5.1
根据表5.1所给的训练数据集,利用信息增益比(C4.5算法)生成决策树.
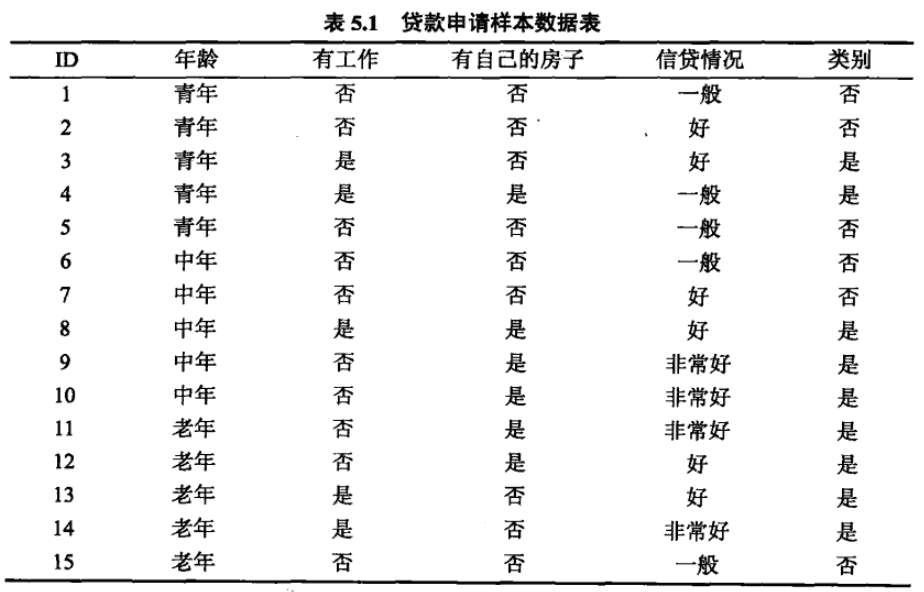
先计算每个特征的信息增益比,信息增益比 。
。
其中D关于特征A的熵 (n为A特征的取值个数)
(n为A特征的取值个数)
D关于特征A的条件熵
信息增益 
分别以 表示年龄、有工作、有自己的房子和信贷情况4个特征。
表示年龄、有工作、有自己的房子和信贷情况4个特征。
经验熵 :
:



例题5.2已经计算了各个特征的信息增益:



得信息增益比:



选择信息增益比最大的特征 作为根节点特征,将训练集分为两个子集
作为根节点特征,将训练集分为两个子集 和
和 ,由于
,由于 中只有同一类样本点,所以它是一个叶节点,标记为“是”,对
中只有同一类样本点,所以它是一个叶节点,标记为“是”,对 从
从 中选择新的特征,中的元素有:
中选择新的特征,中的元素有:

重新计算各个特征的信息增益比
经验熵:
信息增益:
其中 分别表示中
分别表示中 取值为青年,中年,老年的样本子集。
取值为青年,中年,老年的样本子集。

其中 分别表示中
分别表示中 取值为否,是的样本子集。
取值为否,是的样本子集。

其中分别表示中 取值为一般,好,非常好的样本子集。
取值为一般,好,非常好的样本子集。
信息增益比:


