一、多表查询
1.1 使用子查询(不推荐)
例如:查询妻子时,要求显示其丈夫的内容
select (select husband_name from husband_info where fk_wife_id = w.id) ,wife_name, gender from wife_info as w;
例如:查询丈夫时,要求显示其妻子的内容
select id,husband_name,gender,(select wife_name from wife_info where id = h.fk_wife_id) as wife_name from husband_info as h;
1.2 使用子查询(in)
例如:查询 妻子名称是“小” 开头的,丈夫的信息
select id,husband_name,gender from husband_info where fk_wife_id in (select id from wife_info where wife_name like '小%');
in 的执行流程:
1、先进行子查询
2、将子查询的结果和 外部查询语句 进行 笛卡尔乘积匹配 : 300(内) X 30000(外) = 9000000
3、将匹配后的结果,使用where 去做条件筛选,将匹配的留下,将不匹配的剔除
1.3 使用子查询(exists)
例如:查询 妻子名称是“小” 开头的,丈夫的信息
select id,husband_name,gender from husband_info as h where exists (select w.id from wife_info as w where h.fk_wife_id = w.id and w.wife_name like '小%');
exists 的执行流程:
1、先查询外部的SQL语句,将查询结果,逐一和 子查询的结果集根据条件进行匹配
2、如果匹配上了,就显示外表的数据;如果没匹配上,就不显示外表的数据
3、进入外部的下一条数据进行匹配
1.4 in与exists使用场合
in 比较适合于 内表的数据 比 外表的数据 少的情况下
exists 比较适合于 内表的数据 比 外表的数据 多的情况下
**
1.5 in 和 exists 谁性能最高?(面试题)
1、当内部表 和 外部表 数据量一样,两个几乎差不多
2、当内部表 数据量 大于 外部表时 exists 的性能高于in
3、当内部表 数据量 小于 外部表时 in 的性能高于exists
1.6 not in 和 not exists 谁性能更高?(面试题)
任何场合下:not exists 性能都是最高的,原因是:not in 一定是全表检索,而not exist 至少 内部可以使用索引
1.7 union 与 union all (联合查询)(面试题)
该关键字的使用场景: 当多张表的表结构相同,但是数据不相同,用户又需要同时显示多张表的内容时
-- 将2个表的数据,联合到一起,并针对重复数据去重
select id,wife_name from wife_info union select id,wife_name from wife_02_info;
