一、Docker
1.1 docker中的镜像安装与命令
docker images
查看当前系统中有哪些镜像
docker search 关键字
搜索相关的镜像(第三方)
docker pull 镜像名字
通过镜像名字下载到本地docker仓库
设置镜像加速
登录阿里云->点击控制台
在控制台搜索栏搜索”容器镜像服务“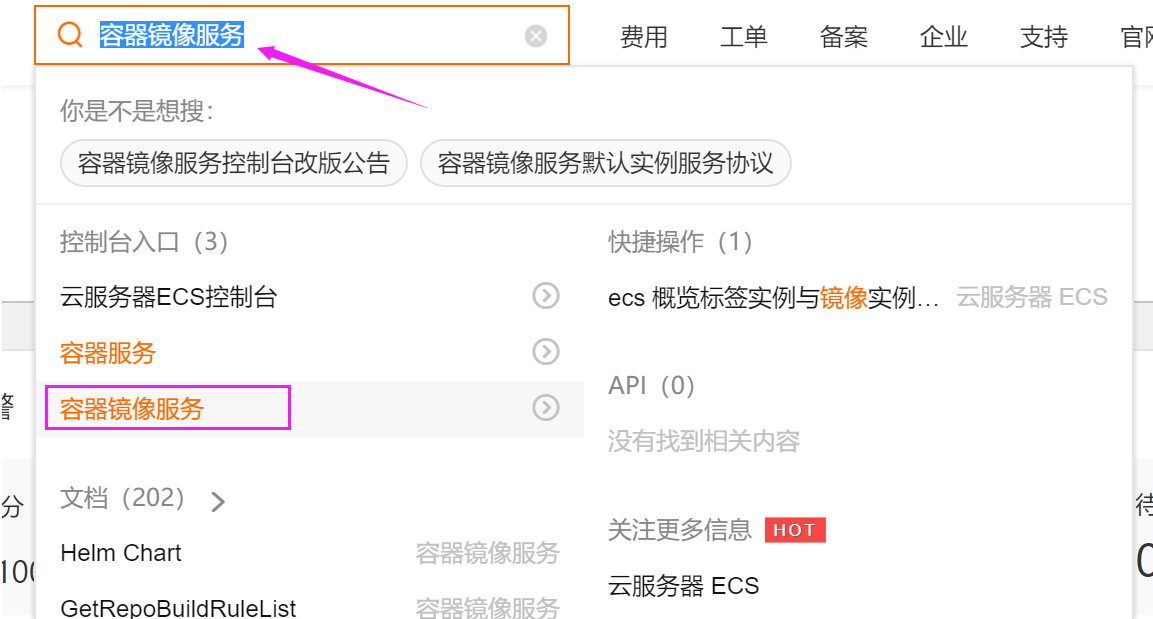
选择”镜像加速器”选项,获取centos下配置方式
切换到root用户,在etc下创建docker目录并创建daemon.json文件
mkdir /etc/docker
vi /etc/docker/daemon.json
并在daemon.json文件中配置加速器信息
{
"registry-mirrors": ["https://zypktutb.mirror.aliyuncs.com"]
}
保存退出,重启docker
sudo systemctl daemon-reload
sudo systemctl restart docker
镜像离线导入导出
导入
docker load -i xxx.tar
导出
docker save -o xxx.tar 镜像名:版本
删除镜像
docker rmi -f 镜像id
1.2 利用docker实现nginx+Tomcat集群
nginx:是一种反向代理的服务器
正向代理:常见的正常代理VPN,特点是客户知道自己要访问的网站、网址是哪一个
反向代理:客户并不知道自己要访问哪个服务器,只知道要访问的网址,具体由哪一个服务器处理,是由代理服务器代为转发请求
集群:多个服务器,优点在于可以快速扩展服务器的性能
特点:每一个服务器部署同一个项目
实现步骤
1、在个人主目录下创建nginx.conf文件,配置一下内容
#指定Nginx Worker进程运行用户以及用户组,默认由nobody账号运行
user root;
#指定Nginx要开启的进程数。每个Nginx进程平均耗费10M~12M内存。建议指定和CPU的数量一致即可
worker_processes 1;
#error_log是个主模块指令,用来定义全局错误日志文件。日志输出级别有debug、info、notice、warn、error、crit可供选择,其中,debug输出日志最为最详细,而crit输出日志最少
error_log /var/log/nginx/error.log warn;
#用来指定进程pid的存储文件位置
pid /var/run/nginx.pid;
#events事件指令是设定Nginx的工作模式及连接数上限
events {
#用于定义Nginx每个进程的最大连接数,默认是1024
worker_connections 1024;
}
#HTTP服务器配置
http {
#主机配置
server {
listen 80; #监听80端口
#URL匹配配置
location / {
proxy_pass http://blance;
}
}
#upstream 通过server指令指定后端服务器的IP地址和端口,同时还可以设定每个后端服务器在负载均衡调度中的状态
upstream blance{
server 192.168.86.128:8081;
server 192.168.86.128:8082;
server 192.168.86.128:8083;
}
#实现对配置文件所包含的文件的设定,可以减少主配置文件的复杂度
include /etc/nginx/mime.types;
#设定默认类型为二进制流,也就是当文件类型未定义时使用这种方式,例如在没有配置PHP环境时,Nginx是不予解析的,此时,用浏览器访问PHP文件就会出现下载窗口
default_type application/octet-stream;
#用于指定Nginx日志的输出格式。main为此日志输出格式的名称
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
#用于开启高效文件传输模式
