一、简介
JPA(Java Persistence API)是Sun官方提出的Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合ORM技术,结束现在Hibernate,TopLink,JDO等ORM框架各自为营的局面。值得注意的是,JPA是在充分吸收了现有Hibernate,TopLink,JDO等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从目前的开发社区的反应上看,JPA受到了极大的支持和赞扬,其中就包括了Spring与EJB3.0的开发团队。
Spring Data JPA 是 Spring 基于ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
二、JPA事务
1. 创建一个StudentService
2. 直接实现接口,在service层进行操作
@Servicepublic class StudentServiceImpl implements StudentService{@AutowiredStudentRepository sr;@Override@Transactional()public void add(Student s) {sr.save(s);Student s2 = new Student();int i = 1/0;s2.setName(s.getName()+"的副本");sr.save(s2);}}
3. 在测试用例中进行测试
@Autowired
StudentService studentService;
@Test
public void save(){
Student s = new Student();
s.setName("小红");
s.setMoney(110.0);
studentService.add(s);
}
4. 事务注解详解
@Transactional 注解有两个
- spring提供的 @org.springframework.transaction.annotation.Transactional
- jdk提供 @javax.transaction.Transactional
在回滚的设置上,spring提供的是rollbackFor,jdk提供的是rollbackOn,在使用方法上是一致的(rollbackFor用于指定能够触发事务回滚的异常类型,可以指定多个用逗号分隔)
注意事项:
- 当我们抛出的异常为RunTime及其子类或者Error和其子类的时候。不论rollbackFor的异常是啥,都会进行事务的回滚。
- 当我们抛出的异常不是RunTime及其子类或者Error和其子类的时候,必须根据rollbackfor进行回滚。比如rollbackfor=RuntimeException,而抛出IOException时候,事务是不进行回滚的。
- 当我们抛出的异常不是RunTime及其子类或者Error和其子类的时候,如果嵌套事务中,只要有一个rollbackfor允许回滚,则整个事务回滚。
@Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
三、常用注解
| @Entity | 声明类为实体或表。 |
|---|---|
| @Table | 声明表名。 |
| @Basic | 指定非约束明确的各个字段。 |
| @Embedded | 指定类或它的值是一个可嵌入的类的实例的实体的属性。 |
| @Id | 指定的类的属性,用于识别(一个表中的主键)。 |
| @GeneratedValue | 指定如何标识属性可以被初始化,例如自动、手动、或从序列表中获得的值。 |
| @Transient | 指定的属性,它是不持久的,即:该值永远不会存储在数据库中。 |
| @Column | 指定持久属性栏属性。 |
| @SequenceGenerator | 指定在@GeneratedValue注解中指定的属性的值。它创建了一个序列。 |
| @TableGenerator | 指定在@GeneratedValue批注指定属性的值发生器。它创造了的值生成的表。 |
| @AccessType | 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。 |
| @JoinColumn | 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。 |
| @UniqueConstraint | 指定的字段和用于主要或辅助表的唯一约束。 |
| @ColumnResult | 参考使用select子句的SQL查询中的列名。 |
| @ManyToMany | 定义了连接表之间的多对多一对多的关系。 |
| @ManyToOne | 定义了连接表之间的多对一的关系。 |
| @OneToMany | 定义了连接表之间存在一个一对多的关系。 |
| @OneToOne | 定义了连接表之间有一个一对一的关系。 |
| @NamedQueries | 指定命名查询的列表。 |
| @NamedQuery | 指定使用静态名称的查询。 |
四、基本使用
1. 快速入门
1. 创建SpringJPA项目
2. pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
3. application.yaml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/jpa?serverTimezone=UTC
type: com.zaxxer.hikari.HikariDataSource
# update: 如果表不存在,那么则创建,如果存在则不创建
# create: 每次都创建
# create-drop: 使用完毕之后就删除,开始的时候创建
jpa:
hibernate:
ddl-auto: update
# 展示sql语句
show-sql: true
参数配置介绍:
_create_:每次加载hibernate时都会删除上一次的生成的表,然后根据model类重新生成表,哪怕没有改变,这是导致数据库表数据丢失的一个重要原因_create-drop_:每次加载hibernate时根据model类生成表,但sessionFactory关闭时,表自动删除_update_:首次加载hibernate时根据model类自动建立起表结构(要先建立数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构变了,老数据不删除。注意:当部署到服务器后,表结构不会立即建立起来,应用首次运行后才会建立表结构。_validate_:每次加载hibernate时,验证创建数据库表结构,和数据库表比较,不创建新表,会插入新值
