一、介绍
1. 诞生背景
我们在开发单机应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用我们学到的Java多线程的18般武艺进行处理,并且可以完美的运行,毫无Bug!
我们现在的应用程序如果只部署一台服务器,那并发量是很差的,如果同时有上万的请求那么很有可能造成服务器压力过大,而瘫痪。
想想双十一 和 三十晚上十点分支付宝红包等业务场景,自然需要用到多台服务器去同时处理这些业务,那么这些服务可能会有上百台同时处理,
但是请我们大家想一想,如果有100台服务器 要处理分红包的业务,现在假设有1亿的红包,1千万个人分,金额随机,那么这个业务场景下是不是必须确保这1千万个人最后分的红包金额总和等于1亿。
如果处理不好每人分到100万,那马云爸爸估计大年初一,就得宣布破产了
2. 问题描述
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题
3. 分布式锁应该具备的条件
在分析分布式锁的三种实现方式之前,先了解一下分布式锁应该具备哪些条件:
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
- 高可用的获取锁与释放锁;
- 高性能的获取锁与释放锁;
- 具备可重入特性;
- 具备锁失效机制,防止死锁;
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
4. 分布式锁主流的实现方案
1. 基于数据库实现分布式锁
1. 介绍
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名、类名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁
2. 实现步骤
- 创建表
- 向表中插入数据:此时因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证肯定只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,也就可以执行方法体内容
- 成功插入则获取锁,执行完成后删除对应的行数据释放锁
这只是使用基于数据库的一种方法,使用数据库实现分布式锁还有很多其他的玩法!
3. 优缺点
- 因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换。
- 不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁。
- 没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据。
- 不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
- 在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂。
- 依赖数据库需要一定的资源开销,性能问题需要考虑。
2. 基于缓存(Redis等)*
1. 选用Redis实现分布式锁的原因
- Redis有很高的性能;
- Redis命令对此支持较好,实现起来比较方便
2. 实现方式
会在后面的内容中介绍
3. 基于Zookeeper
1. 实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
- 创建一个目录mylock;
- 线程A想获取锁就在mylock目录下创建临时顺序节点;
- 获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
- 线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
2. 优点
具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
3. 缺点
因为需要频繁的创建和删除节点,性能上不如Redis方式。
4. Redis 分布式锁和Zookeeper分布式锁的对比
Redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
- 单点的redis能很好地实现分布式锁,如果redis集群,会出现master宕机的情况。如果master宕机,此时锁key还没有同步到slave节点上,会出现机器B从新的master上获取到了一个重复的锁;另外一点就是,如果是Redis获取锁的那个客户端出现 bug 挂了,那么只能等待超时时间之后才能释放锁。
Zookeeper分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小。
- Zookeeper的话,因为创建的是临时znode,只要客户端挂了,znode 就没了,此时就自动释放锁。但是zookeeper也会有弊端,那就是有可能会出现“羊群效应”
二、Redis实现分布式锁步骤
1. Redis实现逻辑
使用Redis命令:_setnx <key> <value>_
为了放置服务器故障导致无法释放锁(死锁),通常我们会设置过期时间
首先想到通过expire设置过期时间(缺乏原子性:如果在setnx和expire之间出现异常,锁也无法释放)
最终我们可以在SET时指定过期时间:_setnx <key> <value> PX <secend>_
