一、NoSQL
1.1 简介
NoSQL是对不同于传统的关系数据库的数据库管理系统的统称。
两者存在许多显著的不同点,其中最重要的是NoSQL不使用SQL作为查询语言。其数据存储可以不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般有水平可扩展性的特征。
NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。
2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的”no:sql(east)”讨论会是一个里程碑,其口号是”select fun, profit from real_world where relational=false;”。因此,对NoSQL最普遍的解释是“非关联型的”,强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
1.2 NoSQL数据库四大家族
NoSQL中的四大家族主要是:列存储、键值、图像存储、文档存储,其类型产品主要有以下这些。
| 存储类型 | NoSQL | |
|---|---|---|
| 键值存储 | 最终一致性键值存储 | Cassandra、Dynamo、Riak、Hibari、Virtuoso、Voldemort |
| 内存键值存储 | Memcached、Redis、Oracle Coherence、NCache、 Hazelcast、Tuple space、Velocity | |
| 持久化键值存储 | BigTable、LevelDB、Tokyo Cabinet、Tarantool、TreapDB、Tuple space | |
| 文档存储 | MongoDB、CouchDB、SimpleDB、 Terrastore 、 BaseX 、Clusterpoint 、 Riak、No2DB | |
| 图存储 | FlockDB、DEX、Neo4J、AllegroGraph、InfiniteGraph、OrientDB、Pregel | |
| 列存储 | Hbase、Cassandra、Hypertable |
1.3 NoSQL的优势
高可扩展性、分布式计算、没有复杂的关系、低成本、架构灵活、半结构化数据
1.4 NoSQL与RDBMS对比
| NoSQL | RDBMS |
|---|---|