4. 创建实体,建立于数据库表的映射关系
import lombok.Data;
import javax.persistence.*;
@Entity
@Data
@Table(name = "tb_user")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer uid;
@Column
private String uname;
}
主键生成策略:
_TABLE_:会创建一个hibernate的自动主键增长表,通用性_SEQUENCE_:指定增长序列,一般在oracle使用_IDENTITY_:在创建表的时候指定主键为自动增长列,例如mysql就是添加上auto_increment_AUTO_:会根据数据库的类型自动选中自动增长的方式
5. 创建实体接口
import com.springjpa.pojo.Student;
import org.springframework.data.jpa.repository.JpaRepository;
public interface StudentDao extends JpaRepository<Student,Integer> { }
6. 测试
测试使用JPA添加数据
@Autowired
StudentDao studentDao;
@Test
void contextLoads() {
Student student = new Student();
student.setUname("GMF");
studentDao.save(student);
}
查看数据库发现已经由JPA自动帮我们创建了表并且添加数据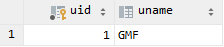
2. 进阶使用
1. 一对一映射
1. 创建实体类,构建之间的映射关系
Wife.java
import lombok.Data;
import javax.persistence.*;
@Entity
@Data
@Table(name = "tb_wife")
public class Wife {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer wid;
@Column
private String wname;
@OneToOne
//name是wife表中的外键
//referencedColumnName: 关联Husband中的主键,可以省略
//wife实体作为一对一映射关系的维护方
@JoinColumn(name = "hid", referencedColumnName = "hid")
private Husband husband;
}
Husband.java
import lombok.Data;
import javax.persistence.*;
@Data
@Entity
@Table(name = "tb_husband")
public class Husband {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer hid;
@Column
private String name;
@OneToOne(mappedBy = "husband")
private Wife wife;
}
2. 创建实体Dao接口
WifeDao.java
public interface WifeDao extends JpaRepository<Wife, Integer> { }
HusbandDao.java
public interface HusbandDao extends JpaRepository<Husband, Integer> { }
3. 测试
@Autowired
HusbandDao husbandDao;
@Autowired
WifeDao wifeDao;
@Test
public void test02(){
Wife wife = new Wife();
wife.setWname("KYN");
Husband husband = new Husband();
husband.setName("GMF");
wifeDao.save(wife);
husbandDao.save(husband);
//设置实体直接的主外键联系
husband.setWife(wife);
wife.setHusband(husband);
//执行更新操作,使内存中的数据与数据库一致
//注意:更新实体之间的映射关系应由维护方操作
wifeDao.save(wife);
}
注意:更新实体之间的映射关系应由维护方操作
查看数据库
tb_husband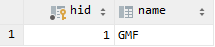
tb_wife
2. 一对多映射
1. 创建实体类,构建一对多的映射关系
Hero.java
import lombok.Data;
import javax.persistence.*;
import java.util.List;
@Data
@Entity
@Table(name = "tb_hero")
public class Hero {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer hid;
@Column
private String hname;
//mappedBy的意思就是“被映射”,即mappedBy这方不用管关联关系,关联关系交给另一方处理
@OneToMany(mappedBy = "hero",fetch = FetchType.EAGER)
private List<Skin> skins;
}
在@oneToMany关系中默认的fetch的Type是Lazy,查询的时候在使用到users数据的时候才会查询,如果session关闭之后才使用的话,会报错。可以修改成EAGER类型
Skin.java
import lombok.Data;
import javax.persistence.*;
@Data
@Entity
@Table(name = "tb_skin")
public class Skin {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
@Column
private String name;
@ManyToOne
@JoinColumn(name = "hid")
private Hero hero;
}
2. 编写测试代码
@Test
public void test03(){
Hero hero = new Hero();
hero.setHname("JJ");
Skin skin1 = new Skin();
