一、聚合函数
聚合函数:将某些同类型的数据聚合到一起,做一些统计分析的事情
max() min() sum() avg() count()
1.1 count() 进行数据统计
统计一下:满足SQL查询语句的数据,总共有多少条
//统计一下,user_info表中,总共有多少条数据select count(*) from user_info;//统计一下,user_info表中,姓名是 李XXX 的数据,总结有多少条select count(*) from user_info where user_name like concat('李','%');
1.1.1 count()的用法
count(*)—常用
count(某一个字段)
count(某一个字段) 会针对某一个字段,做非NULL排除
//统计user_info表中,姓名是 李XXX 的数据,并且他的描述是非NULL的数据,总共有多少条
select count(user_desc) from user_info where user_name like concat('李','%');
//统计user_info表中,姓名是 李XXX 的数据,并且他的user_name是非NULL的数据,而且针对名字做去重后,总共有多少条数据
select count(distinct user_name) from user_info where user_name like concat('李','%');
count()通常都是配合limit关键字,做分页处理!!!
分页:
1、先查询满足条件,总共有多少条数据 count(),用来确定:可以分为多少页
2、再使用limit关键字,进行分页查询数据
1.2 sum() 求某一个列中数字的和
sum()函数,只能用于数字类型的列
该函数没有sum(*)的说法,只有sun(某一个字段)
//查询所有学生的总成绩
select sum(score) from user_info;
语法:
sum([ALL] 某一个字段) ALL是可以省略的,如果不省略,表示该列的数据,如果有NULL,也做求和处理
sum([distinct] 某一个字段) distinct也是可以省略的,如果不省略,表示该列的数据,在求和时,需要先去重
1.3 avg() 求平均值
avg() 函数,同样没有avg(*) 的说法
它也只有avg(某一个字段)
语法:
avg([all] 某一个字段) all可以省略,省不省略,效果都是针对非NULL数据,进行求平均值
//求所有学生成绩中,非NULL数据的平均值
select avg(all score) from user_info;
//如果需要统计包含NULL值的平均值,就需要借助ifnull(字段,'默认值')
select avg(all ifnull(score,'0')) from user_info;
等同于
select SUM(score) / count(*) from user_info;
1.4 max()求最大值
求某一列中,某个字段中值的最大值
比如:求所有学生中,得分最高的分数
select max(score) from user_info;
1.5 min()求最小值
求某一列中,某个字段中值的最小值
比如:求所有学生中,得分最低的分数
//求所有考试学生中,得分最低的分数
select min(score) from user_info;
//求包含没考试的学生的最低分
select min(ifnull(score,'0')) as '最低分' from user_info;
二、group by (分组)
2.1 group by分组
分组:将数据按照 不同类型进行 分组处理 比如:每个班 的最高分,每个班的平均分 每个班的最低分
分组:使用的关键字 group by
分组可以根据某一个列进行分组,也可以根据某几列进行分组
分组,通常都是配合上述的聚合函数来进行使用
例如:
1、根据班级分组
2、先根据班级分组,然后再根据性别分组
语法:
group by 列的列表
Eg:
按照系分组统计:每个系中数学成绩的最高分,最低分,平均分
