一、ElasticSearch
1.1 简介
Elasticsearch 是一个分布式,高扩展的全文检索引擎,它可以近乎实时的存储数据、检索数据。一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎。当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.3 主要解决问题
检索相关数据
- 返回统计结果
-
1.4 ES工作原理
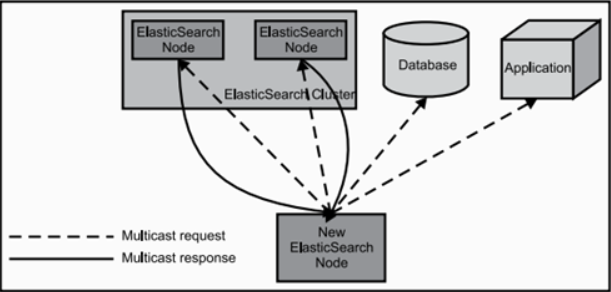
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
1.5 ES核心概念
1.5.1 Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
1.5.2 Node:节点
1.5.3 Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。1.5.4 Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。1.5.5 全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。1.6 ES数据架构的主要概念(与关系数据库Mysql对比)

(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET。1.7 ELK是什么?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。1.8 ES特点与优势
分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
- 实时分析的分布式搜索引擎。 分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
- 负载再平衡和路由在大多数情况下自动完成。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
- 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
二、倒排索引
2.1 正排索引
正排索引也称为”前向索引”,它是创建倒排索引的基础。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。
他适合根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
比如有几个文档及里面的内容,他正排索引构建的结果如下图:
优点:工作原理非常的简单。
缺点:检索效率太低,只能在一起简单的场景下使用。
2.2 倒排索引简介
根据字面意思可以知道他和正序索引是反的。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(文档要除去一些无用的词,比如‘的’这些,剩下的词就是单词(Term),每个Term都有自己的ID)。例如“文档1”经过分词,提取了3个单词,每个Term都会记录它所在在文档中的出现频率及出现位置。