sendfile on;
#tcp_nopush on;
#设置客户端连接保持活动的超时时间。在超过这个时间之后,服务器会关闭该连接
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
2、准备项目(war)
创建web项目
创建首页(首页内容自定义)
打成war包
将war上传到Linux用户主目录下
3、利用docker中Tomcat镜像创建服务器1
docker run -d -p 8081:8080 --name tomcat1 tomcat
run 新建并运行容器
-d daemon后台运行
-p 指定容器运行时的端口号 8081:8080 后一个端口是程序的默认端口,前一个端口就是它运行时端口(Tomcat要监听的端口)
—name 指定容器的名字
tomcat1 容器的名字
tomcat 镜像的名字
4、将第二步得到的war包部署到服务器1中
docker cp abc.war tomcat1:/usr/local/tomcat/webapps
5、在虚拟机中通过浏览器访问项目
localhost:8081/abc
6、开启对应的端口8081
firewall-cmd --zone=public --add-port=8081/tcp --permanent
systemctl restart firewalld service
7、重复2到6步,再启动两个tomcat
8、创建3个Tomcat的服务器
9、创建nginx容器**
docker run -d -p 80:80 -v /home/ly/nginx.conf:/etc/nginx/nginx.conf --name nginx1 nginx
-v 挂载,程序员可以通过该选项将自己的配置文件用来替换容器原有的配置文件
/home/ly/nginx.conf 自己的配置文件路径
/etc/nginx/nginx.conf nginx默认配置文件路径
docker停止/启动nginx
docker stop nginx
docker start nginx
10、在Windows上通过浏览器请求80端口访问项目
http://192.168.86.128/abc/
注:此处的ip为nginx服务器所在的服务器ip;ip后不指定端口号默认就是访问的80端口
**
1.3 nginx负载均衡策略
负载均衡:让每个服务器处理请求的次数、压力都差不多
nginx常见的负载均衡策略:
- 轮询 默认
- 权重 weight
- 通过ip划分 ip_hash
- 响应时间 第三方 fair
- 通过url方式 第三方(微服务) url_hash
案例:给tomcat1设置权重为2
修改nginx.conf文件:
upstream blance{
server 192.168.86.128:8081;
server 192.168.86.128:8082;
server 192.168.86.128:8083;
}
重启nginx,进行测试,如果达不到想要的效果重新创建一个nginx容器,或者换成火狐浏览器试试
1.4 docker其他常见命令
docker ps 查看正在运行的容器
docker ps -a 查看所有容器,包括没运行的
docker stop 容器id 关闭运行的容器
docker start 容器id 启动容器
docker restart 容器id 重启运行状态的容器
docker rm 容器id 删除容器
1.5 部署SpringBoot项目
1、将springboot项目打成jar包
2、将jar包上传到Linux
3、执行 java -jar 包名部署运行项目
此种方式为前台运行,只要客户端管理项目就会停止,如果想要项目不停止则需要在后台运行项目,命令如下
nohup java -jar xxx.jar > nohup.out 2>&1 &
- 0 表示stdin (standard input)
- 1 表示stdout (standard output)
- 2 表示stderr (standard error)
