
K近邻法
距离度量
设特征空间 是
是 维实数向量空间 ,
维实数向量空间 , ,
, ,
, ,则:
,则: ,
, 的
的 距离定义为:
距离定义为:
 曼哈顿距离
曼哈顿距离 欧氏距离
欧氏距离 切比雪夫距离
```python
import math
from itertools import combinations
切比雪夫距离
```python
import math
from itertools import combinations
def L(x, y, p=2):
# x1 = [1, 1], x2 = [5,1]if len(x) == len(y) and len(x) > 1:sum = 0for i in range(len(x)):sum += math.pow(abs(x[i] - y[i]), p)return math.pow(sum, 1 / p)else:return 0
**<a name="DGkLq"></a>## 例3.1---```pythonx1 = [1, 1]x2 = [5, 1]x3 = [4, 4]
# x1, x2for i in range(1, 5):r = {'1-{}'.format(c): L(x1, c, p=i) for c in [x2, x3]}print(min(zip(r.values(), r.keys()))) # 输出二者中较小的那个(4.0, '1-[5, 1]')(4.0, '1-[5, 1]')(3.7797631496846193, '1-[4, 4]')(3.5676213450081633, '1-[4, 4]')

K近邻算法实现
- 数据集 | | sepal length | sepal width | petal length | petal width | label | | :—- | :—- | :—- | :—- | :—- | :—- | | 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 | | 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 | | 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 | | 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 | | 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 | | 5 | 5.4 | 3.9 | 1.7 | 0.4 | 0 | | 6 | 4.6 | 3.4 | 1.4 | 0.3 | 0 | | 7 | 5.0 | 3.4 | 1.5 | 0.2 | 0 | | 8 | 4.4 | 2.9 | 1.4 | 0.2 | 0 | | 9 | 4.9 | 3.1 | 1.5 | 0.1 | 0 | | 10 | 5.4 | 3.7 | 1.5 | 0.2 | 0 | | 11 | 4.8 | 3.4 | 1.6 | 0.2 | 0 | | 12 | 4.8 | 3.0 | 1.4 | 0.1 | 0 | | 13 | 4.3 | 3.0 | 1.1 | 0.1 | 0 | | 14 | 5.8 | 4.0 | 1.2 | 0.2 | 0 | | 15 | 5.7 | 4.4 | 1.5 | 0.4 | 0 | | 16 | 5.4 | 3.9 | 1.3 | 0.4 | 0 | | 17 | 5.1 | 3.5 | 1.4 | 0.3 | 0 | | 18 | 5.7 | 3.8 | 1.7 | 0.3 | 0 | | 19 | 5.1 | 3.8 | 1.5 | 0.3 | 0 | | 20 | 5.4 | 3.4 | 1.7 | 0.2 | 0 | | 21 | 5.1 | 3.7 | 1.5 | 0.4 | 0 | | 22 | 4.6 | 3.6 | 1.0 | 0.2 | 0 | | 23 | 5.1 | 3.3 | 1.7 | 0.5 | 0 | | 24 | 4.8 | 3.4 | 1.9 | 0.2 | 0 | | 25 | 5.0 | 3.0 | 1.6 | 0.2 | 0 | | 26 | 5.0 | 3.4 | 1.6 | 0.4 | 0 | | 27 | 5.2 | 3.5 | 1.5 | 0.2 | 0 | | 28 | 5.2 | 3.4 | 1.4 | 0.2 | 0 | | 29 | 4.7 | 3.2 | 1.6 | 0.2 | 0 | | … | … | … | … | … | … | | 120 | 6.9 | 3.2 | 5.7 | 2.3 | 2 | | 121 | 5.6 | 2.8 | 4.9 | 2.0 | 2 | | 122 | 7.7 | 2.8 | 6.7 | 2.0 | 2 | | 123 | 6.3 | 2.7 | 4.9 | 1.8 | 2 | | 124 | 6.7 | 3.3 | 5.7 | 2.1 | 2 | | 125 | 7.2 | 3.2 | 6.0 | 1.8 | 2 | | 126 | 6.2 | 2.8 | 4.8 | 1.8 | 2 | | 127 | 6.1 | 3.0 | 4.9 | 1.8 | 2 | | 128 | 6.4 | 2.8 | 5.6 | 2.1 | 2 | | 129 | 7.2 | 3.0 | 5.8 | 1.6 | 2 | | 130 | 7.4 | 2.8 | 6.1 | 1.9 | 2 | | 131 | 7.9 | 3.8 | 6.4 | 2.0 | 2 | | 132 | 6.4 | 2.8 | 5.6 | 2.2 | 2 | | 133 | 6.3 | 2.8 | 5.1 | 1.5 | 2 | | 134 | 6.1 | 2.6 | 5.6 | 1.4 | 2 | | 135 | 7.7 | 3.0 | 6.1 | 2.3 | 2 | | 136 | 6.3 | 3.4 | 5.6 | 2.4 | 2 | | 137 | 6.4 | 3.1 | 5.5 | 1.8 | 2 | | 138 | 6.0 | 3.0 | 4.8 | 1.8 | 2 | | 139 | 6.9 | 3.1 | 5.4 | 2.1 | 2 | | 140 | 6.7 | 3.1 | 5.6 | 2.4 | 2 | | 141 | 6.9 | 3.1 | 5.1 | 2.3 | 2 | | 142 | 5.8 | 2.7 | 5.1 | 1.9 | 2 | | 143 | 6.8 | 3.2 | 5.9 | 2.3 | 2 | | 144 | 6.7 | 3.3 | 5.7 | 2.5 | 2 | | 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2 | | 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2 | | 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2 | | 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2 | | 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2 |
