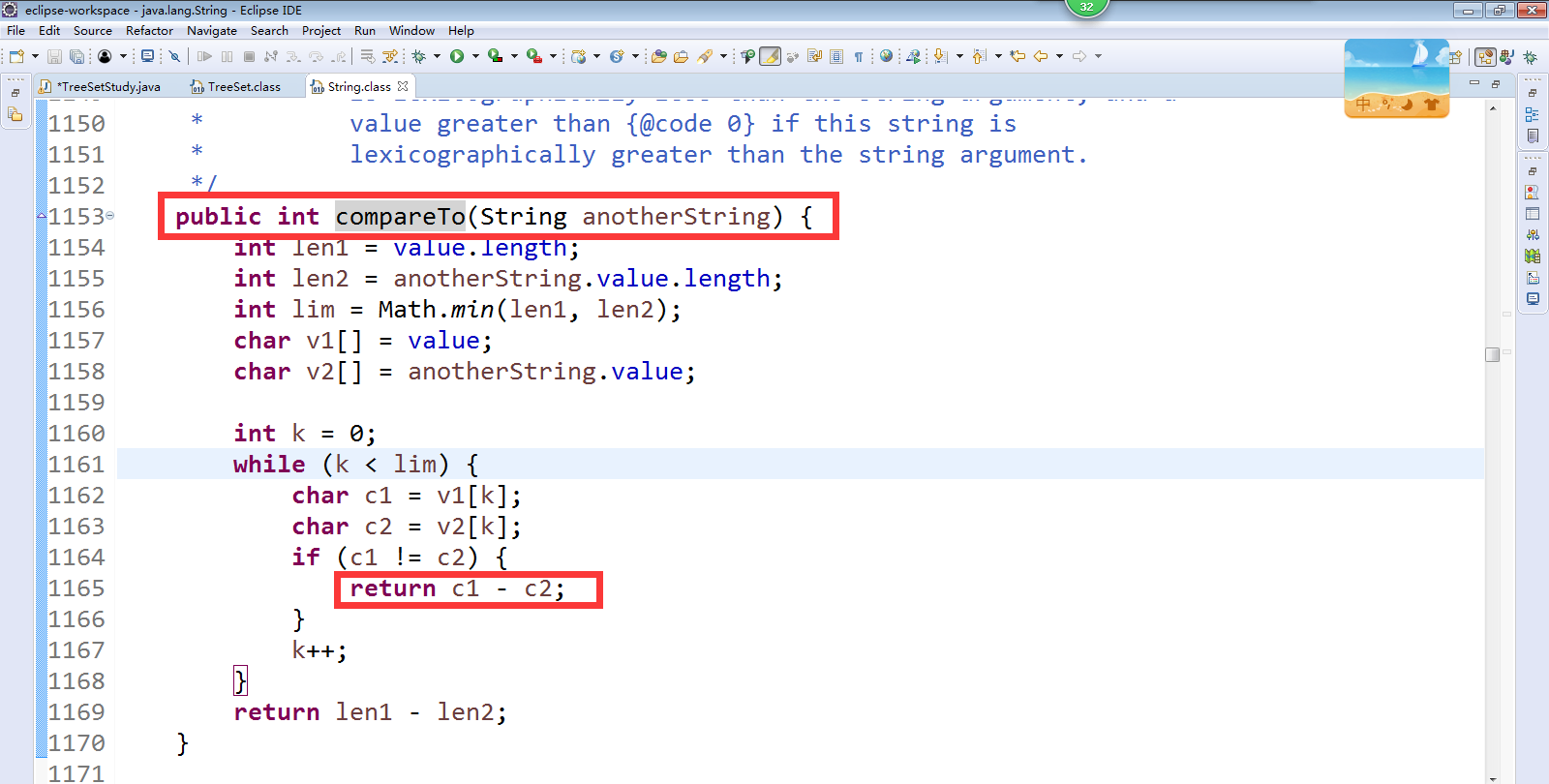
package com.woniuxy.java21.bean;import java.io.Serializable;public class StudentBean implements Serializable,Comparable<StudentBean> {/****/private static final long serialVersionUID = -2640219895840760729L;private String name;private int age;public StudentBean(String name, int age) {super();this.name = name;this.age = age;}public StudentBean() {super();// TODO Auto-generated constructor stub}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + age;result = prime * result + ((name == null) ? 0 : name.hashCode());return result;}@Overridepublic boolean equals(Object obj) {if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;StudentBean other = (StudentBean) obj;if (age != other.age)return false;if (name == null) {if (other.name != null)return false;} else if (!name.equals(other.name))return false;return true;}/*** 定义排序规则*/@Overridepublic int compareTo(StudentBean o) {// TODO Auto-generated method stub//自定义排序规则(0 ---我们地位是一样的 整数 ---你的地位比我大//负数 --- 你的地位比我小)return this.name.hashCode() - o.name.hashCode();}}
private static void study03() {// TODO Auto-generated method stubTreeSet<StudentBean> data = new TreeSet<StudentBean>();StudentBean stu01 = new StudentBean("张三",18);StudentBean stu02 = new StudentBean("李四",15);StudentBean stu03 = new StudentBean("王五",23);data.add(stu01);data.add(stu02);data.add(stu03);System.out.println(data);}
自定义排序
自定义排序 和自然排序 都是用来集合完成排序的,区别在于:
自然排序,需要在元素身上实现Comparable
而自定义排序 ,需要程序员自己制定 排序比较器
package com.woniuxy.java21.util;import java.util.Comparator;import com.woniuxy.java21.bean.StudentBean;/*** 自定义比较器,用来完成集合排序* @author Administrator**/public class InitStudentComparator implements Comparator<StudentBean>{/**** 0 我们地位相当* 正数 你的地位比我大 应该靠后* 负数 你的地位比我低 应该靠前*/@Overridepublic int compare(StudentBean o1, StudentBean o2) {// TODO Auto-generated method stub//升序规则return o1.getAge() - o2.getAge();}}