以上命令解释:
2>&1是将标准错误(2)重定向到标准输出(&1),标准输出(&1)再被重定向输入到nohup.out文件中。
& : 指在后台运行
需要停止已开启的项目:
ps aux | greap xxx.jar 查看项目的pid
kill -9 进程id
1.6 显示vi编辑器行号
1、cd
2、vi .vimrc vi的配置文件
3、在文件中输入以下内容
set nu
4、保存退出
5、输入 source .vimrc 让刚才的配置生效
二、Redis
2.1 Redis简介
Redis中文网:http://www.redis.cn/
Redis是一种NoSql(NoSQL,泛指非关系型的数据库)数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。NoSQL有如下优点:易扩展,NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间也在架构的层面上带来了可扩展的能力。大数据量,高性能,NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
1)Redis
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
·Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
·Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
·Redis支持数据的备份,即master-slave模式的数据备份。
2)Redis 优势
·性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
·丰富的数据类型 – Redis支持二进制案例的 String, List, Hash, Set 及 Ordered Set 数据类型操作。
·原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
·丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
3)为什么要用Redis
3.1) Redis都可以干什么事儿
·缓存,毫无疑问这是Redis当今最为人熟知的使用场景。再提升服务器性能方面非常有效;
·排行榜,如果使用传统的关系型数据库来做这个事儿,非常的麻烦,而利用Redis的SortSet数据结构能够非常方便搞定;
·计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
·好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能;
·简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
·Session共享,以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
3.2) Redis不能干什么事儿
Redis感觉能干的事情特别多,但它不是万能的,合适的地方用它事半功倍。如果滥用可能导致系统的不稳定、成本增高等问题。
比如,用Redis去保存用户的基本信息,虽然它能够支持持久化,但是它的持久化方案并不能保证数据绝对的落地,并且还可能带来Redis性能下降,因为持久化太过频繁会增大Redis服务的压力。
简单总结就是数据量太大、数据访问频率非常低的业务都不适合使用Redis,数据太大会增加成本,访问频率太低,保存在内存中纯属浪费资源。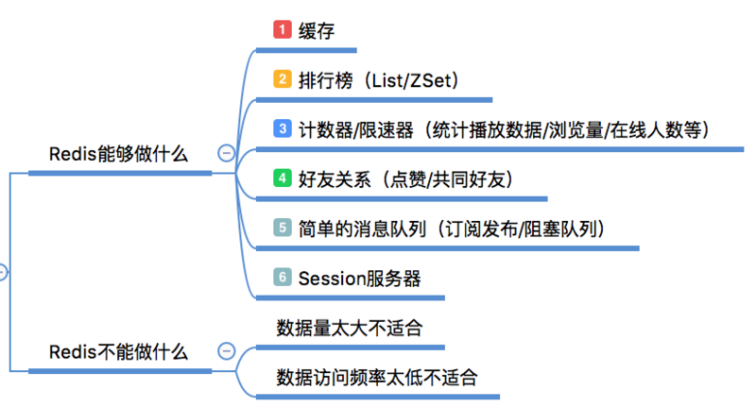
3.3) 为什么要使用Redis
上面说了Redis的一些使用场景,那么这些场景的解决方案也有很多其它选择,比如缓存可以用Memcache,Session共享还能用MySql来实现,消息队列可以用RabbitMQ,我们为什么一定要用Redis呢?