-- 将2个表的数据,联合到一起,不会针对重复数据去重
select id,wife_name from wife_info union all select id,wife_name from wife_02_info;
使用union会对重复数据去重,union all不会去重
**
二、联表查询(重点)
2.1 外联查
2.1.1 left [outer] join
以左表为基础,进行右表数据匹配,右边有数据则显示数据,右边没有数据,则显示为NULL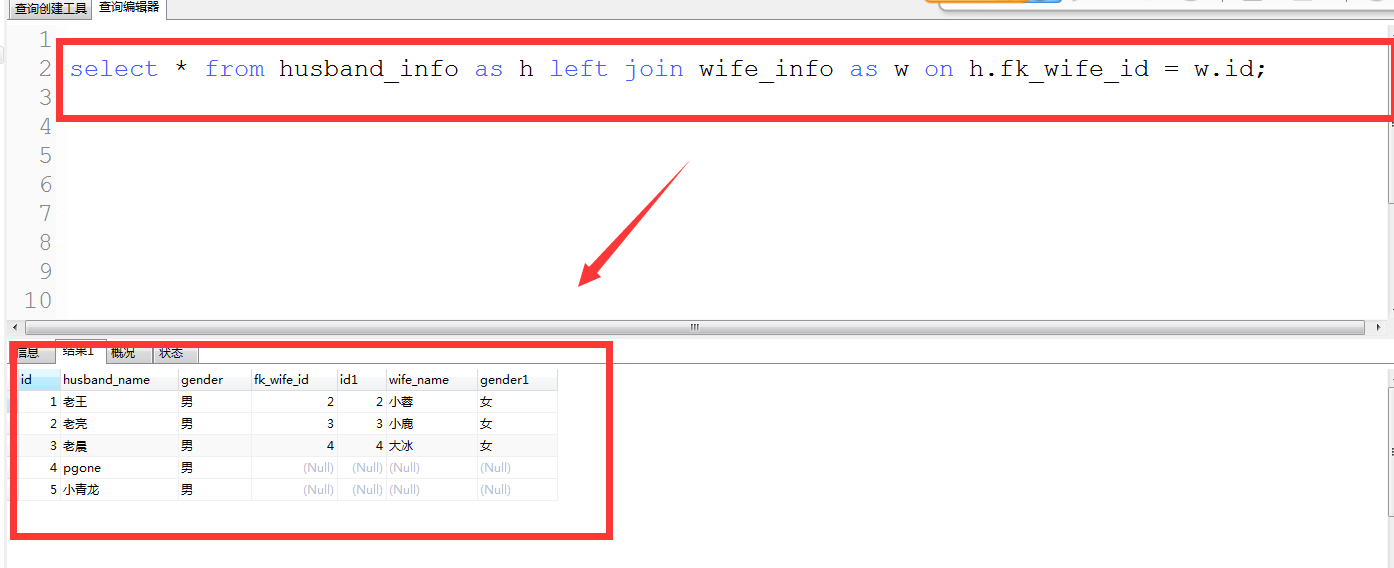
当然,一般情况下,都需要添加:数据筛选条件
例如:
select * from husband_info as h left join wife_info as w on h.fk_wife_id = w.id where w.wife_name like '小%';
2.1.2 right [outer] join
以右表为基础,进行左表数据匹配,左边有数据则显示数据,左边没有数据,则显示为NULL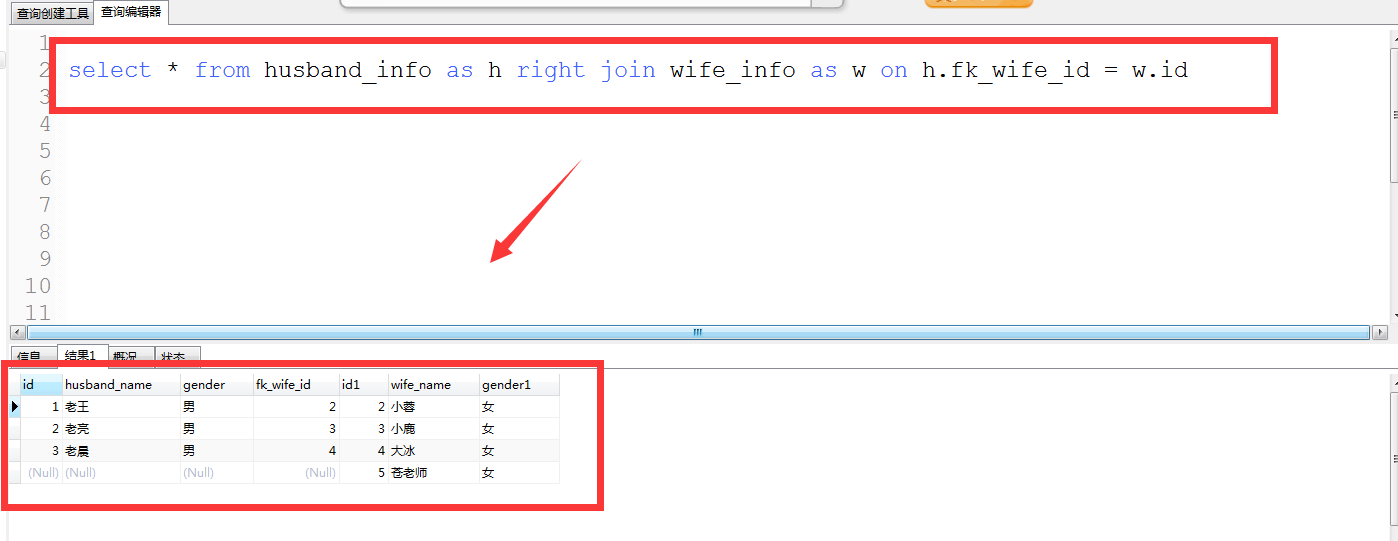
当然,一般情况下,都需要添加:数据筛选条件
例如:
select * from husband_info as h right join wife_info as w on h.fk_wife_id = w.id where w.wife_name like '小%';
2.2 内联查(inner join)
内联查,显示的中间交集的数据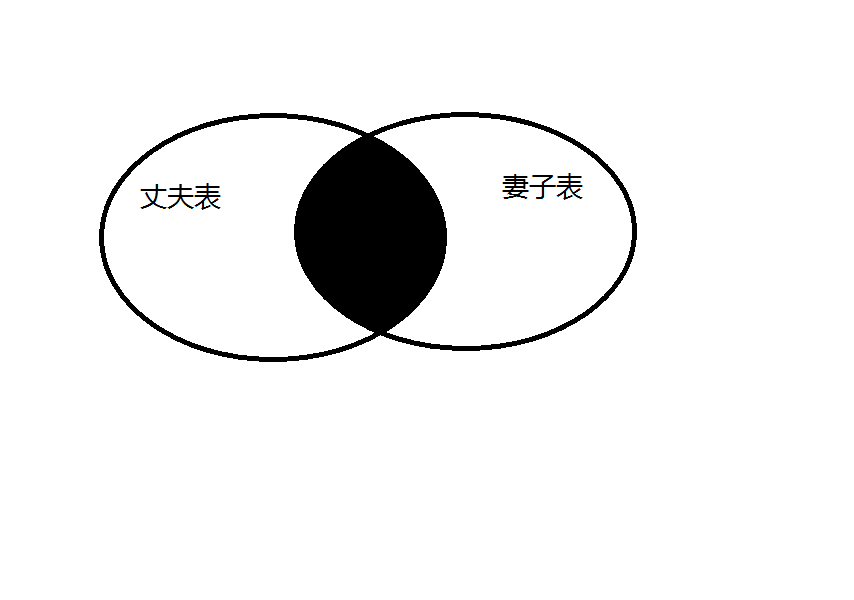
当然,一般情况下,都需要添加:数据筛选条件
例如:
select * from husband_info as h inner join wife_info as w on h.fk_wife_id = w.id where w.wife_name like '小%';
使用最多的是left join | inner join
2.3 简化inner join(最常用)
省略:inner join on 使用where 去做 表之间的连接
select * from husband_info as h,wife_info as w where h.fk_wife_id = w.id and w.wife_name like '小%';
三、视图(常用)
面临更多的表联表,为了简化联表操作,需要使用Mysql中的视图
3.1 视图的概念
视图:就是一张虚拟表,它的所有的数据都是来自于其他表的联合,它不是一张真真的表,因为它没有任何的表文件存在
3.2 视图的创建
连表超过3张表以上,就可以采用 视图!
语法结构:
create view 视图的名字 as select 连表查询内容
举例:
create view v_player_game as select p.id as p_id,p.player_name,g.id as g_id,g.game_name from player_info as p, player_game as pg, game_info as g where p.id = pg.fk_player_id and pg.fk_game_id = g.id
使用:
select game_name,count(*) from v_player_game group by game_name;
四、触发器(trigger 重点了解)
当数据库中,某一个表的内容发生改变时,需要其他表也同样做出改变时,可以使用它
触发器的应用场合:
1、卖家卖出一件商品之后, 库存量 - 1
2、系统新注册一个用户, 用户统计量 + 1
3、删除妻子时,自动将丈夫也销毁掉
4.1 触发器的类型
新增触发器 在新增数据时,进行触发
修改触发器 在修改数据时,进行触发
删除触发器 在删除数据时,进行触发
4.2 触发器的触发时机
1、在数据变化之前,触发 before
如果在触发器,需要使用数据变化之前的数据,我们可以使用关键字old来获取
2、在数据变化之后,触发 after
如果在触发器,需要使用数据变化之后的数据,我们可以使用关键字new来获取
4.3 触发器的语法
create trigger 触发器的名字 触发的时机 触发器的类型 on 作用在哪张表
for each row begin
-- 触发的内容
end;
举例(1):
create trigger trgger_wife_delete before delete on wife_info
for each row BEGIN
delete from husband_info where fk_wife_id = old.id;
end;
举例(2):
create trigger trgger_user_info_new after insert on user_info
for each row BEGIN
update user_count set nums = nums + 1 where id = '1';
end;
鸡肋:高手认为这个东西很不错,菜鸟就 会莫名其妙的发现数据被修改,被删除了!!!
五、事务(重点)
事务: 一段具有明确开始和结束标记的 并且执行顺序是有序的一个过程
事务举例: 1天的生活 :7:00 起床 7:30 出门 —> 9:20 上课 —> 12:20 吃饭
—> 2:00 上课 —> 6:00 吃饭 —> 6.40 上晚自习 —> 8:30 放学 —> 10:00 到家
—> 12:00 上床 —> 2:00 看手机
出生 —> 3岁(幼儿园) —> 6岁(小学) —> 12岁(初中)—>15(高中)—> 18(上大学) —> 23(大学毕业,走向社会,被社会毒打) —> 27(结婚) —> 29(养小孩) —>
55岁(退休,带小孩) —> 死亡
张三给李四转钱 5000元
1、张三查账 余额是否 > 5000
2、从张三的卡中,扣除5000
3、将5000元,添加到李四的账号中
4、李四查账,看是否收到5000元
从页面发起一个请求,也是一个完整的事务!