package com.woniuxy.java21.study;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
import com.woniuxy.java21.bean.StudentBean;
import com.woniuxy.java21.util.InitStudentComparator;
public class TreeSetStudy {
public static void main(String[] args) {
// TODO Auto-generated method stub
// study01();
// study02();
study03();
}
private static void study03() {
// TODO Auto-generated method stub
TreeSet<StudentBean> data = new TreeSet<StudentBean>(new InitStudentComparator());
StudentBean stu01 = new StudentBean("张三",18);
StudentBean stu02 = new StudentBean("李四",15);
StudentBean stu03 = new StudentBean("王五",23);
data.add(stu01);
data.add(stu02);
data.add(stu03);
System.out.println(data);
}
/**
* TreeSet的排序规则
*/
private static void study02() {
// TODO Auto-generated method stub
// 定义TreeSet的集合
TreeSet<String> data = new TreeSet<String>();
data.add("a");
data.add("c");
data.add("a");
data.add("d");
data.add("b");
// 遍历(1)foreach
for (String string : data) {
System.out.println(string);
}
}
private static void study01() {
// TODO Auto-generated method stub
// 定义TreeSet的集合
TreeSet<String> data = new TreeSet<String>();
data.add("a");
data.add("c");
data.add("a");
data.add("d");
data.add("b");
// 得到集合长度
System.out.println(data.size());
// 判断集合中是否包含某一个元素
System.out.println(data.contains("a"));
// 判断集合是否为空
System.out.println(data.isEmpty());
// data.remove("a");
// 取得第1个元素
System.out.println(data.first());
// 取得最后1个元素
System.out.println(data.last());
// 严格返回比“b” 大的,该集合中的最小元素,如果没有此元素则返回 null (比我大的,但是又是最靠近我的)
System.out.println(data.higher("b"));
// 返回比我小的,也是最靠近我的
System.out.println(data.lower("b"));
// 取得集合中,比我小的所有元素
System.out.println(data.headSet("c"));
// 取得集合中,比我大的所有元素(但是包含自己)
System.out.println(data.tailSet("b"));
// 遍历(1)foreach
// for (String string : data) {
// System.out.println(string);
// }
// 遍历(2)迭代器
// Iterator<String> iterator = data.iterator();
// while(iterator.hasNext()) {
//
// String str = iterator.next();