速度快,完全基于内存,使用C语言实现,网络层使用epoll解决高并发问题,单线程模型避免了不必要的上下文切换及竞争条件;
注意:单线程仅仅是说在网络请求这一模块上用一个请求处理客户端的请求,像持久化它就会重开一个线程/进程去进行处理
丰富的数据类型,Redis有8种数据类型,当然常用的主要是 String、Hash、List、Set、 SortSet 这5种类型,他们都是基于键值的方式组织数据。每一种数据类型提供了非常丰富的操作命令,可以满足绝大部分需求,如果有特殊需求还能自己通过 lua 脚本自己创建新的命令(具备原子性);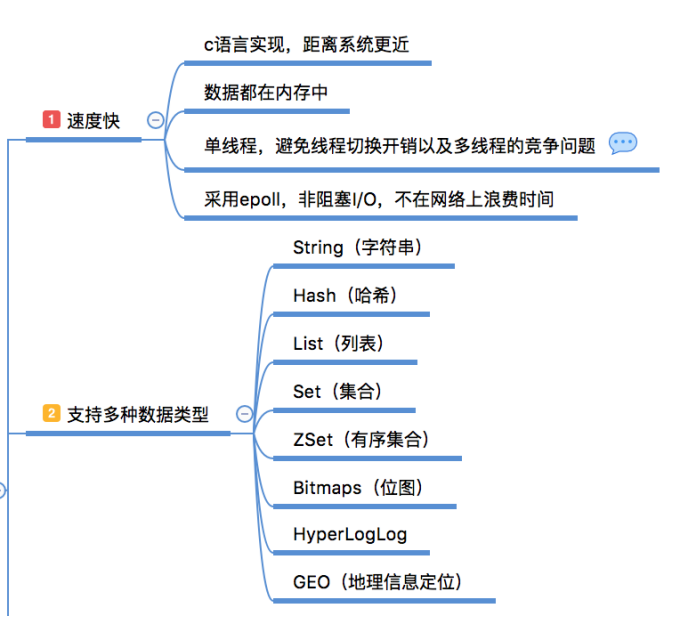
除了提供的丰富的数据类型,Redis还提供了像慢查询分析、性能测试、Pipeline、事务、Lua自定义命令、Bitmaps、HyperLogLog、发布/订阅、Geo等个性化功能。
Redis的代码开源在GitHub,代码非常简单优雅;它的编译安装也是非常的简单,没有任何的系统依赖;有非常活跃的社区,各种客户端的语言支持也是非常完善。另外它还支持事务(没用过)、持久化、主从复制让高可用、分布式成为可能。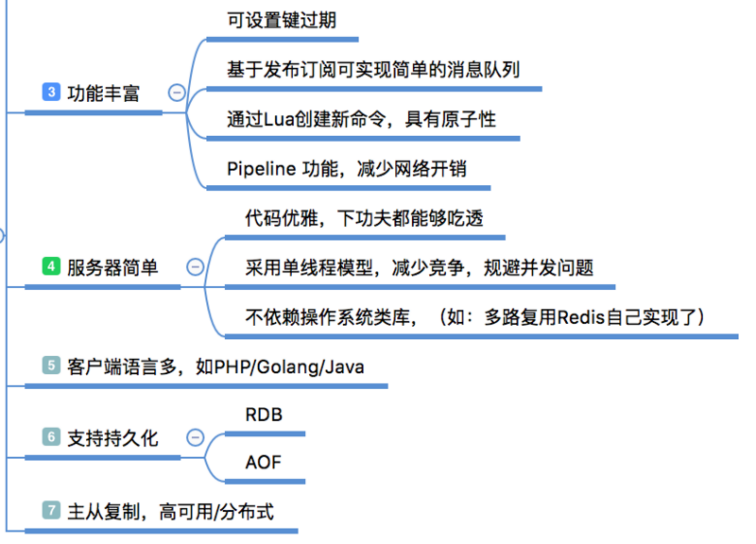
2.2 Windows下安装并使用Redis
下载地址:https://github.com/MSOpenTech/redis/releases
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择
2.2.1 解压Redis-x64-3.2.100.rar压缩包到D盘下并重命名文件夹为redis
2.2.2 在当前目录运行cmd
执行代码:redis-server.exe redis.windows.conf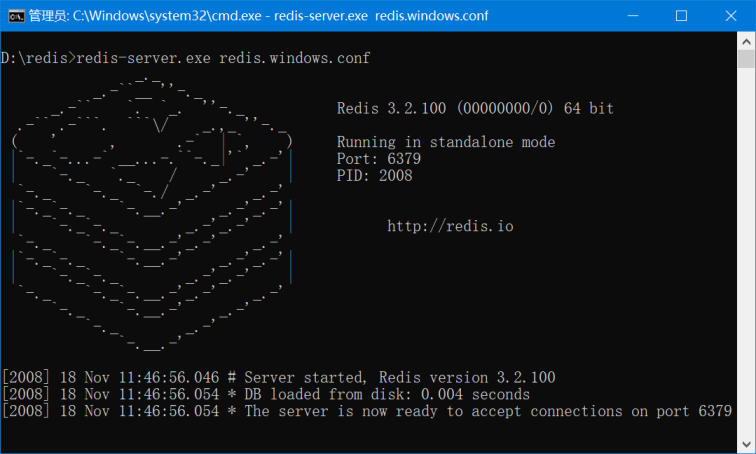
2.2.3 这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。
切换到 redis 目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
设置键值对:
set myKey abc
取出键值对:
get myKey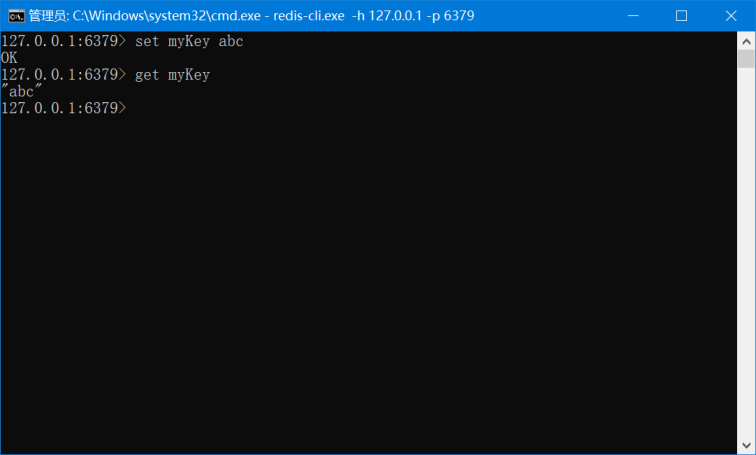
2.3 Redis常用命令
1、Redis 客户端的基本语法为:
$ redis-cli
2、在远程服务上执行命令
如果需要在远程 redis 服务上执行命令,同样我们使用的也是 redis-cli 命令。
语法
$ redis-cli -h host -p port -a password
实例:
以下实例演示了如何连接到主机为 127.0.0.1,端口为 6379 ,密码为 mypass 的 redis 服务上。
$redis-cli -h 127.0.0.1 -p 6379 -a “mypass”
redis 127.0.0.1:6379>
3、Redis 键(key)
Redis 键命令用于管理 redis 的键。
语法
Redis 键命令的基本语法如下:
redis 127.0.0.1:6379> COMMAND KEY_NAME
实例
redis 127.0.0.1:6379> SET myKey redis
OK
redis 127.0.0.1:6379> GET myKey
1
redis 127.0.0.1:6379> DEL myKey
(integer) 1
在以上实例中 DEL 是一个命令, myKey 是一个键。 如果键被删除成功,命令执行后输出 (integer) 1,否则将输出 (integer) 0
下表给出了与 Redis 键相关的基本命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DEL key | 该命令用于在 key 存在时删除 key |
| 2 | DUMP key | 序列化给定 key ,并返回被序列化的值 |
| 3 | EXISTS key | 检查给定 key 是否存在 |
| 4 | EXPIRE key seconds | 为给定 key 设置过期时间,以秒为单位 |
| 5 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式( pattern)的 key |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
| 16 | TYPE key | 返回 key 所储存的值的类型 |
常见指令
keys *