skin1.setName("玉剑传说");
skin1.setHero(hero);
Skin skin2 = new Skin();
skin2.setName("未来战士");
skin2.setHero(hero);
heroDao.save(hero);
skinDao.save(skin1);
skinDao.save(skin2);
}
@Test
public void test04(){
Hero hero = heroDao.findById(1).get();
String data = hero.getHname()+"的皮肤有";
for (Skin skinPojo :hero.getSkins()) {
data+=skinPojo.getName()+",";
}
System.out.println(data);
}
3. 多对多映射
1. 创建实体类,构建多对多的映射关系
Student.java
import lombok.Data;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
@Data
@Table(name = "tb_student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer sid;
@Column
private String sname;
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinTable(
name = "tb_stu_tea", //中间表表名
joinColumns = @JoinColumn(name = "stuId",referencedColumnName = "sid"), //当前类对应的表(student)和中间表的关系
inverseJoinColumns = @JoinColumn(name = "teaId",referencedColumnName = "tid")) //Teacher表与中间表的映射关系
private List<Teacher> teachers = new ArrayList<>();
}
关系维护端,负责多对多关系的绑定和解除
- @JoinTable注解的name属性指定关联表的名字,joinColumns指定外键的名字,关联到关系维护端(User)
- inverseJoinColumns指定外键的名字,要关联的关系被维护端(Role)
Teacher.java
import lombok.Data;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Data
@Entity
@Table(name = "tb_teacher")
public class Teacher {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer tid;
@Column
private String tname;
@ManyToMany(cascade = CascadeType.ALL, mappedBy = "teachers")
private List<Student> students = new ArrayList<>();
}
2. 测试代码
@Test
public void test05() {
Student stu1 = new Student();
stu1.setSname("GMF");
Student stu2 = new Student();
stu2.setSname("KYN");
Student stu3 = new Student();
stu3.setSname("ZTL");
Teacher teacher1 = new Teacher();
teacher1.setTname("TXW");
Teacher teacher2 = new Teacher();
teacher2.setTname("GM");
//构建实体之间的关系
stu1.getTeachers().add(teacher1);
stu2.getTeachers().add(teacher1);
stu2.getTeachers().add(teacher2);
stu3.getTeachers().add(teacher2);
teacher1.getStudents().add(stu1);
teacher1.getStudents().add(stu2);
teacher2.getStudents().add(stu2);
teacher2.getStudents().add(stu3);
//teacherDao.save(teacher1);
//teacherDao.save(teacher2);
studentDao.save(stu1);
studentDao.save(stu2);
studentDao.save(stu3);
}
@Test
public void test06() {
List<Student> students = studentDao.findAll();
for (Student student : students) {
System.out.print(student.getSname());
List<Teacher> teachers = student.getTeachers();
for (Teacher teacher : teachers) {
System.out.print(teacher.getTname());
}
System.out.println();
}
}
3. 用法总结
mappedBy总结:
mappedBy的意思就是“被映射”,即mappedBy这方不用管关联关系,关联关系交给另一方处理。
规律:凡是双向关联,mapped必设,因为根本都没必要在2个表中都存在一个外键关联,在数据库中只要定义一边就可以了
- 只有OneToOne、OneToMany、ManyToMany上才有mappedBy属性,ManyToOne不存在该属性;
- mappedBy标签一定是定义在the owned side(被拥有方的),他指向the owning side(拥有方);
- mappedBy的含义,应该理解为,拥有方能够自动维护跟被拥有方的关系; 当然,如果从被拥有方,通过手工强行来维护拥有方的关系也是可以做到的。
- mappedBy跟JoinColumn/JoinTable总是处于互斥的一方,可以理解为正是由于拥有方的关联被拥有方的字段存在,拥有方才拥有了被拥有方。mappedBy这方定义的JoinColumn/JoinTable总是失效的,不会建立对应的字段或者表

若有收获,就点个赞吧
0 人点赞