_EX second_:设置键的过期时间为 second 秒。_SET key value EX second_效果等同于_SETEX key second value__PX millisecond_:设置键的过期时间为 millisecond 毫秒。_SET key value PX millisecond_效果等同于_PSETEX key millisecond value__NX_:只在键不存在时,才对键进行设置操作。_SET key value NX_效果等同于_SETNX key value__XX_:只在键已经存在时,才对键进行设置操作
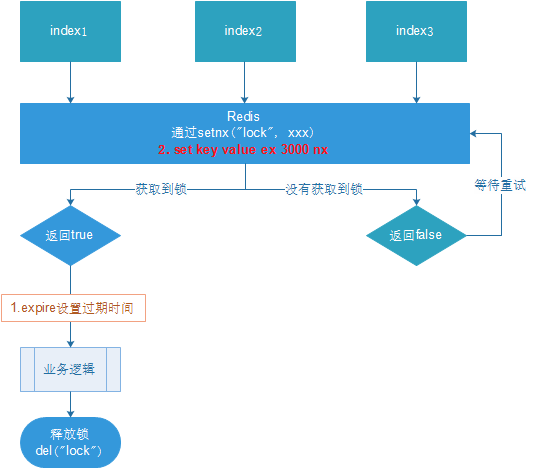
- 多个客户端同时获取锁(setnx)
- 获取成功,执行业务逻辑{从db获取数据,放入缓存},执行完成释放锁(del)
- 其他客户端等待重试
2. Springboot实现逻辑
@GetMapping("/testLock")@ResponseBodypublic String testLock() throws InterruptedException {//设置锁并查看当前锁是否被抢占Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1", 3, TimeUnit.SECONDS);//判断锁是否被抢占if (lock) {//未被抢占,则对num进行增加Object num = redisTemplate.opsForValue().get("num");if (!StringUtils.hasLength(num + "")) {redisTemplate.opsForValue().set("num", "1");}redisTemplate.opsForValue().increment("num");//操作完毕删除(释放)锁redisTemplate.delete("lock");} else {//锁被抢占的情况下,当前线程睡眠0.1秒后再去执行Thread.sleep(100);testLock();}return "添加成功";}
3. 使用UUID优化防止误删
问题描述:当业务时间超过了锁过期时间,导致自己的锁失效,就会释放其他人的锁,然后又一个客户端拿到锁(以此类推,不满足分布式锁的互斥性)
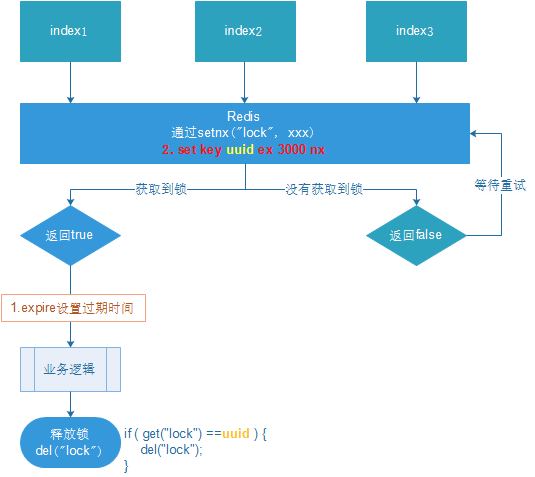
修改代码
@GetMapping("/testLock")
@ResponseBody
public String testLock() throws InterruptedException {
//生成UUID作为该客户端的锁标识
String uuid = UUID.randomUUID().toString();
//设置锁并查看当前锁是否被抢占
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
//判断锁是否被抢占
if (lock) {
//未被抢占,则对num进行增加
Object num = redisTemplate.opsForValue().get("num");
if (!StringUtils.hasLength(num + "")) {
redisTemplate.opsForValue().set("num", "1");
}
redisTemplate.opsForValue().increment("num");
//操作完毕删除(释放)锁(在此之前先判断当前锁的value是否等于客户端的UUID)
if (uuid.equals((String) redisTemplate.opsForValue().get("lock"))){
redisTemplate.delete("lock");
}
} else {
//锁被抢占的情况下,当前线程睡眠0.1秒后再去执行
Thread.sleep(100);
testLock();
}
return "添加成功";
}
注意:
这样的方式删除缺乏原子性
场景:
- index1执行删除时,查询到的lock值确实和uuid相等
- index1执行删除前,lock刚好过期时间已到,被redis自动释放(此时在redis中没有了lock,没有了锁)
- index2获取了lock,index2线程获取到了cpu的资源,开始执行方法
- index1执行删除,此时会把index2的lock删除(因为index1已经经过了uuid的判断具有了删除的权限,这个适合删除的就会时index2的锁)
4. 使用LUA脚本保证删除的原子性
@GetMapping("/testLock")
@ResponseBody
public String testLock() throws InterruptedException {
//生成UUID作为该客户端的锁标识
String uuid = UUID.randomUUID().toString();
//设置锁并查看当前锁是否被抢占
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
//判断锁是否被抢占
if (lock) {
//未被抢占,则对num进行增加
Object num = redisTemplate.opsForValue().get("num");