| 代表着不仅仅是SQL 没有声明性查询语言 没有预定义的模式 键 - 值对存储,列存储,文档存储,图形数据库 最终一致性,而非ACID属性 非结构化和不可预知的数据 CAP定理 高性能,高可用性和可伸缩性 |
高度组织化结构化数据 结构化查询语言(SQL) (SQL) 数据和关系都存储在单独的表中。 数据操纵语言,数据定义语言 严格的一致性 基础事务 |
二、MongoDB简介
2.1 MongoDB的特性
MongoDB的3大技术特色如下所示: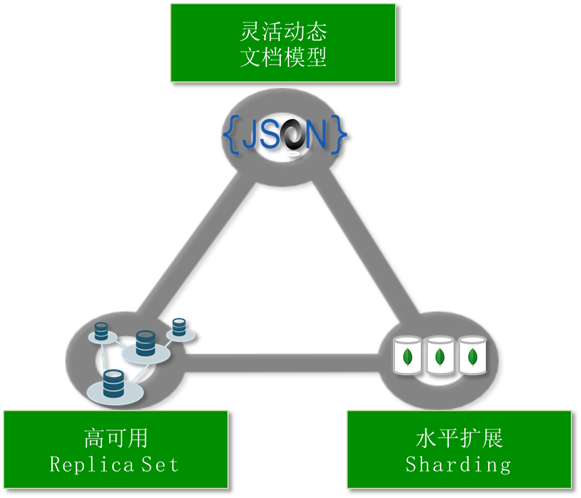
除了上图所示的还支持:
二级索引、动态查询、全文搜索 、聚合框架、MapReduce、GridFS、地理位置索引、内存引擎 、地理分布等一系列的强大功能。
但是其也有些许的缺点,例如:
多表关联: 仅仅支持Left Outer Join
SQL 语句支持: 查询为主,部分支持
多表原子事务: 不支持
多文档原子事务:不支持
16MB 文档大小限制,不支持中文排序 ,服务端 Javascript 性能欠佳
2.2 关系型数据库与mongodb对比
存储方式对比
在传统的关系型数据库中,存储方式是以表的形式存放,而在MongoDB中,以文档的形式存在。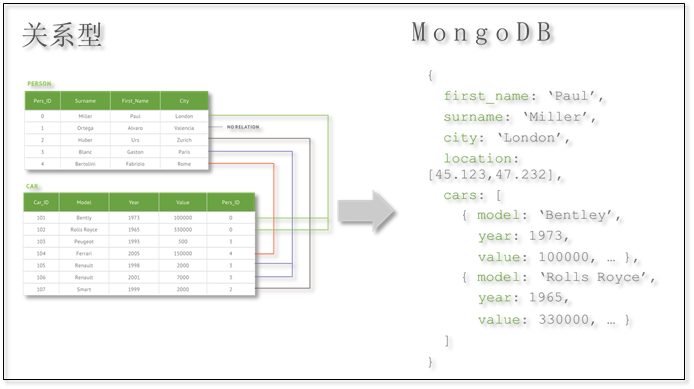
数据库中的对应关系,及存储形式的说明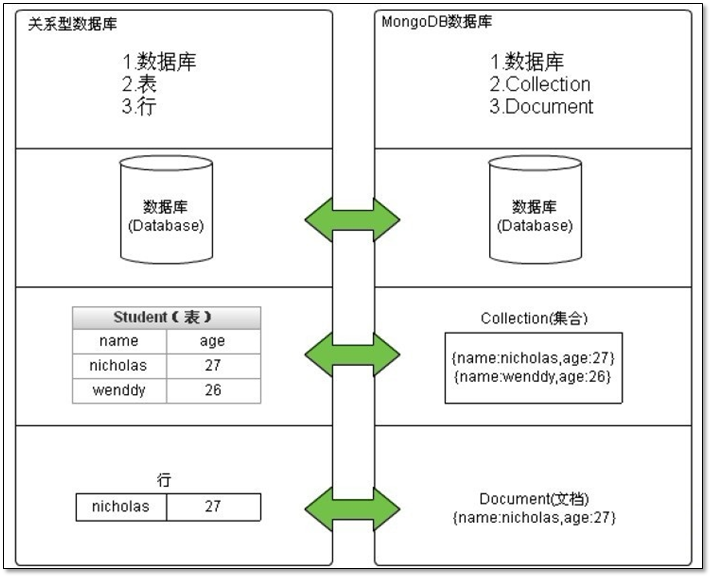
2.3 MongoDB数据存储格式
JSON格式
JSON 数据格式与语言无关,脱胎于 JavaScript,但目前很多编程语言都支持 JSON 格式数据的生成和解析。JSON 的官方 MIME 类型是 application/json,文件扩展名是 .json。
MongoDB 使用JSON(JavaScript ObjectNotation)文档存储记录。
JSON数据库语句可以容易被解析。
Web 应用大量使用,NAME-VALUE 配对
BSON格式
BSON是由10gen开发的一个数据格式,目前主要用于MongoDB中,是MongoDB的数据存储格式。BSON基于JSON格式,选择JSON进行改造的原因主要是JSON的通用性及JSON的schemaless的特性。
二进制的JSON,JSON文档的二进制编码存储格式
BSON有JSON没有的Date和BinData
MongoDB中document以BSON形式存放
例如:
> db.meeting.insert({meeting:“M1 June”,Date:”2018-01-06“});