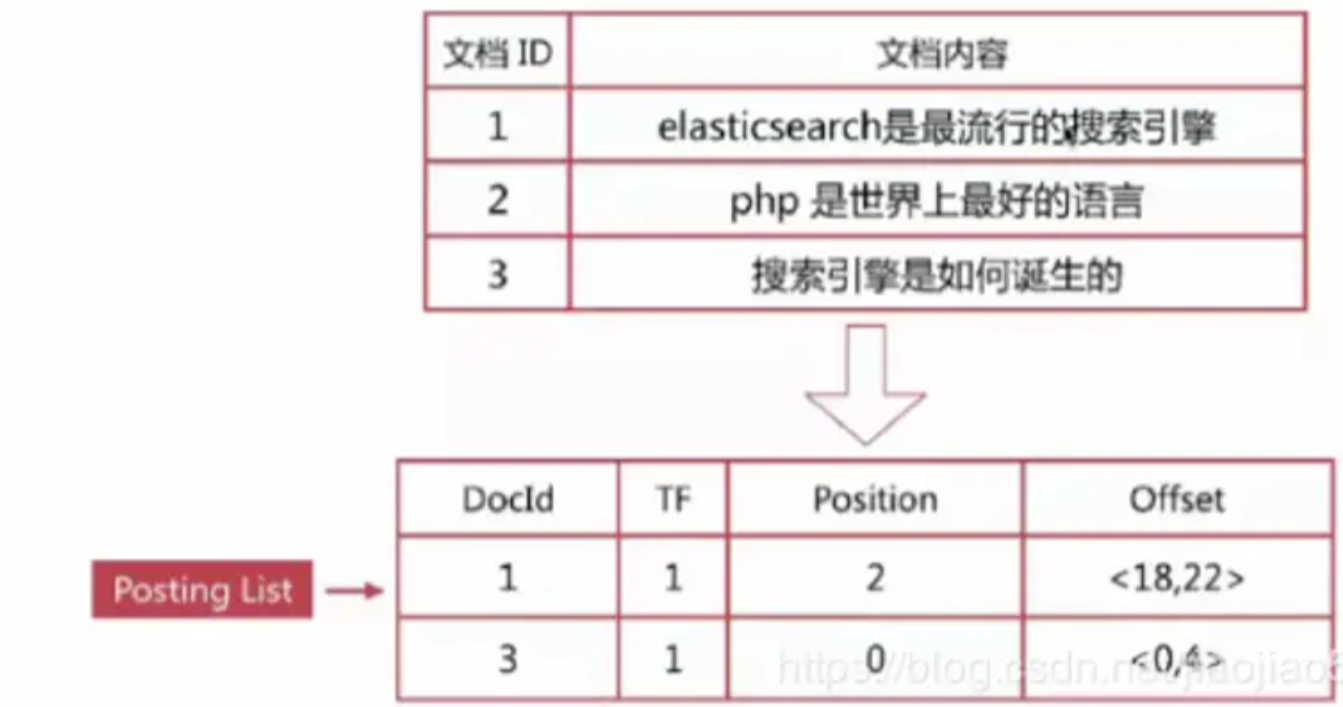
那么上面的文档及内容构建的倒排索引结果会如下图(注:这个图里没有记录展示该词在出现在哪个文档的具体位置):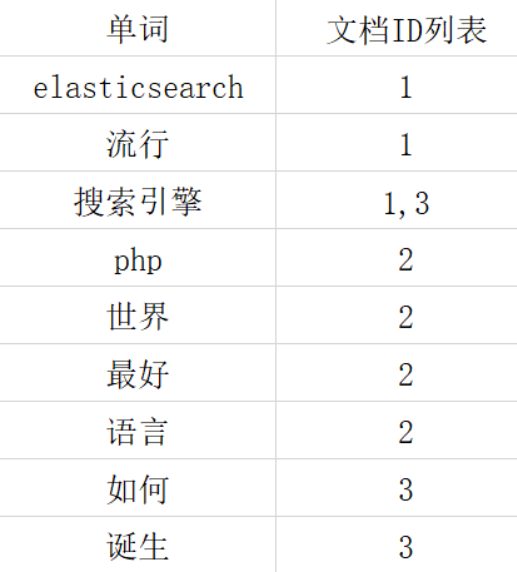
2.3 倒排索引核心组成及查询过程
2.3.1 核心组成
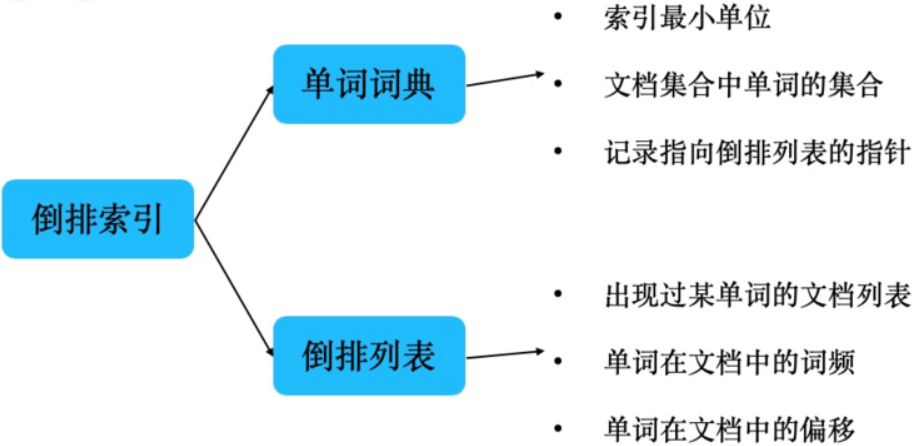
- 单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系;
- 单词词典一般较大,可以通过B+树或哈希拉链法实现,以满足高性能的插入与查询;
- 倒排列表(Posting List):记录了单词对应的文档结合,由以下的倒排索引项组成
- 比如我们要查询‘搜索引擎’这个关键词在哪些文档中出现过。
- 首先我们通过倒排索引可以查询到该关键词出现的文档位置是在1和3中。
- 然后再通过正排索引查询到文档1和3的内容并返回结果。

2.3.3 单词词典特性及其数据结构
单词词典的特性:
- 是文档集合中所有单词的集合
- 它是保存索引的最小单位
- 其中记录着指向倒排列表的指针
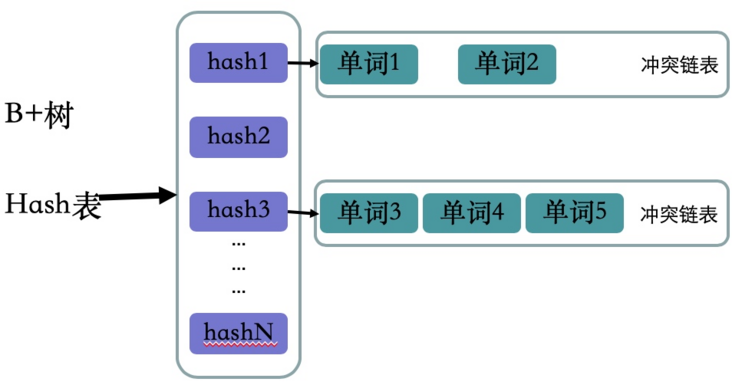
单词词典数据结构:B+树和Hash表
- B+树和Mysql索引结构中主键索引数据结构一样,不再讨论