//
// System.out.println(str);
// }
}
}
1.4 HashSet和TreeSet的区别
1、他们各自底层的实现原理不一样, HashSet的底层是HashMap,TreeSet的底层是TreeMap
2、各自数据结构也不一样,HashMap是数组 + 链表 + 红黑树,而TreeMap 直接就是红黑树
3、他们各自的去重原理也不一样,HashSet是采用Hash值结合equals()来完成去重,而TreeSet 他是通过比较器来去重
4、Hashset是无序的,而TreeSet有序的
5、Hashset可以存放null元素,而TreeSet是无法存放null元素
1.5 HashCode相关面试题
TeacherBean teacherBean01 = new TeacherBean("马老师",25,30000);
TeacherBean teacherBean02 = new TeacherBean("马老师",25,30000);
//2个不同对象(地址不一样)
System.out.println(teacherBean01 == teacherBean02);
System.out.println(teacherBean01.equals(teacherBean02));
System.out.println(teacherBean01.hashCode() == teacherBean01.hashCode());
//不同的对象,可能拥有相同的Hash值,同一个对象,他们的Hash值一定一样
相同的Hashcode值,不一定就是同一个对象,但是同一个对象,它们的Hashcode值一定是相同
原因是:我们可能重写了Hashcode()算法
二、Map
2.1 Map简介
Map 和List Set一样都是JCF的一部分,List和Set是属于Collection体系的,而Map是个单独的体系(与Collection同级)
List,Set 中直接存储1组对象,但是Map中它是存储2组对象,分别是:key - value(k-v键值对)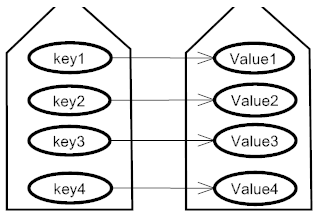
其中key 和value 的关系是:1-1对应,1个key 对应 1个值
key 不允许重复,但是value 是可以重复,而且key 是允许放null的
2.2 Map公共的API
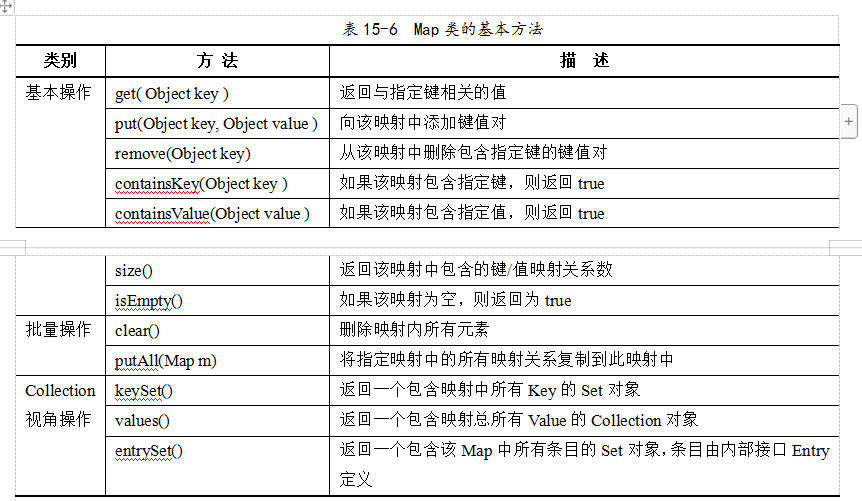
2.3 HashMap
HashMap 是Map接口中最为常用的实现类,它的结构是:数组 + 链表 + 红黑树(JDK1.8以后)(JDK1.8版本之前是数组 + 链表)
2.3.1 HashMap 的使用
Map<String,String> datas = new HashMap<String,String>();
2.3.2 HashMap的底层结构细节
HashMap 定义了一个关于节点的数组,数组的初始容量是 16
当Hash数组中的元素的个数 >= 0.75 * 长度时,Hash数组就会自动扩容为2倍
单链变成红黑树的条件是:当数组的长度>= 64,并且单链的长度 >= 8个时,将转换为红黑树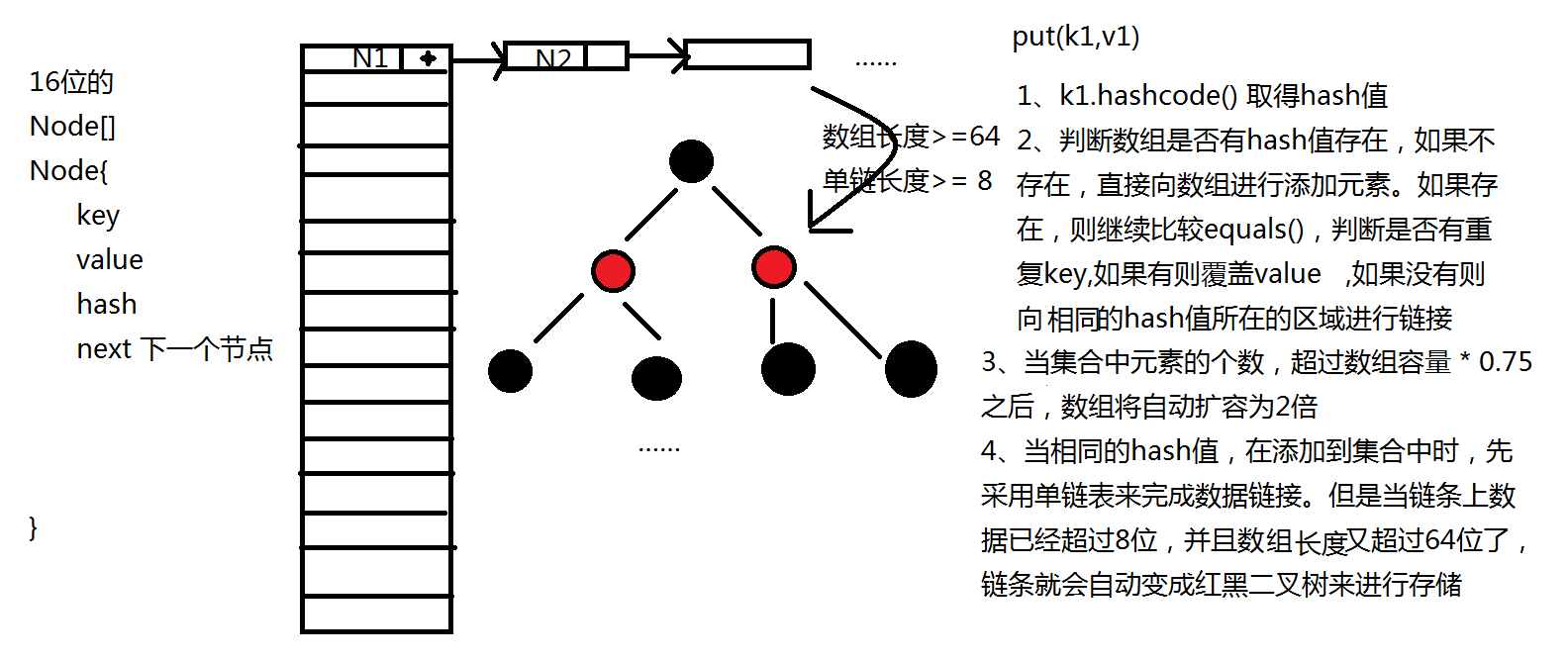
2.3.3 HashMap常用API
package com.woniuxy.java21.study;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapStudy {
public static void main(String[] args) {
// TODO Auto-generated method stub
Map<String,String> datas = new HashMap<String,String>();
//向Map集合中添加元素
datas.put("tea01", "陈老师");
datas.put("tea02", "苍老师");
//当相同的key,value的操作是覆盖
datas.put("tea03", "张老师");
datas.put("tea03", "王老师");
//根据key 获得值
System.out.println(datas.get("tea03"));
//获得Map中元素的个数
System.out.println(datas.size());