2.4 MongoDB的优势
📢 MongoDB是开源产品
📢 On GitHub Url:https://github.com/mongodb
📢 Licensed under the AGPL,有开源的社区版本
📢 起源& 赞助by MongoDB公司,提供商业版licenses 许可
这些优势造就了mongodb的丰富的功能:
JSON 文档模型、动态的数据模式、二级索引强大、查询功能、自动分片、水平扩展、自动复制、高可用、文本搜索、企业级安全、聚合框架MapReduce、大文件存储GridFS
2.5 高可用的复制集群
自动复制和故障切换
多数据中心支持滚动维护无需关机支持最多50个成员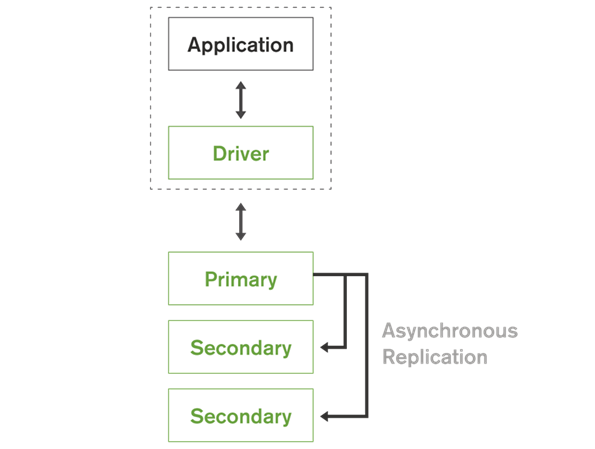
2.6 水平扩展
这种方式是目前构架上的主流形式,指的是通过增加服务器数量来对系统扩容。在这样的构架下,单台服务器的配置并不会很高,可能是配置比较低、很廉价的 PC,每台机器承载着系统的一个子集,所有机器服务器组成的集群会比单体服务器提供更强大、高效的系统容载量。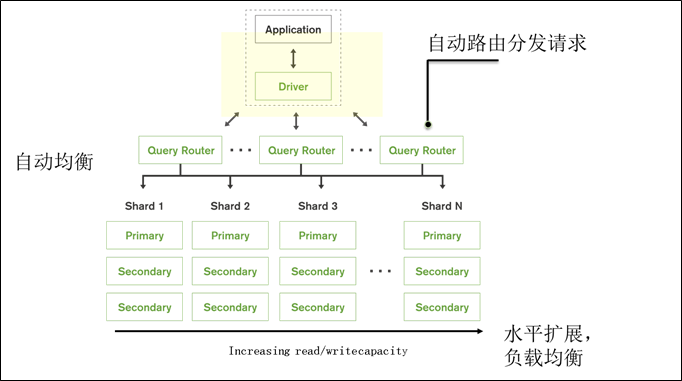
这样的问题是系统构架会比单体服务器复杂,搭建、维护都要求更高的技术背景。分片集群架构如下图所示: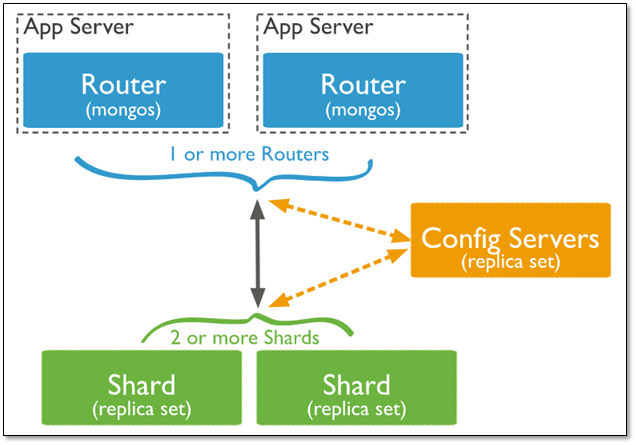
2.7 MongoDB适用场景
网站数据、缓存等大尺寸、低价值的数据
在高伸缩性的场景,用于对象及JSON数据的存储。
2.8 MongoDB 慎用场景
| 慎用场景 | 原因 |
|---|---|
| PB 数据持久存储大数据分析数据湖 | Hadoop、Spark提供更多分析运算功能和工具,并行计算能力更强 MongoDB + Hadoop/Spark |
| 搜索场景:文档有几十个字段,需要按照任意字段搜索并排序限制等 | 不建索引查询太慢,索引太多影响写入及更新操作 |
| ERP、CRM或者类似复杂应用,几十上百个对象互相关联 | 关联支持较弱,事务较弱 |
| 需要参与远程事务,或者需要跨表,跨文档原子性更新的 | MongoDB 事务支持仅限于本机的单文档事务 |
| 100% 写可用:任何时间写入不能停 | MongoDB换主节点时候会有短暂的不可写设计所限 |
2.9 什么时候该用MongDB
在下面的条件中进行选择,有一个满足的时候:可以考虑MongoDB;当有2个以上满足的时候:不会后悔的选择!