- 哈希表的key是单词的hash值,value是单词的链表,因为hash算法会有冲突的情况发生,所以这里的值是一个集合,里面保存着相同hash值得单词以及改词指向倒排列表的指针
三、安装
elasticsearch的版本和kibana的版本必须一致,才可以正确运行。并且需要安装node.js,如果是版本问题导致无法启动需要配置环境变量来解决(具体解决去百度)。
3.1 ElaticSearch
3.1.1 下载
https://www.elastic.co/downloads/elasticsearch
3.1.2 解压
3.1.3 运行
进入bin目录下,双击elasticsearch.bat,如果闪退,通过cmd启动
启动完毕后,访问http://localhost:9200/,出现类似下图效果则启动成功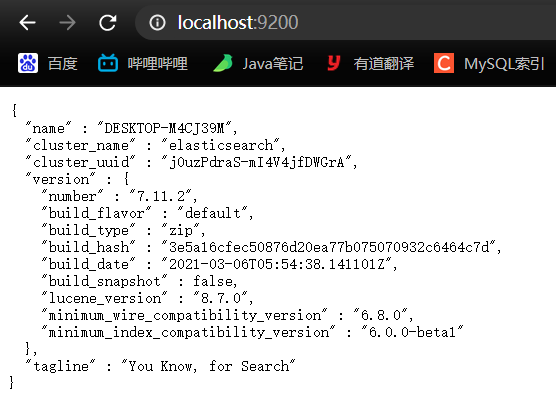
3.2 Kibana
3.2.1 下载
https://www.elastic.co/cn/downloads/kibana
3.2.2 解压

3.2.3 国际化为中文
进入config文件,打开kibana.yml,在最后添加i18n.locale: “zh-CN”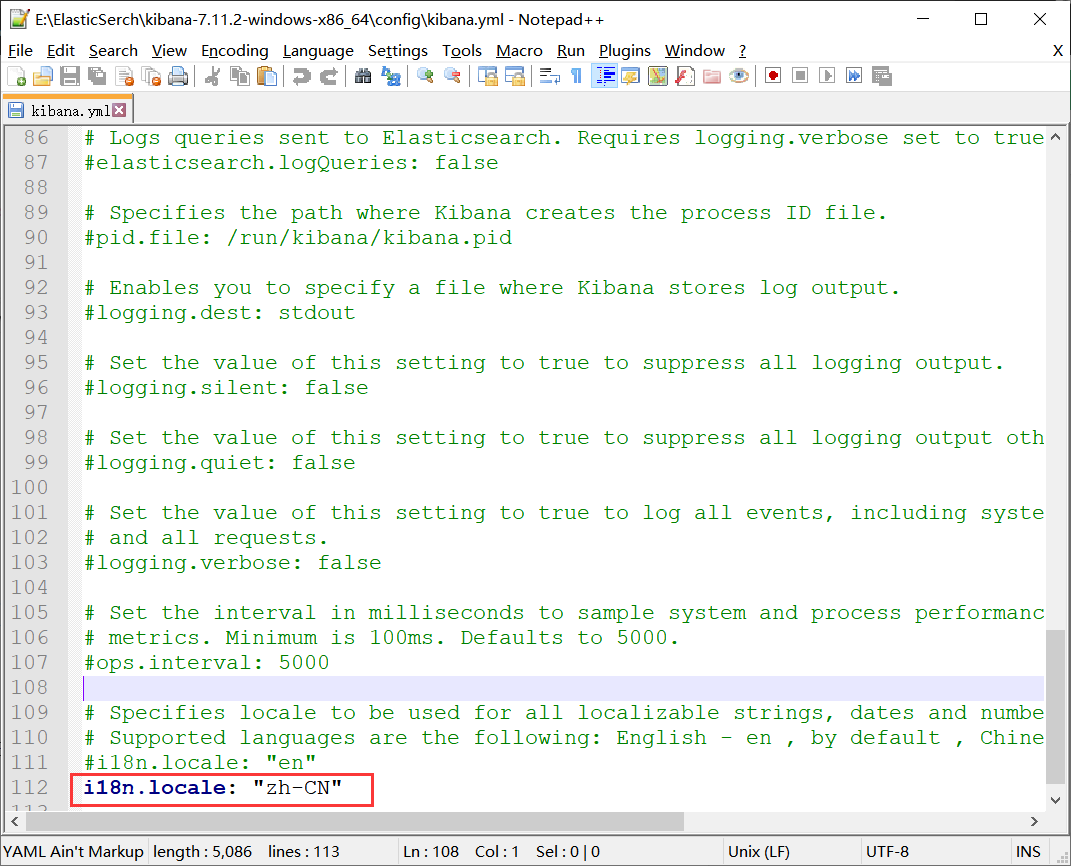
3.2.4 运行
进入bin目录下,双击kibana.bat,如果闪退,通过cmd启动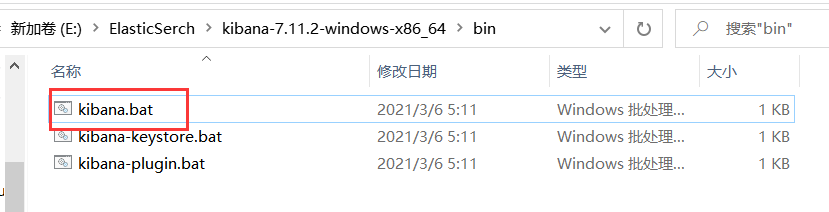