查看当前数据库中所有的key
flushdb
删除所有的key
set
设置key和value 向数据库中写入数据
get
通过key获取数据
del
通过key删除数据
exists
判断key是否存在
expire
设置key的过期时间,单位秒
ttl
获取key剩余的过期时间
2.4 Redis常见数据类型
2.4.1 String(字符串)
string 是 redis 最基本的类型,一个 key 对应一个 value,是二进制安全的。
注意:string 类型的值最大能存储 12MB
**
下表列出了常用的 redis 字符串命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SET key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值 |
| 3 | GETRANGE key start end | 返回 key 中字符串值的子字符[start,end] |
| 4 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| 5 | GETBIT key offset | 对key 所储存的字符串值,获取指定偏移量上的位(bit) |
| 6 | MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| 7 | SETBIT key offset value | 对key所储存的字符串值,设置或清除指定偏移量上的位(bit) |
| 8 | SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| 9 | SETNX key value | 只有在 key 不存在时设置 key 的值 |
| 10 | SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| 11 | STRLEN key | 返回 key 所储存的字符串值的长度 |
| 12 | MSET key value [key value …] | 同时设置一个或多个 key-value 对 |
| 13 | MSETNX key value [key value …] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| 14 | PSETEX key milliseconds value | 这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位 |
| 15 | INCR key | 将 key 中储存的数字值增一 |
| 16 | INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| 17 | INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| 18 | DECR key | 将 key 中储存的数字值减一 |
| 19 | DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| 20 | APPEND key value | 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾 |
2.4.2 Hash(哈希)
Redis hash 是一个键值(key=>value)对集合。
格式:
HMSET hash名 key value [key value]
存储用的是HMSET命令
获取用的是 HGET 命令
每个 hash 可以存储很多对键值对,最多可以存储2^32 -1 键值对(40多亿)。
Redis hash 命令
下表列出了 redis hash 基本的相关命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | HDEL key field1 [field2] | 删除一个或多个哈希表字段 |
| 2 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| 3 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 4 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| 6 | HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment |
| 7 | HKEYS key | 获取所有哈希表中的字段 |
| 8 | HLEN key | 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2 ] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| 11 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| 12 | HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| 13 | HVALS key | 获取哈希表中所有值 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
2.4.3 列表(List)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
格式:
LPUSH list列表名 value1 [value2 …]
Redis 列表命令
下表列出了列表相关的基本命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | BLPOP key1 [key2 ] timeout | 移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 2 | BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 3 | BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 4 | LINDEX key index | 通过索引获取列表中的元素 |
| 5 | LINSERT key BEFORE\ | 在列表的元素前或者后插入元素 |
| 6 | LLEN key | 获取列表长度 |
| 7 | LPOP key | 移出并获取列表的第一个元素 |
| 8 | LINSERT key BEFORE|AFTER pivot value | 将一个或多个值插入到列表头部 |
| 9 | LPUSHX key value | 将一个值插入到已存在的列表头部 |
| 10 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 11 | LREM key count value | 移除列表元素 |
| 12 | LSET key index value | 通过索引设置列表元素的值 |
| 13 | LTRIM key start stop | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
| 14 | RPOP key | 移除列表的最后一个元素,返回值为移除的元素 |
| 15 | RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| 16 | RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| 17 | RPUSHX key value | 为已存在的列表添加值 |
2.4.4 集合(Set)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
格式
SADD Set名 value1 [value2 …]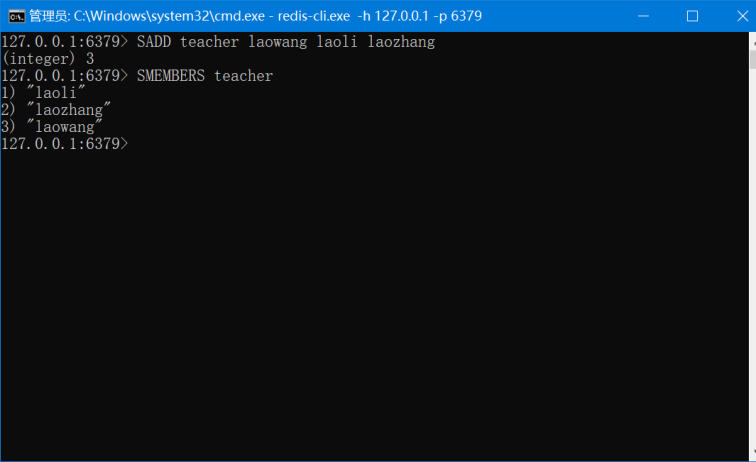
在以上实例中我们通过 SADD 命令向名为 setKey 的集合插入的三个元素。
Redis 集合命令
下表列出了 Redis 集合基本命令:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | _\_SADD** key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SCARD key | 获取集合的成员数 |
| 3 | _\_SDIFF** key1 [key2] | 返回给定所有集合的差集 |
| 4 | SDIFFSTORE destination key1 [key2] | 返回给定所有集合的差集并存储在 destination 中 |
| 5 | _\_SINTER** key1 [key2] | 返回给定所有集合的交集 |
| 6 | SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
