一、集合简介
Java Collections Framework (JCF) ,集合: 是一个装东西的容器
之前我们已经学过一种集合(数组),只是数组有一定的缺陷:长度不可改变,内容固定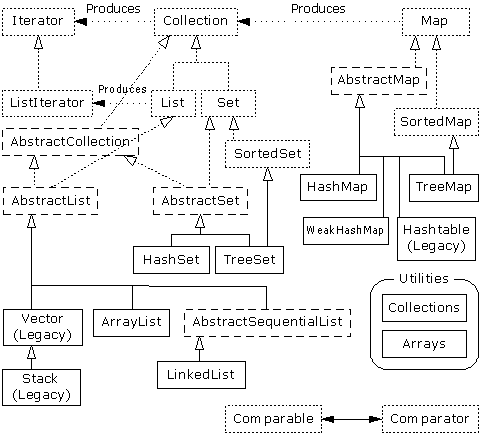
Java的所有集合,都在java.util包下
如果按照3个方法:允许不允许放置重复元素,集合中元素中元素是否有序,是否允许放置null元素,我们可以将集合体系划分为2大体系
Collection (List与Set)
Map
1.1 List列表
特点:集合中元素可以重复,而且元素的排序是按照一定的顺序进行排列的
1.2 Set集
特点:集合中元素不能重复,而且元素的排序是无序的
1.3 Map(映射集)
特点:集合中的所有元素都是按照 key - value 的结构进行存放,而且key不允许重复,value可以重复
二、Collection集合
在集合框架中,集合(Collection)接口位于Set接口和List接口的最顶层,是Set接口和List接口的父接口。
Collection接口中的主要方法: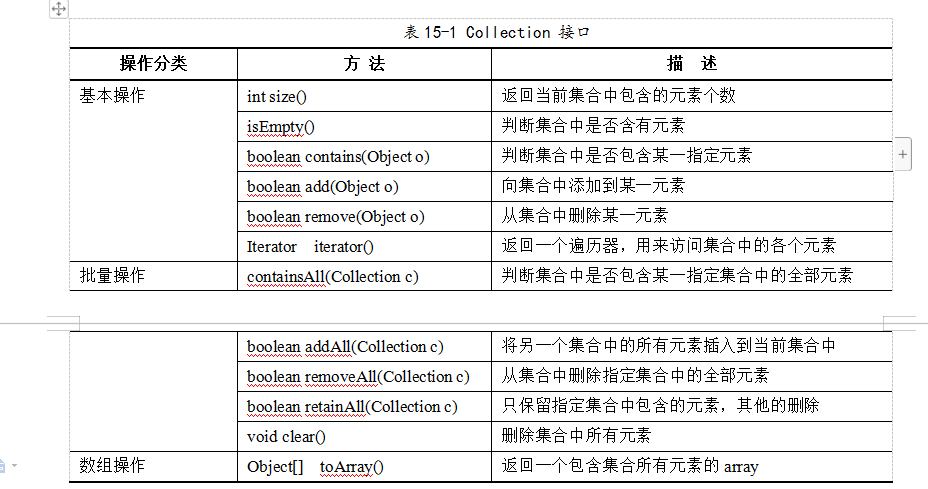
Iterator接口中的主要方法:
2.1 List集合
List接口继承自Collection接口,它的子类一定都提供了所有Collection接口中的所有方法的实现。
List集合的特点:
1、List中的元素是有顺序的。
2、List通常允许重复元素。
3、List的实现类通常支持null元素。
4、可以通过索引(下标)访问List对象容器中的元素。
List接口的扩展的方法:
2.1.1 ArrayList集合
ArrayList 是List的实现类,它实现了List中的所有抽象方法。它在存储数据时,采用的数据结构:数组结构
通过代码分析底层就是数组结构!