启动比较慢,启动完毕后,访问http://localhost:5601,出现下图效果则启动成功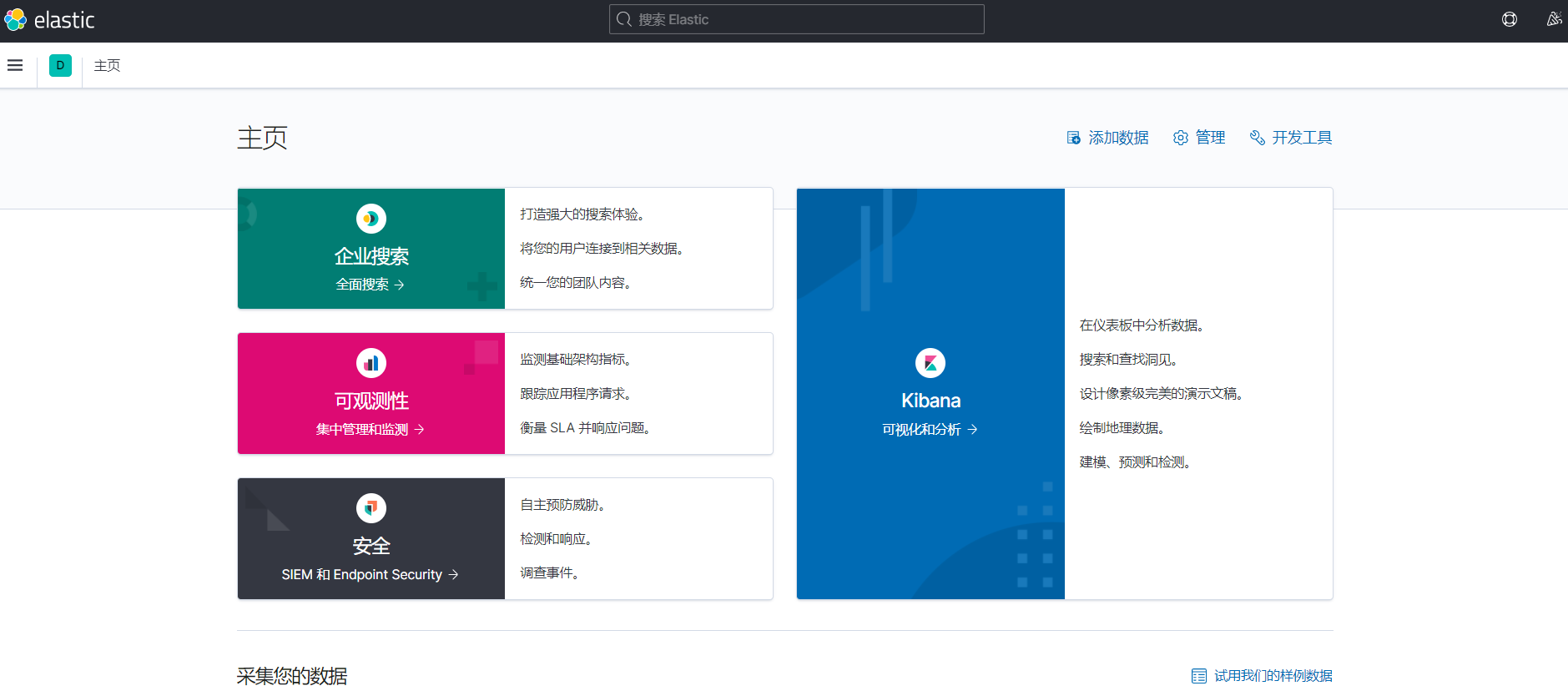
3.3 IK分词器
3.3.1 安装解压
elasticsearch-analysis-ik-7.11.2.zip
将其解压到elasticsearch文件下plugins中,新建的ik文件夹中
3.3.2 测试
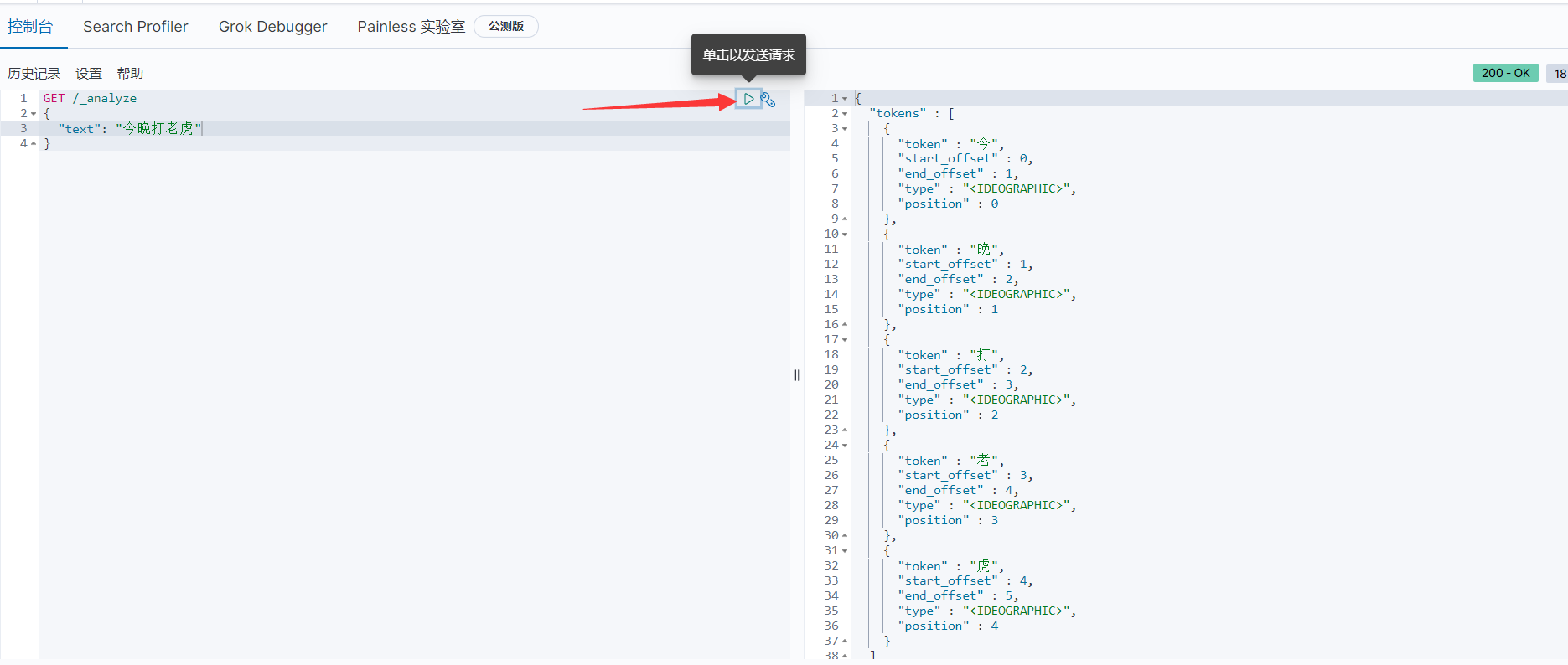
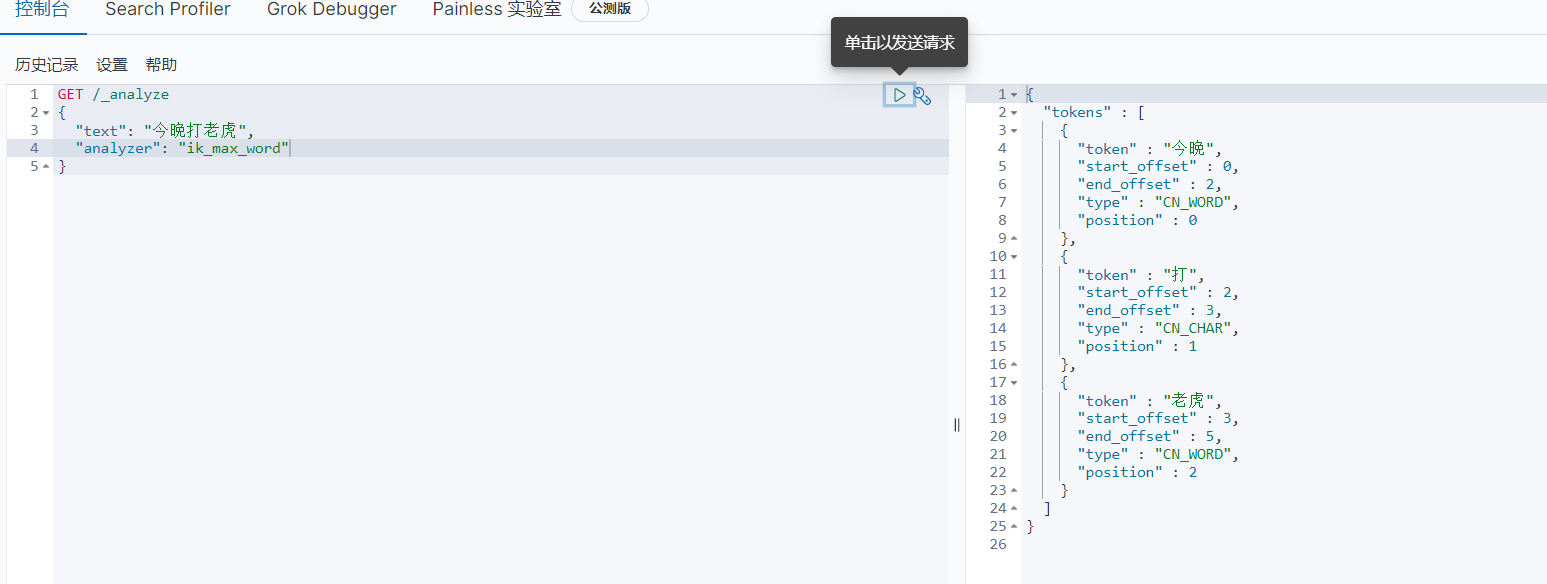
3.3.3 自定义分词
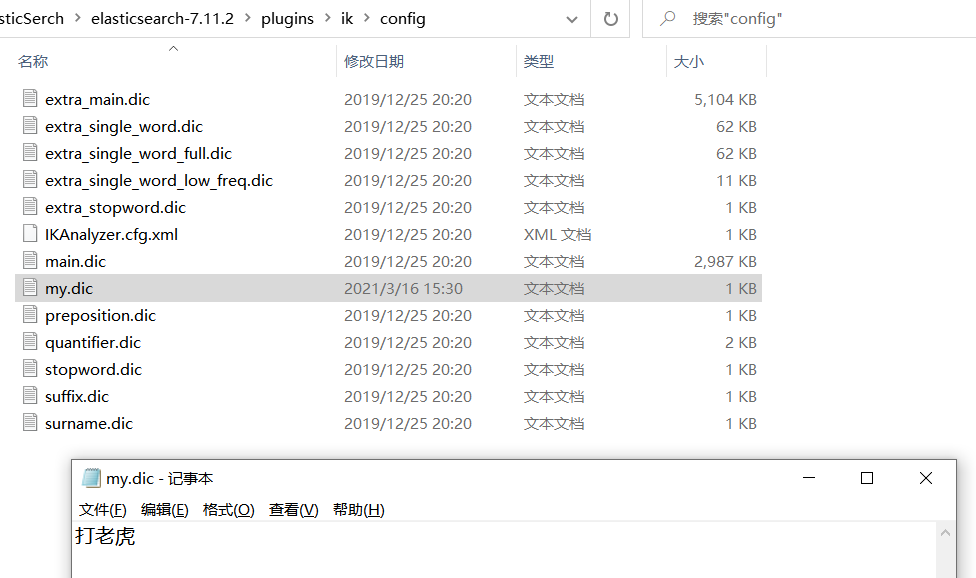
- 进入elasticsearch->plugins->ik->config中
- 所有dic为后缀的文件都是ik自带的分词字典,我们也可以自己添加自定义分词字典my.dic并添加内容打老虎
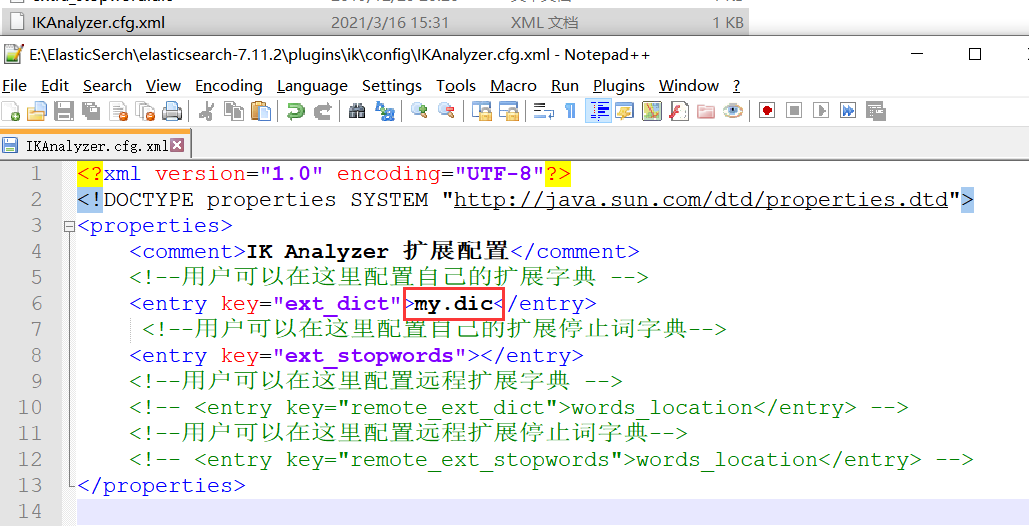
- 进入IKAnalyzer.cfg.xml文件中进行配置
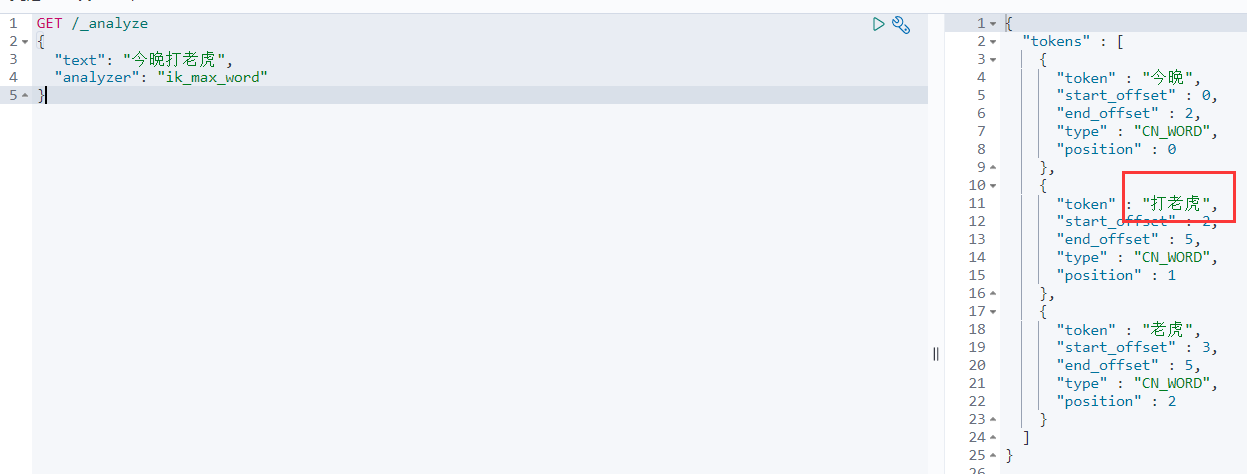
- 重新进入分词测试,可见打老虎已被分为一个单词
四、SpringBoot 集成 ElasticSearch
4.1 新建搜索模块
4.2 导入相关依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