| 7 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 8 | _\_SMEMBERS** key | 返回集合中的所有成员 |
| 9 | SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
| 10 | SPOP key | 移除并返回集合中的一个随机元素 |
| 11 | SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| 12 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 13 | SUNION key1 [key2] | 返回所有给定集合的并集 |
| 14 | SUNIONSTORE destination key1 [key2] | 所有给定集合的并集存储在 destination 集合中 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 |
2.4.5 有序集合(ZSet、sorted set)
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
格式:
ZADD key score member [score member]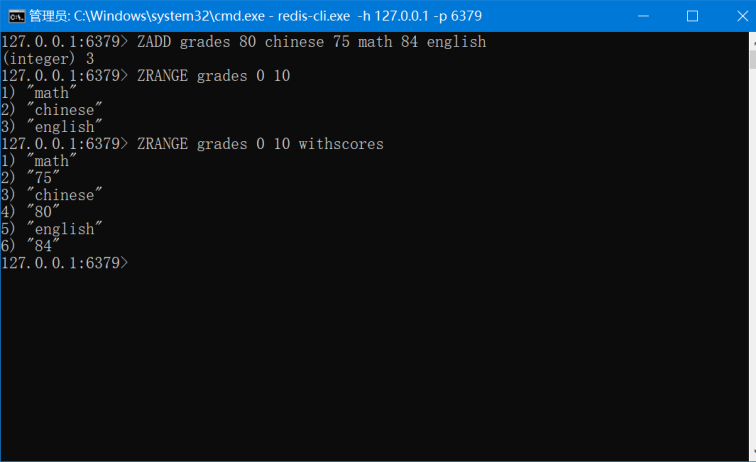
Redis 有序集合命令
下表列出了 redis 有序集合的基本命令:
| 序号 | 命名 | 描述 |
|---|---|---|
| 1 | _\_ZADD** key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | _\_ZCARD** key | 获取有序集合的成员数(length) |
| 3 | _\_ZCOUNT** key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | _\_ZINCRBY key increment member** | 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZINTERSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中ZINTERSTORE sumpoint **\_2** mid_test fin_test |
| 6 | _\_ZRANGE** key start stop [WITHSCORES] | 通过索引区间返回有序集合成指定区间内的成员 |
| 7 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员ZRANGEBYSCORE grades (1 100 1<score<=5ZRANGEBYSCORE grades (5 (100 5<score<100 |
| 8 | _\_ZRANK** key member | 返回有序集合中指定成员的索引 |
| 9 | _\_ZREM** key member [member …] | 移除有序集合中的一个或多个成员 |
| 10 | ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员ZREMRANGEBYRANK salary 0 1 # 移除下标 0 至 1 区间内的成员 |
| 11 | ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员ZREMRANGEBYSCORE salary 1500 3500 # 移除所有薪水在 1500 到 3500 内的员工 |
| 12 | ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到底ZREVRANGE salary 0 -1 WITHSCORES # 递减排列 |
| 13 | ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序ZREVRANK salary tom # 结果为0,tom 的工资最高 |
| 14 | _\_ZSCORE** key member | 返回有序集中,成员的分数值 |
| 15 | ZUNIONSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中ZUNIONSTORE salary 2 programmer manager WEIGHTS 1 3两个集合中scope的乘法系数 |

若有收获,就点个赞吧
0 人点赞