if (!StringUtils.hasLength(num + "")) {
redisTemplate.opsForValue().set("num", "1");
}
redisTemplate.opsForValue().increment("num");
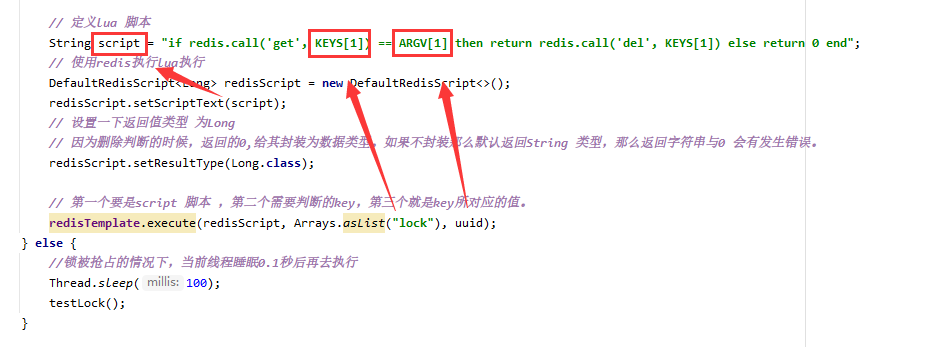
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList("lock"), uuid);
} else {
//锁被抢占的情况下,当前线程睡眠0.1秒后再去执行
Thread.sleep(100);
testLock();
}
return "添加成功";
}
Lua脚本详解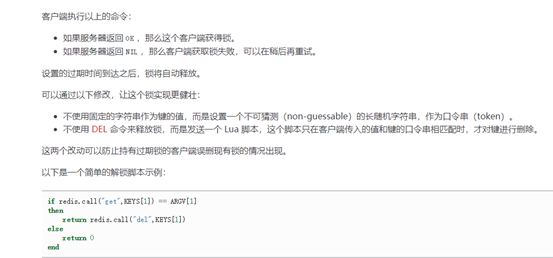
Redis使用(支持)相同的Lua解释器,来运行所有的命令。Redis还保证脚本以原子方式执行:在执行脚本时,不会执行其他脚本或Redis命令。这个语义类似于MULTI(开启事务)/EXEC(触发事务,一并执行事务中的所有命令)。从所有其他客户端的角度来看,脚本的效果要么仍然不可见,要么已经完成
三、Redission分布式锁
1. 简介
1. 基本功能
- Redisson提供了使用Redis的最简单和最便捷的方法;
- 开发人员不需过分关注Redis,集中精力关注业务即可;
- 基于Redis,提供了在Java中具有分布式特性的工具类;
- 使Java中的并发工具包获得了协调多机多线程并发的能力;
2. 支持的Redis配置
Redisson支持多种Redis配置,无论你的Redis是单点、集群、主从还是哨兵模式,它都是支持的。只需要在Redisson的配置文件中,增加相应的配置就可以了
3. 支持的Java实体
Redisson支持多种Java实体,使其具有分布式的特性。我们比较常用的有:AtomicLong(原子Long)、AtomicDouble(原子Double)、PublishSubscribe(发布订阅)等
4. Java分布式锁与同步器
Redisson支持Java并发包中的多种锁,比如:Lock(可重入锁)、FairLock(公平锁)、MultiLock(联锁)、RedLock(红锁)、ReadWriteLock(读写锁)、Semaphore(信号量)、CountDownLatch(闭锁)等。我们注意到这些都是Java并发包中的类,Redisson借助于Redis又重新实现了一套,使其具有了分布式的特性。以后我们在使用Redisson中的这些类的时候,可以跨进程跨JVM去使用。
5. 分布式Java集合
Redisson对Java的集合类也进行了封装,使其具有分布式的特性如:Map、Set、List、Queue、Deque、BlockingQueue等。以后我们就可以在分布式的环境中使用这些集合了
6. 与Spring框架的整合
Redisson可以与Spring大家族中的很多框架进行整合,其中包括:Spring基础框架、Spring Cache、Spring Session、Spring Data Redis、Spring Boot等。在项目中我们可以轻松的与这些框架整合,通过简单的配置就可以实现项目的需求
2. SpringBoot基本使用
git地址:https://github.com/redisson/redisson/tree/master/redisson-spring-boot-starter
导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.14.0</version>
</dependency>
自动注入 RedissionClient.java
@Autowired
RedissonClient redissonClient;
代码实现
@PostMapping("/add")
public String insert(
String key,
String token,
@RequestBody TbUser tbUser) throws InterruptedException {
RLock rLock =redissonClient.getLock("add");
rLock.lock(3000, TimeUnit.SECONDS);//可以阻塞方法(防止死锁设置超时时间)
//锁住
try{
String serverToken = (String) redisTemplate.opsForValue().get(key);
if(serverToken!=null&&serverToken.equals(token)){
Thread.sleep(5000);
this.tbUserService.save(tbUser);
//将原有的token进行删除
redisTemplate.delete(key);
return "success";
}else{
return "error";
}
}catch (Exception e){
e.printStackTrace();
}finally {
//释放锁
rLock.unlock();
}
return "locked";
}
四、总结
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 加锁和解锁必须具有原子性。

若有收获,就点个赞吧
0 人点赞