4.3 yml配置文件
spring:
application:
name: ticket-search
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 127.0.0.1:9300
repositories:
enabled: true
4.4 Movie实体类
- @Document(indexName = “movie_index”) 中指定索引名为movie_index
- @Field(name = “name”,analyzer = “ik_max_word”,store = true) 中 指定了分词器为IK分词器及其算法(ik提供两种分词算法 ik_smart,ik_max_word)
@Document(indexName = "movie_index") @Data public class Movie { @Id private Integer id; //电影名 @Field(name = "name",analyzer = "ik_max_word",store = true) private String name; //导演 @Field(name = "director",analyzer = "ik_max_word",store = true) private String director; //主演 @Field(name = "actor",analyzer = "ik_max_word",store = true) private String actor; //简介 @Field(name = "description",analyzer = "ik_max_word",store = true) private String description; //海报 @Field(name = "stills",analyzer = "ik_max_word",store = true) private String stills; //预告片 @Field(name = "trailer",analyzer = "ik_max_word",store = false) private String trailer; //评分 @Field(name = "score",analyzer = "ik_max_word",store = true) private BigDecimal score; }4.5 MovieRepository
```java @Repository public interface MovieRepository extends ElasticsearchRepository
}
<a name="sQykx"></a>
## 4.6 测试类
```java
@SpringBootTest
@RunWith(SpringRunner.class)
class TicketSearchApplicationTests {
@Resource
private MovieRepository movieRepository;