选择信息增益比最大的特征作为节点的特征,从这一结点引出两个子结点:一个对应“是”(有工作)的子结点,包含3个样本,它们属于同一类,所以这是一个叶结点,类标记为“是”;另一个是对应“否”(无工作)的子结点,包含6个样本,它们也属于同一类,所以这也是一个叶结点,类标记为“否”。
最终的决策树如图: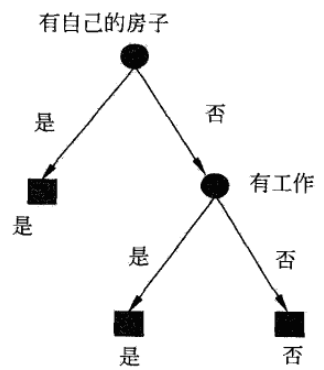
代码:
例题5.3用ID3算法生成决策树(信息增益)
import numpy as npfrom math import logdef loadData():datasets = [['青年', '否', '否', '一般', '否'],['青年', '否', '否', '好', '否'],['青年', '是', '否', '好', '是'],['青年', '是', '是', '一般', '是'],['青年', '否', '否', '一般', '否'],['中年', '否', '否', '一般', '否'],['中年', '否', '否', '好', '否'],['中年', '是', '是', '好', '是'],['中年', '否', '是', '非常好', '是'],['中年', '否', '是', '非常好', '是'],['老年', '否', '是', '非常好', '是'],['老年', '否', '是', '好', '是'],['老年', '是', '否', '好', '是'],['老年', '是', '否', '非常好', '是'],['老年', '否', '否', '一般', '否'],]labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']# 返回数据集和每个维度的名称return datasets, labels# 计算熵def calc_entropy(datasets):label_count = {}for dataset in datasets:label = dataset[-1]if label not in label_count:label_count[label] = 0label_count[label] += 1entropy = -sum([(p/len(datasets))*log(p/len(datasets),2) for p in label_count.values()])return entropy# 计算条件熵def calc_conditional_entropy(datasets, index = 0):feature_data = {}for dataset in datasets:feature = dataset[index]if feature not in feature_data:feature_data[feature] = []feature_data[feature].append(dataset)condEntropy = sum([(len(p)/len(datasets))*calc_entropy(p) for p in feature_data.values()])return condEntropy# 计算信息增益def info_gain(entropy, condEntropy):return entropy - condEntropydef info_gain_train_childTree(datasets, labels):entropy = calc_entropy(datasets)features = []for index in range(len(datasets[0])-1):condEntropy = calc_conditional_entropy(datasets, index)c_info_gain = info_gain(entropy, condEntropy)features.append((index, c_info_gain))print("特征({})的信息增益为{:.3f}".format(labels[index], c_info_gain))best_feature = max(features, key=lambda x: x[-1])print("特征({})的信息增益最大,选择为当前节点特征".format(labels[best_feature[0]]))return best_featuredef info_gain_train(datasets, labels):label_count = {}for dataset in datasets:label = dataset[-1]if label not in label_count:label_count[label] = 0label_count[label] += 1if len(label_count.keys()) == 1:key = list(label_count.keys())[0]print("此时类别均为{}".format(key))returnbest_feature = info_gain_train_childTree(datasets, labels)feature_data = {}for dataset in datasets:feature = dataset[best_feature[0]]if feature not in feature_data:feature_data[feature] = []feature_data[feature].append(dataset)for data in zip(feature_data.keys(), feature_data.values()):print("当{}为{}".format(labels[best_feature[0]], data[0]))info_gain_train(data[1], labels)if __name__ == "__main__":datasets, labels = loadData()info_gain_train(datasets, labels)
运行结果:
特征(年龄)的信息增益为0.083特征(有工作)的信息增益为0.324特征(有自己的房子)的信息增益为0.420特征(信贷情况)的信息增益为0.363特征(有自己的房子)的信息增益最大,选择为当前节点特征当有自己的房子为否特征(年龄)的信息增益为0.252特征(有工作)的信息增益为0.918特征(有自己的房子)的信息增益为0.000特征(信贷情况)的信息增益为0.474特征(有工作)的信息增益最大,选择为当前节点特征当有工作为否此时类别均为否当有工作为是此时类别均为是当有自己的房子为是此时类别均为是
C4.5生成算法(信息增益比)
import numpy as npfrom math import logdef loadData():datasets = [['青年', '否', '否', '一般', '否'],['青年', '否', '否', '好', '否'],['青年', '是', '否', '好', '是'],['青年', '是', '是', '一般', '是'],['青年', '否', '否', '一般', '否'],['中年', '否', '否', '一般', '否'],['中年', '否', '否', '好', '否'],['中年', '是', '是', '好', '是'],['中年', '否', '是', '非常好', '是'],['中年', '否', '是', '非常好', '是'],['老年', '否', '是', '非常好', '是'],['老年', '否', '是', '好', '是'],['老年', '是', '否', '好', '是'],['老年', '是', '否', '非常好', '是'],['老年', '否', '否', '一般', '否'],]labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']# 返回数据集和每个维度的名称return datasets, labelsdef calc_entropy(datasets, index=-1):label_count = {}for dataset in datasets:label = dataset[index]if label not in label_count:label_count[label] = 0label_count[label] += 1entropy = -sum([(p/len(datasets))*log(p/len(datasets),2) for p in label_count.values()])return entropydef