- 我的数据量是有亿万级或者需要不断扩容
- 需要2000-3000以上的读写每秒
- 新应用,需求会变,数据模型无法确定
- 我需要整合多个外部数据源
- 我的系统需要99.999%高可用
- 我的系统需要大量的地理位置查询
- 我的系统需要提供最小的latency
- 我要管理的主要数据对象<10
三、win10下安装并启动连接MongoDB
3.1 下载
地址:https://www.mongodb.com/try/download/community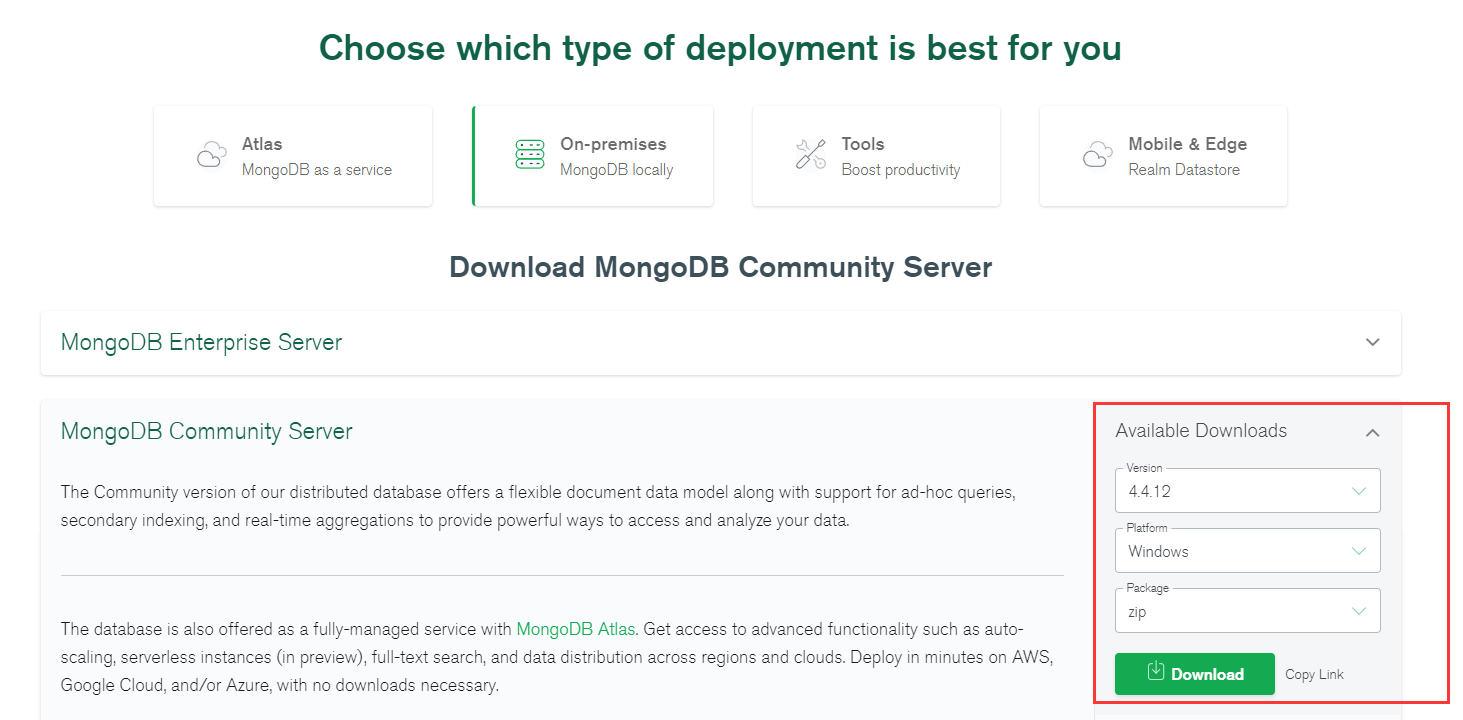
选择版本,平台,下载方式(推荐zip,直接解压即可),然后点击下载
3.2 解压安装启动
解压后,文件夹内容如下图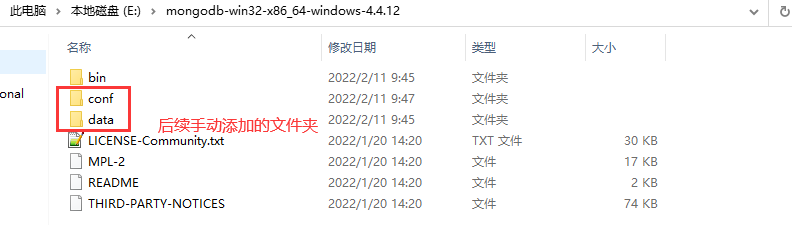
启动方式一:命令行参数方式启动服务
在bin目录下,打开cmd窗口后,输入如下命令(注意:在data文件夹下,创建db文件夹)
mongod —dbpath=..\data\db
启动后在启动信息中可以发现,mongoDB的默认端口是27017,如果想改变端口的话,使用—port来指定端口。
为了方便启动,可以将bin目录添加至环境变量的path中,bin目录中是一些常用命令,mongod是用于启动服务的,mongo是用于客户端连接服务的。
启动方式二:配置文件方式启动服务
在conf中添加 mongod.conf 文件,内容如下:
storage: dbPath: E:\mongodb-win32-x86_64-windows-4.4.12\data\db
同样,在bin目录下,打开cmd窗口后,输入如下命令
mongod -f ..\conf\mongod.conf
或
mongod -config ..\conf\mongod.conf
3.3 连接
连接方式一:shell脚本连接
同样,在bin目录下,打开cmd窗口后,输入如下命令(注意:已经启动的服务cmd窗口不能关闭,否则服务将会关闭)
mongo
或
mongo —host=127.0.0.1 —port=27017
连接方式二:compass连接(自行百度)
四、MongoDB语法
4.1 操作数据库
连接成功后,如下图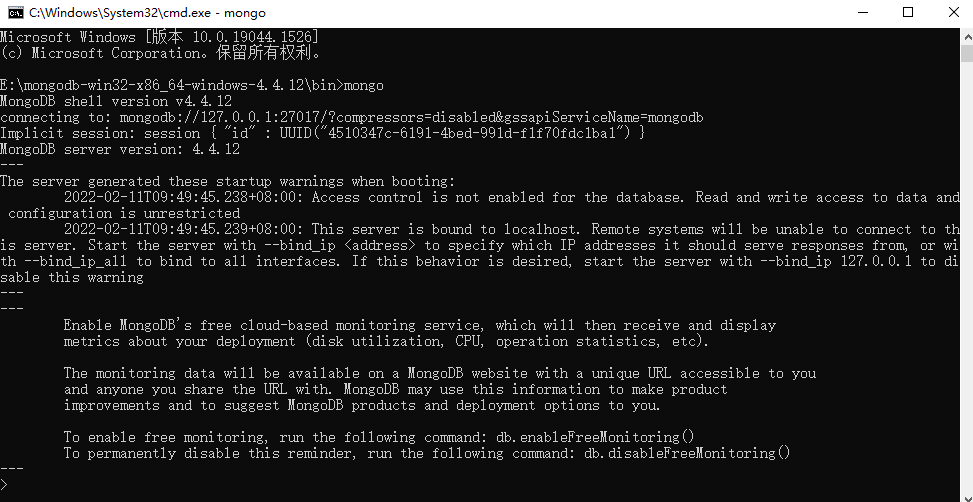
show dbs
显示当前已存在的数据库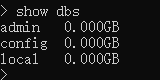
- admin:从权限的角度来看,这是”root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
use articledb
切换到 articledb
(如果没有该数据库,则会创建,注意:虽然会创建,但show dbs不会显示该数据库,因为该数据库此时还没有集合,所以还只存在于内存中,并不在磁盘上,但使用 db 命令可以看到当前正在使用的数据库为 articledb)
db
展示当前数据库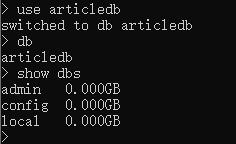
db.dropDatabase()
4.2 操作集合
4.2.1 集合的显式创建(了解)
db.createCollection(“my”)
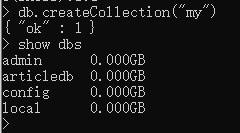
可见,当 articledb 数据库中存在集合后,show dbs就可以从磁盘中查出该数据库了
show collections
4.2.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
详见文档的插入章节。
提示:通常我们使用隐式创建文档即可。
4.2.3 集合的删除
db.集合名.drop()
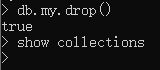
4.3 操作文档
文档(document)的数据结构和JSON基本一样。