//判断集合中是否有指定的key 或者value
System.out.println(datas.containsKey("tea01"));
System.out.println(datas.containsValue("张老师"));
//遍历Map(方式一)
// Set<Entry<String, String>> set = datas.entrySet();
// for (Entry<String, String> entry : set) {
// System.out.println("key=" + entry.getKey() + " value="+ entry.getValue());
// }
//遍历Map(方式二)
// Set<String> keys = datas.keySet();
// for (String key : keys) {
// System.out.println(datas.get(key));
// }
//根据key 删除 key - value的结构
datas.remove("tea02");
//返回集合中元素的个数
System.out.println(datas.size());
}
}
注意
HashMap中作为key的对象,为了实现去重效果,一定要重写hashcode() 以及equals()方法
2.4 TreeMap
TreeMap 底层就不是:数组 + 链表 + 红黑树,而是它直接就是一个红黑树
它的API和HashMap 几乎一致,它的区别是:它可以自然排序或自定义排序而已
package com.woniuxy.java21.study;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import com.woniuxy.java21.bean.CarBean;
public class TreeMapStudy {
public static void main(String[] args) {
// TODO Auto-generated method stub
CarBean car01 = new CarBean("奥迪", "Audi", "小轿车");
CarBean car02 = new CarBean("奥拓", "Auto", "小轿车");
CarBean car03 = new CarBean("阿斯顿.马丁", "Aston martin", "小轿车");
CarBean car04 = new CarBean("宝马", "Bmw", "小轿车");
CarBean car05 = new CarBean("奔驰", "Benz", "小轿车");
CarBean car06 = new CarBean("比亚迪", "Byd", "小轿车");
CarBean car07 = new CarBean("哈弗", "Haver", "小轿车");
CarBean car08 = new CarBean("悍马", "Hummer", "小轿车");
CarBean car09 = new CarBean("红旗", "Hongqi", "小轿车");
Map<CarBean,String> datas = new TreeMap<CarBean,String>();
datas.put(car01, "小苍");
datas.put(car02, "小王");
datas.put(car03, "翠花");
datas.put(car04, "小白");
datas.put(car05, "小苍");
datas.put(car08, "小黑");
datas.put(car06, "小苍");
datas.put(car07, "小黄");
datas.put(car09, "小红");
//遍历
Set<CarBean> keys = datas.keySet();
for (CarBean carBean : keys) {
System.out.println(carBean);
}
}
}
2.5 HashTable
HashTable 也是Map接口的实现类之一,它的用法和HashMap是一样的,区别在于:它定义的方法使用了synchronized关键字,表示:它线程安全,但是效率低下
2.6 HashMap、TreeMap 、HashTable 区别