calc_conditional_entropy(datasets, index = 0):feature_data = {}for dataset in datasets:feature = dataset[index]if feature not in feature_data:feature_data[feature] = []feature_data[feature].append(dataset)condEntropy = sum([(len(p)/len(datasets))*calc_entropy(p) for p in feature_data.values()])return condEntropydef info_gain(entropy, condEntropy):return entropy - condEntropydef info_gain_ratio(c_info_gain, c_entropy):return 0 if c_info_gain == 0 else c_info_gain / c_entropydef info_gain_train_childTree(datasets, labels):entropy = calc_entropy(datasets)features = []for index in range(len(datasets[0])-1):condEntropy = calc_conditional_entropy(datasets, index)c_info_gain = info_gain(entropy, condEntropy)c_entropy = calc_entropy(datasets, index)c_info_gain_ratio = info_gain_ratio(c_info_gain, c_entropy)features.append((index, c_info_gain_ratio))print("特征({})的信息增益比为{:.3f}".format(labels[index], c_info_gain_ratio))best_feature = max(features, key=lambda x: x[-1])print("特征({})的信息增益比最大,选择为当前节点特征".format(labels[best_feature[0]]))return best_featuredef info_gain_train(datasets, labels):label_count = {}for dataset in datasets:label = dataset[-1]if label not in label_count:label_count[label] = 0label_count[label] += 1if len(label_count.keys()) == 1:key = list(label_count.keys())[0]print("此时类别均为{}".format(key))returnbest_feature = info_gain_train_childTree(datasets, labels)feature_data = {}for dataset in datasets:feature = dataset[best_feature[0]]if feature not in feature_data:feature_data[feature] = []feature_data[feature].append(dataset)for data in zip(feature_data.keys(), feature_data.values()):print("当{}为{}".format(labels[best_feature[0]], data[0]))info_gain_train(data[1], labels)if __name__ == "__main__":datasets, labels = loadData()info_gain_train(datasets, labels)
运行结果:
特征(年龄)的信息增益比为0.052特征(有工作)的信息增益比为0.352特征(有自己的房子)的信息增益比为0.433特征(信贷情况)的信息增益比为0.232特征(有自己的房子)的信息增益比最大,选择为当前节点特征当有自己的房子为否特征(年龄)的信息增益比为0.164特征(有工作)的信息增益比为1.000特征(有自己的房子)的信息增益比为0.000特征(信贷情况)的信息增益比为0.340特征(有工作)的信息增益比最大,选择为当前节点特征当有工作为否此时类别均为否当有工作为是此时类别均为是当有自己的房子为是此时类别均为是
5.2
已知下表所示的训练数据,试用平方误差损失准则生成一个二叉回归树.
| x__i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y__i | 4.50 | 4.75 | 4.91 | 5.34 | 5.80 | 7.05 | 7.70 | 8.23 | 8.70 | 9.00 |
回归树的建立算法:
import numpy as npimport matplotlib.pyplot as plt#节点定义class TreeNode(object):def __init__(self, tempR, tempc):self.R = tempRself.c = tempcself.left = Noneself.right = None# y的值y = np.array([4.5, 4.75, 4.91, 5.34, 5.8, 7.05, 7.9, 8.23, 8.7, 9])#CART算法建立回归树def CART(start, end):# 切点s的选择表示R1为x值小于等于s的点,R2为大于s的点if(end - start >= 1):result = []for s in range(start+1, end+1): # s在(start, end]之间取值y1 = y[start : s] # y1取索引为[start, s]之间的值y2 = y[s: end+1] # y2取索引为[s+1, end]之间的值result.append((y1.std()**2)*y1.size + (y2.std()**2)*y2.size)# std即标准差函数,求标准差的时候默认除以元素的个数,因此平方后乘以元素个数才是要求的平方差index1 = result.index(min(result)) + start # 取平方差误差最小的索引值root = TreeNode(y[start:end+1], min(result))# 索引值为0-9,x值为1-10,即s的值比求的索引值多1print("节点元素值为",y[start:end+1], " s =",index1+1, " 最小平方误差为",min(result))#输出s值和最小平方误差root.left = CART(start, index1) # 对列表的左侧生成左子树root.right = CART(index1+1, end) # 对列表的右侧生成右子树else:root = Nonereturn rootif __name__ == "__main__":root = CART(0, 9)
运行结果:
节点元素值为 [4.5 4.75 4.91 5.34 5.8 7.05 7.9 8.23 8.7 9. ] s = 5 最小平方误差为 3.3587199999999986节点元素值为 [4.5 4.75 4.91 5.34 5.8 ] s = 3 最小平方误差为 0.1912节点元素值为 [4.5 4.75 4.91] s = 1 最小平方误差为 0.012800000000000023节点元素值为 [4.75 4.91] s = 2 最小平方误差为 0.0节点元素值为 [5.34 5.8 ] s = 4 最小平方误差为 0.0节点元素值为 [7.05 7.9 8.23 8.7 9. ] s = 7 最小平方误差为 0.6625166666666665节点元素值为 [7.05 7.9 ] s = 6 最小平方误差为 0.0节点元素值为 [8.23 8.7 9. ] s = 8 最小平方误差为 0.04500000000000021节点元素值为 [8.7 9. ] s = 9 最小平方误差为 0.0
计算过程:
以根节点为例,变换切分点s,选择使得平方误差最小的切分点
s=1:
即
此时有 ,
,
然后依次将s从2取值到10,计算平方误差,选其中平方误差最小的s为根节点s,将元素分为左右子树后,再对左右子树进行相同的处理。

若有收获,就点个赞吧
0 人点赞