所有存储在集合中的数据都是BSON格式。
4.3.1 文档的插入
(1)单个文档的插入
使用insert()或save()方法向集合中插入文档,语法如下
db.collection.insert(<document>,{writeConcern: <document>})
【示例】
要向comment的集合(表)中插入一条测试数据:
db.comment.insert({"articleid":"100000","content":"今天天气真好","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})

(2)批量插入
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean>})
4.3.2 文档的查询
注意:所有查询在最后加一个.pretty()都可以对结果进行美化
例如:db.comment.find().pretty()
(1)查询所有
db.comment.find()

其中,_id就是默认的id
(2)带参数的查询
db.comment.find({userid:"1001"})
注:如果只需要查询一条数据,则可以使用 findOne 方法
(3)投影查询
只查询部分字段
db.comment.find({articleid:"100000"},{articleid:1})

注:_id 字段也会默认查出
如果需要排除 _id 字段
db.comment.find({articleid:"100000"},{articleid:1,_id:0})

4.3.3 文档的更新
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
【示例】
(1)覆盖的修改
db.comment.update({articleid:"100000"},{likenum:NumberInt(1001)})
 此时将该条数据整个覆盖了,重写为了{likenum:NumberInt(1001)},其他字段没有数据了
此时将该条数据整个覆盖了,重写为了{likenum:NumberInt(1001)},其他字段没有数据了
(2)局部修改
db.comment.update({articleid:"100000"},{$set:{likenum:NumberInt(1001)}})

注意 $set 的位置
(3)批量修改
db.comment.update({articleid:"100000"},{$set:{likenum:NumberInt(1001)}},{multi:true})
如果不加 {multi:true} 的话,即使 articleid:”100000” 匹配到多条数据,也只会修改一条数据
(4)列值增长的更新
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用$inc运算符来实现。
需求:点赞数每次递增1
db.comment.update({articleid:"100000"},{$inc:{likenum:NumberInt(1)}})
4.3.4 删除文档
db.collection.remove(
<query>,
<justOne>
)
删除 articleid 为 100000 的数据(注意:如果 remove() 括号中不带条件,则全部删除,慎用)
db.comment.remove({articleid:"100000"})
4.4 文档的复杂查询
4.4.1 统计查询
(1)统计所有记录
db.comment.count()
(2)带条件的统计
db.comment.count({"articleid":"100001"})
4.4.2 分页查询
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数 量的数据。
基本语法如下所示:
db.comment.find().limit(number).skip(number)
4.4.3 排序查询
sort()方法对数据进行排序, sort() 方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1
为升序排列,而-1是用于降序排列。
db.comment.find().sort({"userid":-1})
也可以对多个字段排序
db.comment.find().sort({"userid":-1,"likenum":1})
skip(), limilt(), sort()三个放在一起执行的时候, 执行的顺序是先sort(),然后是skip(),最后是显示的limit(),和命
令编写顺序无关。
4.4.4 正则查询
MongoDB的模糊查询是通过正则表达式来实现的,举例:
db.comment.find({"content":/不好/})
4.4.5 比较查询
<,<=,>,>=操作符也是经常使用的,举例:
db.comment.find({likenum:{$gte:NumberInt(10)}})
| 操作符 | 说明 |
|---|---|
| eq | 等于 |
| ne | 不等于 |
| ne | 不等于 |
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
4.4.6 包含查询
db.comment.find({userid:{$in:["1001","1002"]}})
不包含:
db.comment.find({userid:{$nin:["1001"]}})
4.4.7 条件连接查询
and:
db.comment.find({$and:[{},{},{}]})
或
db.comment.find({key1:value1, key2:value2}).pretty()
举例:
db.comment.find({$and:[{articleid:"100000"},{userid:"1001"}]})
or:
db.comment.find({$or:[{},{},{}]})
举例:
db.comment.find({$or:[{articleid:"100000"},{articleid:"100001"}]})
4.5 常用语法小结
选择切换数据库:use articledb
插入数据:db.comment.insert({bson数据})
查询所有数据:db.comment.find()
条件查询数据:db.comment.find({条件})
查询符合条件的第一条记录:db.comment.findOne({条件})
查询符合条件的前几条记录:db.comment.find({条件}).limit(条数)
查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数)
覆盖更新(一般不用):db.comment.update({条件},{修改后的数据})
更新数据:db.comment.update({条件},{$set:{要修改部分的字段:数据}})
修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}})
删除数据:db.comment.remove({条件})
统计查询:db.comment.count({条件})
模糊查询:db.comment.find({字段名:/正则表达式/})
条件比较运算:db.comment.find({字段名:{$gt:值}})
包含查询:db.comment.find({字段名:{$in:[值1,值2]}}) 或 db.comment.find({字段名:{$nin:[值1,值2]}})
条件连接查询:db.comment.find({$and:[{条件1},{条件2}]}) 或 db.comment.find({$or:[{条件1},{条件2}]})

若有收获,就点个赞吧
0 人点赞