首先,他们3个都是Map接口的实现类,只是各自的底层上有些区别:
1、从底层结构来讲:
HashMap底层是数组 + 单链表 + 红黑二叉树来实现的
TreeMap底层是红黑二叉树
HashTable 底层是:数组 + 单链表
2、HashMap 无法针对数据进行自动排序,而TreeMap是可以根据元素提供的比较器,完成自然排序或自定义排序
3、HashMap 没有提供synchronized关键字,而HashTable提供该关键字,所以
HashTable是线程安全的,但是效率不高。HashMap的效率相对较高
4、HashTable、TreeMap不允许放置null值和null 键,HashMap 允许放置null值 和null键
2.7 Properties (属性)
它也是一种key-value结构的集合,它是HashTable的子类,它同HashTable在某些规则上是一样,也是添加了synchronized关键字的。例外,同样,不允许放置null 值 和null键
它的主要使用场景:从配置文件中 加载内容到程序来中
mysql.properties:
jdbc.url=1231wrwer
jdbc.userName=userpu
jdbc.password=123456
jdbc.driverClassName=234
package com.woniuxy.java21.study;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
import com.woniuxy.java21.bean.CarBean;
import com.woniuxy.java21.bean.StudentBean;
public class PropertiesStudy {
public static void main(String[] args) {
// TODO Auto-generated method stub
// study01();
study02();
}
private static void study02() {
// TODO Auto-generated method stub
Properties props = new Properties();
FileInputStream fis = null;
try {
// File.separatorChar 代表 \\ 在windows系统中
String path = System.getProperty("user.dir") + File.separatorChar + "src" + File.separatorChar +"mysql.properties" ;
// System.out.println(path);
File file = new File(path);
fis = new FileInputStream(file);
props.load(fis);
System.out.println(props.get("jdbc.url"));
System.out.println(props.get("jdbc.userName"));
System.out.println(props.get("jdbc.password"));
System.out.println(props.get("jdbc.driverClassName"));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}finally {
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
private static void study01() {
// TODO Auto-generated method stub
// Properties props = new Properties();
// //同样可以放置null值和null键
// props.put(null, null);
// //也可以放置其他东西
// props.put(new CarBean(), new StudentBean());
// props.put("userName", "小张");
// System.out.println(props.get("userName"));
}
}

若有收获,就点个赞吧
0 人点赞