底层代码: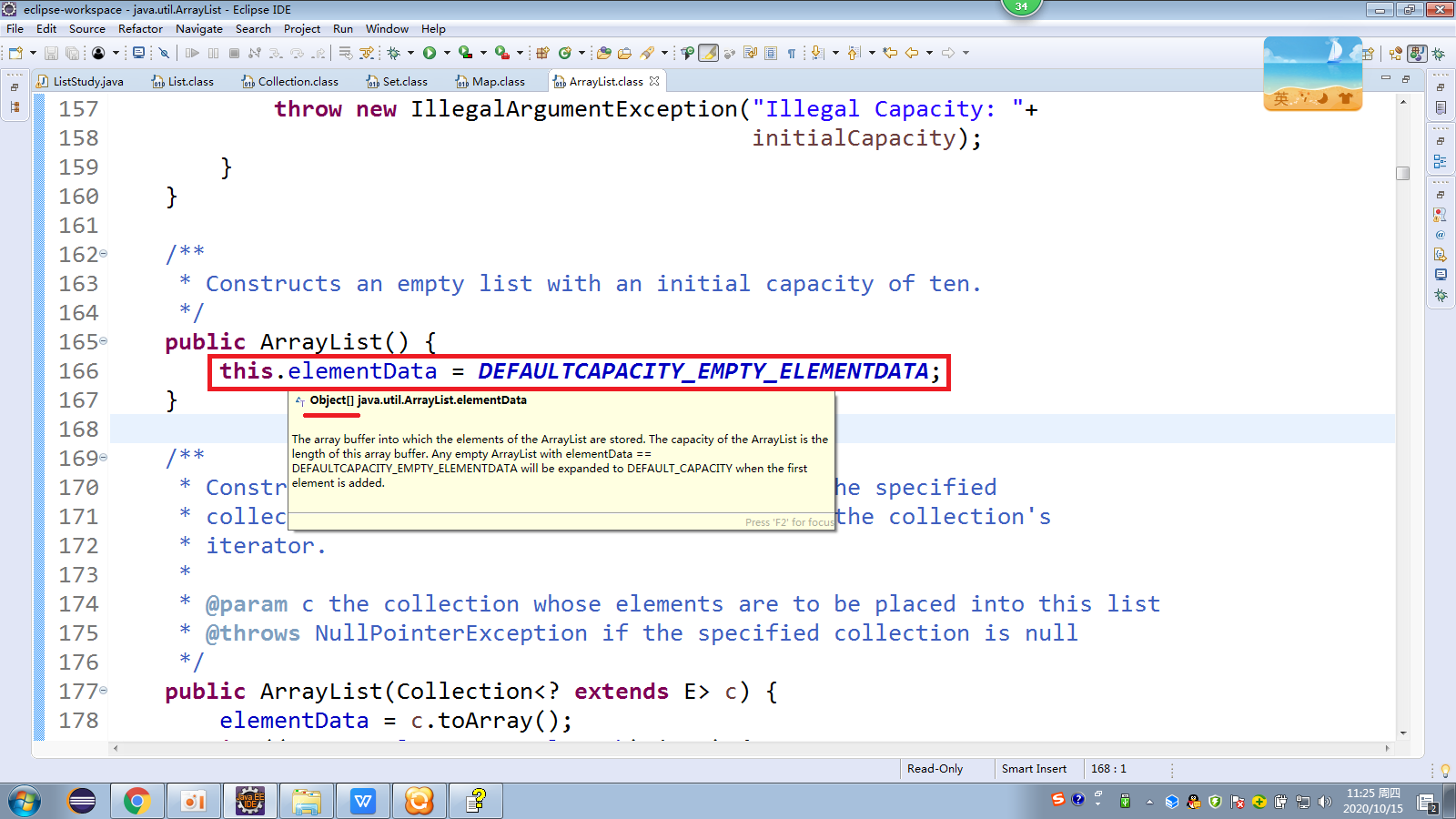
ArrayList的用法
直接new ArrayList();
List list = new ArrayList();
ArrayList的常用API
public class ListStudy {public static void main(String[] args) {// TODO Auto-generated method stub// study01();study02();}private static void study02() {// TODO Auto-generated method stub//指定集合中只能存放 String类型的元素List<String> data = new ArrayList<String>();data.add("隔壁老王");data.add("隔壁老张");data.add("隔壁老宋");data.add(null);//判断集合中是否存在某一个元素System.out.println(data.contains("隔壁老王"));//移除某一个元素System.out.println(data.remove("隔壁老王"));List<StudentBean> stus = new ArrayList<StudentBean>();stus.add(new StudentBean("xiaoz",98,34,12));// stus.add("隔壁小蓉");}private static void study01() {// TODO Auto-generated method stub// 创建一个ArrayList()List data = new ArrayList();// 操作集合String str = "隔壁老张";// 向集合中添加元素data.add(str);StudentBean stu = new StudentBean("刘亦菲", 99, 89, 90);data.add(stu);// 允许放置重复元素data.add(str);data.add(null);// 获取(单个单个)// System.out.println(data.get(0));// System.out.println(data.get(1));// System.out.println(data.get(2));// System.out.println(data.get(3));// 遍历(1) for 结合下标// 元素的个数// int size = data.size();// for(int i = 0; i < size; i ++) {//// System.out.println(data.get(i));// }// 遍历(2) foreach// for (Object object : data) {// if(object instanceof String) {// String string = (String)object;// System.out.println(string);// }else if(object instanceof StudentBean) {// StudentBean student = (StudentBean)object;// System.out.println(student);// }else {// System.out.println(object);// }// }// 遍历(3) 迭代器(一种专门用来遍历集合的接口)// Iterator iterator = data.iterator();// // 判断是否有下一个元素// while (iterator.hasNext()) {//// Object object = iterator.next();// //判断元素的类型// if (object instanceof String) {// String string = (String) object;// System.out.println(string);// } else if (object instanceof StudentBean) {// StudentBean student = (StudentBean) object;// System.out.println(student);// } else {// System.out.println(object);// }//// //迭代器的主要作用:除了遍历集合之外,还可以对元素进行操作// iterator.remove();// }//// 根据下标删除元素data.remove(3);// 根据元素来完成删除(第1个)data.remove(str);// 输出元素的个数System.out.println(data.size());}}
ArrayList底层细节
new ArrayList() 初始数组容量是0,然后调用add(E e)会自动扩容为 10
当超过10以后,将会发生进一步扩容,扩容是:1.5倍 依次类推……
扩容原理:使用数组的复制原理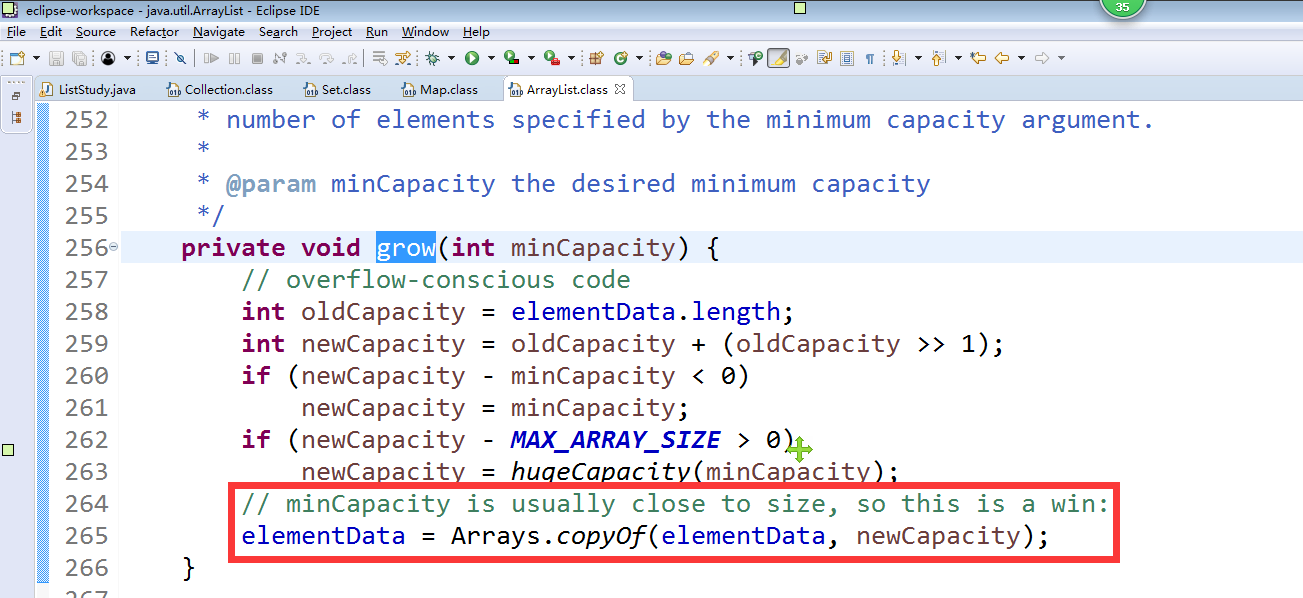
2.1.2 LinkedList
ArrayList 底层是数组,LinkedList的底层是链表(双向链表)
LinkedList 扩展的API

LinkedList不支持快速随机访问,如果要访问LinkedList中第n个元素,必须从头开始查找,然后跳过前面的n-1个元素。并且,虽然LinkedList也提供了一个get()方法,可以根据指定的索引来获取对应的元素,但是正因为它不支持快速随机访问,所以效率比较低下。
LinkedList的常用API