5.1 事务的4个特性(ACID)
原子性atomicity:
事务是一个完整的个体,不能再分 对于数据库的事务来讲:就是指事务 是完整的,要么统一成功,要么统一失败
一致性consistency:
在事务处理的过程中,数据必须要保证一致性,也就是不能出错。初中:能量守恒
隔离性isolation:
事务与事务之间是相互隔离的,互不干扰的。
持久性durability:
事务一旦确认,那么它的结果就应该持久化到硬盘中,并且同一事务不能再次对它进行修改。
5.2 事务的处理方式
确认事务 commit
回滚事务 rollback
5.3 MySQL 中如何操作事务(了解)

5.4 事务的隔离级别
多个事务,可能操作同一批数据,为了保证该数据的一致性问题,数据库同样会针对数据进行上锁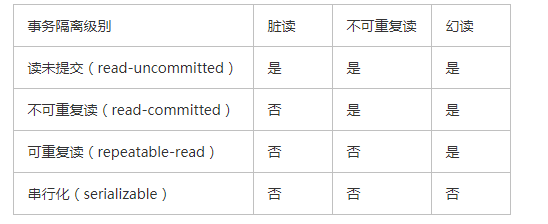
1、可串行化(serializable)
将事务按照排队的方式,依次去操作数据,同一时刻只有一个事务可以操作它。
这种隔离级别:数据的一致性最好,它一定能保证数据是准确的
但是:它的性能也是最低的
2、可重复读(repeatable-read)
这隔离级别,仅次于可串行化,它此时就允许少量的事务,同一时刻操作相同的数据
性能上有所提升,但是:数据的一致性上,稍微有所下降
它会造成一种错觉:幻读
幻读:A事务在本次事务中,对自己未操作过的数据多次读取,第一次读取时,记录不存在,第二次读取时候,记录出现了。(insert)
即:(读取了提交的新事物,insert)
A 先查询一帮数据,并且针对这一大帮做了修改,或删除。B在A修改,或删除之后,他也修改了其中的某一条数据,A再次查询数据库时,将会有一种幻象,感觉他自己没修改完,或删除完
3、读已提交(read-committed)
这隔离级别,又比可重复读低一些,它此时就允许大量的事务,同一时刻操作相同的数据,
性能上有了进一步的提升,但是:数据的一致性上,造成的问题更大
它会造成一种错误:不可重复读
不可重复读:A事务在本次事务中,对自己未操作过的数据多次读取,出现了数据不一致或记录不存在的情况。
即:(读取了提交的新事物,update,delete)
举例:你和你女朋友 2个人 公用1张卡,卡里有1000元钱, 你现在请你的朋友吃饭,在你吃饭期间,你女朋友买个一个包花费了800元,等你吃完饭需要结账时:发现卡里只有200元,你可能就不够了,你就尴尬了,你就没法再做任何处理了……
4、读未提交(read-uncommitted)
它的隔离级别最低,它就相当于没有上锁,同一时刻所有的事务都可以操作相同的数据,
性能最高,但是一致性最差,造成的问题最严重
它会造成一种错误:脏读
脏读: A事务还未提交,B事务读取到了A事务中的数据(破坏了隔离性)
即:(读取了未提交的新事物,然后被回滚了)
举例:你有一张银行卡,银行卡中突然多了500W , 你就承诺 给你所有的朋友借钱(打了包票),然后又莫名其妙的500W又消失了,现在问你,你该咋办?
你拿着数据库可能 回滚的数据,在做业务,这是最危险的!!!
当然:4种隔离级别:可串行化 读未提交 几乎没有人使用,使用最多的是:可重复读
六、InnoDB 与 MyIsam的区别(面试题)
存储引擎:就类似于游戏系统中的游戏引擎,它是整个RDBMS中最核心的东西,它决定了数据如何存储,如何获取,如何控制事务,如何控制外键 等一系列的功能
在MySQL中使用最多的是:InnoDB MyIsam
1、InnoDB 是MySQL 默认使用一种存储引擎,表的存储上,它是将一张表划分为2个文件:XXX.frm (表的表结构文件) XXX.ibd (数据和索引文件)
MyIsam 表的存储上,它是将一张表划分为3个文件:XXX.frm (表的表结构文件) XXX.MYD (数据文件) XXX.MYI (索引文件)
2、InnoDB 支持数据库的事务,而MyIsam 不支持数据库的事务
3、MyIsam 在做CRUD时,性能远高于 InnoDB
4、InnoDB 支持外键约束,但是MyIsam 连外键约束都不支持

若有收获,就点个赞吧
0 人点赞