@Test
void test() {
Movie movie = new Movie();
movie.setId(1);
movie.setActor("刘昊然");
movie.setName("唐人街探案");
movie.setDescription("秦风作为一名侦探...");
movieRepository.save(movie);
}
}
4.7 查看结果
- 点击管理
- 点击索引管理
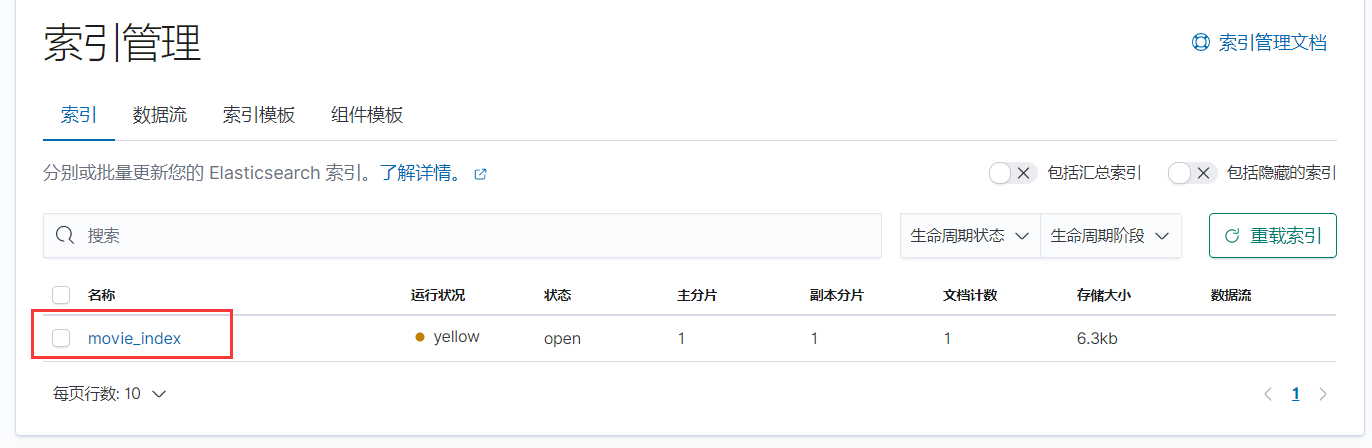
4.8 获取索引中存储数据
4.8.1 修改MovieRepository
@Repository
public interface MovieRepository extends ElasticsearchRepository<Movie, Long> {
List<Movie> findMoviesByNameOrActorOrDescription(String name,String actor,String description);
}
4.8.2 测试类
@Test
void test2(){
String key="侦探";
movieRepository.findMoviesByNameOrActorOrDescription(key,key,key).forEach(e->{
System.out.println(e);
});
}
4.8.3 查看结果
只有一条数据:

若有收获,就点个赞吧
0 人点赞