select deptment,max(math_score) as '最高数学成绩',min(ifnull(math_score,'0')) as '最低数学成绩',avg(ifnull(math_score,'0')) as '数学成绩的平均分' from t_student group by deptment;
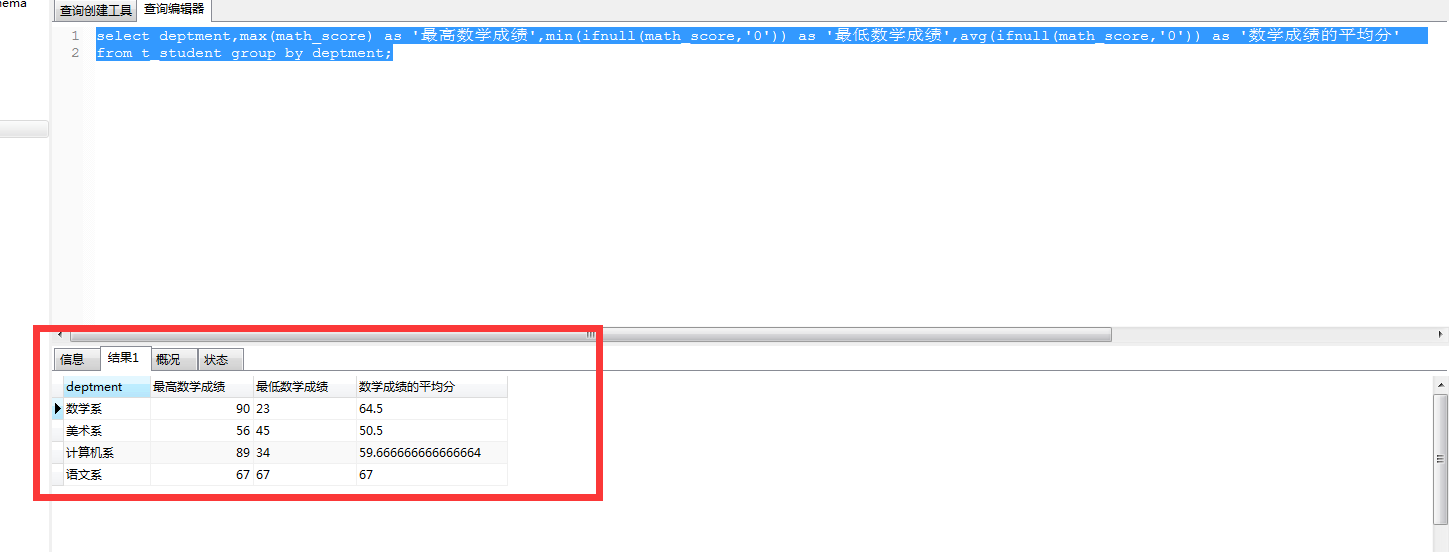
请记住:一旦用了group by ,那么能够放在select 后的字段,一定要是group by后的字段,或者是某一个跟统计相关的字段
分组之后,再分组:
select deptment,gender,max(math_score) as '最高数学成绩',min(ifnull(math_score,'0')) as '最低数学成绩',avg(ifnull(math_score,'0')) as '数学成绩的平均分' ,sum(math_score) as '数学总成绩' from t_student group by deptment,gender;

2.2 having筛选
having() 是针对 聚合过后的数据,再次进行过滤使用
它的位置:一定要定义在group by语句之后
//求数学平均成绩 >= 60分的,所有系
select deptment,gender,max(math_score) as '最高数学成绩',min(ifnull(math_score,'0')) as '最低数学成绩',avg(ifnull(math_score,'0')) as '数学成绩的平均分' ,
sum(math_score) as '数学总成绩'
from t_student group by deptment,gender having avg(ifnull(math_score,'0')) >= 60;
三、索引
索引:就是给表中的某些常用列,定义一种快速检索数据的方式
添加索引,是数据库中针对SQL调优的最佳方案
3.1 创建普通索引的方式
普通索引 : 字段中,可以存放重复值
语法:
//建表时,添加索引
create table t_teacher(id int primary key,teacher_name varchar(20),age int,gender char(2),key idx_teacher_name (teacher_name) using btree);
//表已存在,添加索引(使用最多)
alter table t_teacher add index idx_teacher_name (teacher_name) using btree;
add index 索引的名字 (需要添加索引的列) using 索引类型;
3.2 创建唯一索引的方式
唯一索引: 字段中,不能存放重复值
语法:
//建表时,添加索引
create table t_teacher(id int primary key,teacher_name varchar(20),age int,gender char(2),unique key uk_teacher_name (teacher_name) using btree);
//表已存在,添加索引(使用最多)
alter table t_teacher add unique index uk_teacher_name (teacher_name) using btree;
3.3 索引的使用
explain select id, student_name from t_student;
1、在查询语句中的select 后 使用索引字段,切记:不要添加非索引字段,加了就会导致索引失效
2、在查询语句中尽量不要使用 > < >= != <> 这些符号
3、在查询语句中like 后不要直接跟随 %,例如:%张 %三% 要用就用:张%
4、组合索引中,没有按照索引类的顺序进行查询,索引也会失效
5、or 也会导致索引失效
6、索引列是个字符串,如果不加’’ 也会导致索引失效
7、使用select * 可能会导致索引失效
3.4 索引的分类
Btree(默认)
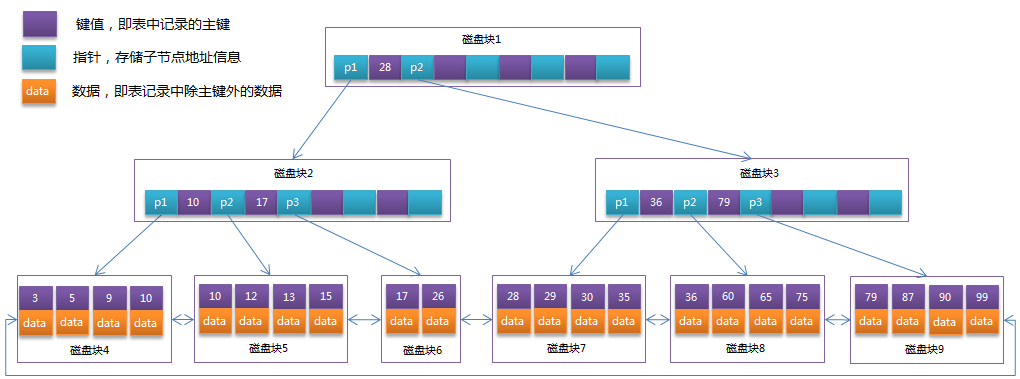
Hash(不推荐)
3.5 explain SQL的执行计划(面试题)
说:问你的一条SQL语句,你如何知道这条SQL语句,有没有使用到索引?
