逻辑斯谛回归(LR)是经典的分类方法
1.逻辑斯谛回归模型是由以下条件概率分布表示的分类模型。逻辑斯谛回归模型可以用于二类或多类分类。

这里,x为输入特征,w为特征的权值。
逻辑斯谛回归模型源自逻辑斯谛分布,其分布函数F(x)是S形函数。逻辑斯谛回归模型是由输入的线性函数表示的输出的对数几率模型。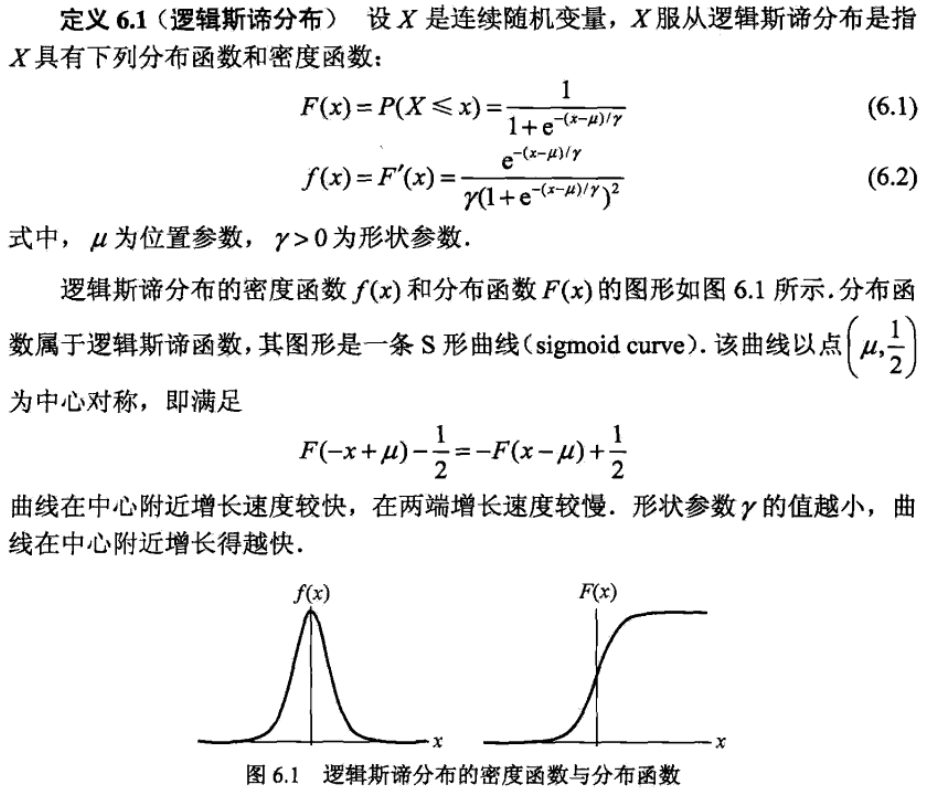
2.最大熵模型是由以下条件概率分布表示的分类模型。最大熵模型也可以用于二类或多类分类。


其中, 是规范化因子,
是规范化因子, 为特征函数,
为特征函数, 为特征的权值。
为特征的权值。
3.最大熵模型可以由最大熵原理推导得出。最大熵原理是概率模型学习或估计的一个准则。最大熵原理认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。
最大熵原理应用到分类模型的学习中,有以下约束最优化问题:



求解此最优化问题的对偶问题得到最大熵模型。
4.逻辑斯谛回归模型与最大熵模型都属于对数线性模型。
5.逻辑斯谛回归模型及最大熵模型学习一般采用极大似然估计,或正则化的极大似然估计。逻辑斯谛回归模型及最大熵模型学习可以形式化为无约束最优化问题。求解该最优化问题的算法有改进的迭代尺度法、梯度下降法、拟牛顿法。
回归模型:
其中wx线性函数:
from math import expimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlinefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# datadef create_data():iris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['label'] = iris.targetdf.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']data = np.array(df.iloc[:100, [0,1,-1]])# print(data)return data[:,:2], data[:,-1]X, y = create_data()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)class LogisticReressionClassifier:def __init__(self, max_iter=200, learning_rate=0.01):self.max_iter = max_iterself.learning_rate = learning_ratedef sigmoid(self, x):return 1 / (1 + exp(-x))def data_matrix(self, X):data_mat = []for d in X:data_mat.append([1.0, *d])return data_matdef fit(self, X, y):# label = np.mat(y)data_mat = self.data_matrix(X) # m*nself.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)for iter_ in range(self.max_iter):for i in range(len(X)):result = self.sigmoid(np.dot(data_mat[i], self.weights))error = y[i] - resultself.weights += self.learning_rate * error * np.transpose([data_mat[i]])print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))# def f(self, x):# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]def score(self, X_test, y_test):right = 0X_test = self.data_matrix(X_test)for x, y in zip(X_test, y_test):result = np.dot(x, self.weights)if (result > 0 and y == 1) or (result < 0 and y == 0):right += 1return right / len(X_test)lr_clf = LogisticReressionClassifier()lr_clf.fit(X_train, y_train)LogisticRegression Model(learning_rate=0.01,max_iter=200)lr_clf.score(X_test, y_test)Out[6]:0.9666666666666667x_ponits = np.arange(4, 8)y_ = -(lr_clf.weights[1]*x_ponits + lr_clf.weights[0])/lr_clf.weights[2] # 绘制直线plt.plot(x_ponits, y_)#lr_clf.show_graph()plt.scatter(X[:50,0],X[:50,1], label='0') # 绘制离散点plt.scatter(X[50:,0],X[50:,1], label='1')plt.legend()
scikit-learn实例
sklearn.linear_model.LogisticRegression
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
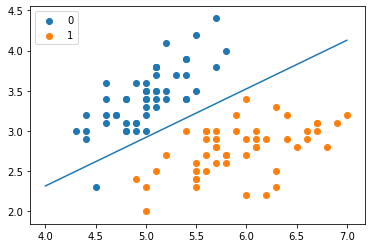
from sklearn.linear_model import LogisticRegressionclf = LogisticRegression(max_iter=200)clf.fit(X_train, y_train)Out[10]:LogisticRegression(max_iter=200)clf.score(X_test, y_test)Out[11]:0.9666666666666667print(clf.coef_, clf.intercept_)[[ 2.59546005 -2.81261232]] [-5.08164524]x_ponits = np.arange(4, 8)y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]plt.plot(x_ponits, y_)plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')plt.xlabel('sepal length')plt.ylabel('sepal width')plt.legend()
最大熵模型
import mathfrom copy import deepcopyclass MaxEntropy:def __init__(self, EPS=0.005):self._samples = []self._Y = set() # 标签集合,相当去去重后的yself._numXY = {} # key为(x,y),value为出现次数self._N = 0 # 样本数self._Ep_ = [] # 样本分布的特征期望值self._xyID = {} # key记录(x,y),value记录id号self._n = 0 # 特征键值(x,y)的个数self._C = 0 # 最大特征数self._IDxy = {} # key为(x,y),value为对应的id号self._w = []self._EPS = EPS # 收敛条件self._lastw = [] # 上一次w参数值def loadData(self, dataset):self._samples = deepcopy(dataset)for items in self._samples:y = items[0]X = items[1:]self._Y.add(y) # 集合中y若已存在则会自动忽略for x in X:if (x, y) in self._numXY:self._numXY[(x, y)] += 1else:self._numXY[(x, y)] = 1self._N = len(self._samples) # 样本数self._n = len(self._numXY) # 特征键值(x,y)的个数self._C = max([len(sample) - 1 for sample in self._samples]) # 最大特征数self._w = [0] * self._nself._lastw = self._w[:] # 上一次w参数值self._Ep_ = [0] * self._n # 样本分布的特征期望值for i, xy in enumerate(self._numXY): # 计算特征函数fi关于经验分布的期望self._Ep_[i] = self._numXY[xy] / self._Nself._xyID[xy] = iself._IDxy[i] = xydef _Zx(self, X): # 计算每个Z(x)值zx = 0for y in self._Y:ss = 0for x in X:if (x, y) in self._numXY:ss += self._w[self._xyID[(x, y)]]zx += math.exp(ss)return zxdef _model_pyx(self, y, X): # 计算每个P(y|x)zx = self._Zx(X)ss = 0for x in X:if (x, y) in self._numXY:ss += self._w[self._xyID[(x, y)]]pyx = math.exp(ss) / zxreturn pyxdef _model_ep(self, index): # 计算特征函数fi关于模型的期望x, y = self._IDxy[index]ep = 0for sample in self._samples:if x not in sample:continuepyx = self._model_pyx(y, sample)ep += pyx / self._Nreturn epdef _convergence(self): # 判断是否全部收敛for last, now in zip(self._lastw, self._w):if abs(last - now) >= self._EPS:return Falsereturn Truedef predict(self, X): # 计算预测概率Z = self._Zx(X)result = {}for y in self._Y:ss = 0for x in X:if (x, y) in self._numXY:ss += self._w[self._xyID[(x, y)]]pyx = math.exp(ss) / Zresult[y] = pyxreturn resultdef train(self, maxiter=1000): # 训练数据for loop in range(maxiter): # 最大训练次数print("iter:%d" % loop)self._lastw = self._w[:]for i in range(self._n):ep = self._model_ep(i) # 计算第i个特征的模型期望self._w[i] += math.log(self._Ep_[i] / ep) / self._C # 更新参数print("w:", self._w)if self._convergence(): # 判断是否收敛breakdataset = [['no', 'sunny', 'hot', 'high', 'FALSE'],['no', 'sunny', 'hot', 'high', 'TRUE'],['yes', 'overcast', 'hot', 'high', 'FALSE'],['yes', 'rainy', 'mild', 'high', 'FALSE'],['yes', 'rainy', 'cool', 'normal', 'FALSE'],['no', 'rainy', 'cool', 'normal', 'TRUE'],['yes', 'overcast', 'cool', 'normal', 'TRUE'],['no', 'sunny', 'mild', 'high', 'FALSE'],['yes', 'sunny', 'cool', 'normal', 'FALSE'],['yes', 'rainy', 'mild', 'normal', 'FALSE'],['yes', 'sunny', 'mild', 'normal', 'TRUE'],['yes', 'overcast', 'mild', 'high', 'TRUE'],['yes', 'overcast', 'hot', 'normal', 'FALSE'],['no', 'rainy', 'mild', 'high', 'TRUE']]maxent = MaxEntropy()x = ['overcast', 'mild', 'high', 'FALSE']maxent.loadData(dataset)maxent.train()print('predict:', maxent.predict(x))predict: {'yes': 0.9999971802186581, 'no': 2.819781341881656e-06}

若有收获,就点个赞吧
0 人点赞