/*** 链表列表* @author Administrator**/public class LinkedListStudy {public static void main(String[] args) {// TODO Auto-generated method stubLinkedList<String> data = new LinkedList<String>();data.add("a");data.add("b");data.add("c");data.add("d");data.add("e");data.add(null);//返回集合中元素的个数System.out.println(data.size());//获得最初,以及最后的一个元素System.out.println(data.getFirst());System.out.println(data.getLast());//根据下标返回元素(但是它需要先从第一个元素开始查找)System.out.println(data.get(3));//向第1个元素前,进行添加内容data.addFirst("a");//向最后一个元素,进行添加内容data.addLast("f");//遍历,如同Arraylist一样(for foreach 迭代器)Iterator<String> iterator = data.iterator();//由于JDK1.5以后,LinkedList采用了Queue的数据结构,所以遍历时,它从First开始遍历while(iterator.hasNext()) {String str = iterator.next();System.out.println(str);iterator.remove();}//也可以单个单个的移除data.remove("f");}}
2.1.3 Vector,LinkedList和ArrayList 的区别
- Arraylist 的底层是数组,LinkedList的底层是链表
ArrayList采用数组的方式存储对象,这种方式将对象放在连续的位置中,它有一个很大的缺点就是对它们进行删除或插入操作的时候非常麻烦。例如,如果我们要删除列表中某个元素,那么这个元素之后的其它元素都必须向前挪动。而插入元素的时候,在插入位置之后的所有元素都必须向后挪动。
LinkedList不支持快速随机访问,如果要访问LinkedList中第n个元素,必须从头开始查找,然后跳过前面的n-1个元素。所以访问LinkedList元素时,性能会比较低下。因此,如果列表需要快速存取,但不经常进行元素的插入和删除操作,那么选择ArrayList会好一些;如果需要对列表进行频繁的插入和删除操作,那么就应该选择LinkedList。
Vector 由于使用synchronized,做到了线程同步。但是它的效率低下
Arraylist 没有添加synchronized,所以效率相对较高,但是从数据安全性上来讲,比Vector 低下一些
总结:
Arrylist:底层是数组,适合查询,未使用synchronized,效率高数据安全性低
LinkedList:底层是链表(双向联表),适合增删
Vector:类似于Arraylist,使用了synchronized,同步但效率低

若有收获,就点个赞吧
0 人点赞