回答:我们可以使用explain 查看SQL的执行计划,并且重点关注:type,possible_keys,key,rows 这几个属性
3.5.1 type
主要用于描述 该语句是哪种类型的查询语句
**
从最好到最差依次是:
system > const > eq_ref > ref > range 代表SQL语句中使用到范围查询 > index > all
system 代表表中只有1条数据
const 代表SQL语句使用到了 主键或者唯一索引
eq_ref 代表SQL语句使用到了 主键或者唯一索引(唯一性索引扫描)
ref 代表SQL语句使用到了 普通索引(非唯一性索引扫描)
range 代表SQL语句中使用到范围查询
index 代表SQL语句只查询了索引数据,没有查询其他数据,eg: select id from 表;
all 代表 全表检索 (效率最差)
all一般如果查询较差,都需要进行索引优化
3.5.2 possible_keys
3.5.3 key
3.5.4 rows
代表此次SQL查询,受影响的行数!
四、子查询(了解)
可以通过程序的代码,去做优化!
子查询: SQL查询语句中,包含一个或多个 子查询
子查询:可以放置在 select 语句,from 语句,where 语句,group by 语句,order by 语句,having语句后
当然用的最多的地方:select 语句 ,where 语句
select deptment,student_name,gender,age,english_score from t_student where english_score >= (select avg(english_score) from t_student);
五、多表的建立(重点)
我们根据数据设计的三范式,就需要将不能直接相关的列,定义到其他表中去。
这样就形成了:多表关系
5.1 表和表之间有哪些关系
数据表中一般描述关系:
1、继承
2、关联关系(1-1,1-n,n-n)
1-1 中国大陆范围内,明面上的,合法的:夫妻关系
1-n 当前社会场景下: 血脉关系下的 父母 - 子女
n-n 当下大学系统的,学生选课;玩家和游戏;
1-1 是1-n 的特例
记住:如果范围变化,或者环境变化,我们的关系也有可能会发生变化
**
5.2 外键
表和表之间的关系靠外键进行维护,外键 和 外键约束是不同的
外键就是建立一个字段,用来描述数据之间的关系
5.3 外键约束
外键约束:给外键字段添加一个约束条件,让引用表的数据,在修改和删除时,需要针对 外键所在的表进行 引用判断
当然:你们在学习时,可以添加外键约束,但是在具体的生产环境下:一定要把外键约束取消
原因是:外键约束给你添加了级联操作,有的时候你的程序也控制他们之间的关系,到时就会出现:你都不知道你哪儿出错了!
例外,从性能上考虑,也请将该外键约束删除
5.4 建立一个1-1的表
5.4.1 靠外键建立关系:
举例:夫妻关系
create table husband_info (id bigint primary key auto_increment,
husband_name varchar(20),
gender char(4),
fk_wife_id bigint
);
create table wife_info (id bigint primary key auto_increment,
wife_name varchar(20),
gender char(4));
在已经存在的表的基础上,添加外键约束:
alter table husband_info add foreign key (fk_wife_id) references wife_info(id);
5.4.2 靠外键,以及约束建立关系:
create table husband_info (id bigint primary key auto_increment,
husband_name varchar(20),
gender char(4),
fk_wife_id bigint,
foreign key (fk_wife_id) references wife_info (id)
);
//foreign key (fk_wife_id) references wife_info (id) 表示在fk_wife_id 字段上,添加一个外键约束,数据引用至wife_info 表的id字段
create table wife_info (id bigint primary key auto_increment,
wife_name varchar(20),
gender char(4));
5.5 建立一个1-n的表
1-n的建表方式:是在n的一方,给1的一方添加一个外键即可
举例: 明星1 - 电影n
create table star_info (id bigint primary key auto_increment,
star_name varchar(20)
);
create table movie_info (id bigint primary key auto_increment,
movie_number varchar(20),
movie_desc varchar(120),
fk_star_id bigint
);
`
如果要添加约束,就执行下面的语句:
alter table movie_info add foreign key(fk_star_id) references star_info (id);
5.6 n-n的建表方式
玩家n - 游戏n之间的关系
1个玩家,可以玩多个游戏
1个游戏,可以有多个玩家
此时在创建关系时,就需要使用第3张表来帮助维护关系
create table player_info(
id bigint primary key auto_increment,
player_name varchar(20)
);
create table game_info(
id bigint primary key auto_increment,
game_name varchar(20)
);
create table player_game (
id bigint primary key auto_increment,
fk_player_id bigint,
fk_game_id bigint );
如果要添加约束,就执行下面的语句:
alter table player_game add foreign key(fk_player_id) references player_info (id);
alter table player_game add foreign key(fk_game_id) references game_info (id);

若有收获,就点个赞吧
0 人点赞