150 rows × 5 columns
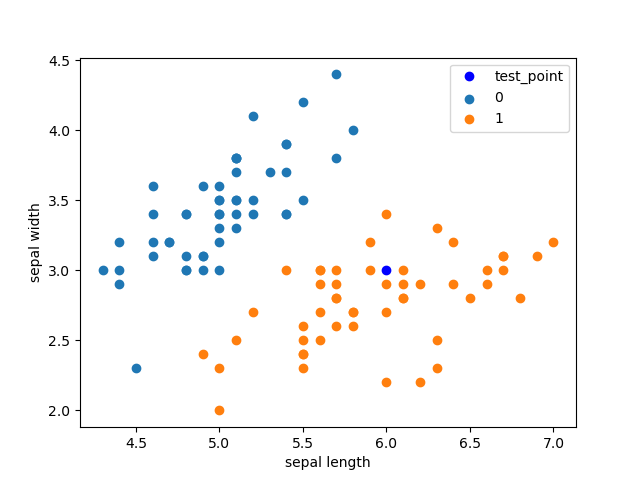
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom collections import Counter# datairis = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['label'] = iris.targetdf.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']# k近邻算法class KNN:def __init__(self, X_train, y_train, n_neighbors=3, p=2):"""parameter: n_neighbors 临近点个数parameter: p 距离度量"""self.n = n_neighborsself.p = pself.X_train = X_trainself.y_train = y_traindef predict(self, X):# 取出n个点knn_list = []for i in range(self.n):dist = np.linalg.norm(X - self.X_train[i], ord=self.p)knn_list.append((dist, self.y_train[i]))for i in range(self.n, len(self.X_train)):max_index = knn_list.index(max(knn_list, key=lambda x: x[0]))dist = np.linalg.norm(X - self.X_train[i], ord=self.p)if knn_list[max_index][0] > dist:knn_list[max_index] = (dist, self.y_train[i])# 统计knn = [k[-1] for k in knn_list]count_pairs = Counter(knn)# max_count = sorted(count_pairs, key=lambda x: x)[-1]max_count = sorted(count_pairs.items(), key=lambda x: x[1])[-1][0]return max_countdef score(self, X_test, y_test):right_count = 0n = 10for X, y in zip(X_test, y_test):label = self.predict(X)if label == y:right_count += 1return right_count / len(X_test)data = np.array(df.iloc[:100, [0, 1, -1]]) # 提取数据X, y = data[:,:-1], data[:,-1]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 测试集占比20%clf = KNN(X_train, y_train)print('正确率为:{}'.format(clf.score(X_test, y_test)))test_point = [6.0, 3.0]print('Test Point: {}'.format(clf.predict(test_point)))# 画图表示plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')plt.plot(test_point[0], test_point[1], 'bo', label='test_point')plt.xlabel('sepal length')plt.ylabel('sepal width')plt.legend()plt.show()
正确率为:1.0Test Point: 1.0
scikit-learn的KNeighborsClassifier用法
sklearn.neighbors.KNeighborsClassifier
- n_neighbors: 临近点个数
- p: 距离度量
- algorithm: 近邻算法,可选{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}
- weights: 确定近邻的权重 ```python import numpy as np import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris
data
iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df[‘label’] = iris.target df.columns = [‘sepal length’, ‘sepal width’, ‘petal length’, ‘petal width’, ‘label’]
data = np.array(df.iloc[:100, [0, 1, -1]]) # 提取数据 X, y = data[:, :-1], data[:, -1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) test_point = [6.0, 3.0]
clf_sk = KNeighborsClassifier() clf_sk.fit(X_train, y_train) print(‘正确率为:{}’.format(clf_sk.score(X_test, y_test))) print(‘Test Point: {}’.format(clf_sk.predict([test_point])))
```python正确率为:1.0Test Point: [1.]

若有收获,就点个赞吧
0 人点赞
