一、日志基础知识
1. 从一条更新语句开始
前面我们系统了解了一个查询语句的执行流程,并介绍了执行过程中涉及的处理模块。相信你还记得,一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎
那么,一条更新语句的执行流程又是怎样的呢?
之前你可能经常听 DBA 同事说,MySQL 可以恢复到半个月内任意一秒的状态,惊叹的同时,你是不是心中也会不免会好奇,这是怎样做到的呢?
- 我们还是从一个表的一条更新语句说起,下面是这个表的创建语句,这个表有一个主键 ID 和一个整型字段 c:
mysql> create table T(ID int primary key, c int);-- 如果要将 ID=2 这一行的值加 1,SQL 语句就会这么写:mysql> update T set c=c+1 where ID=2;
前面有跟你介绍过 SQL 语句基本的执行链路,我们先分析下这句话执行的流程: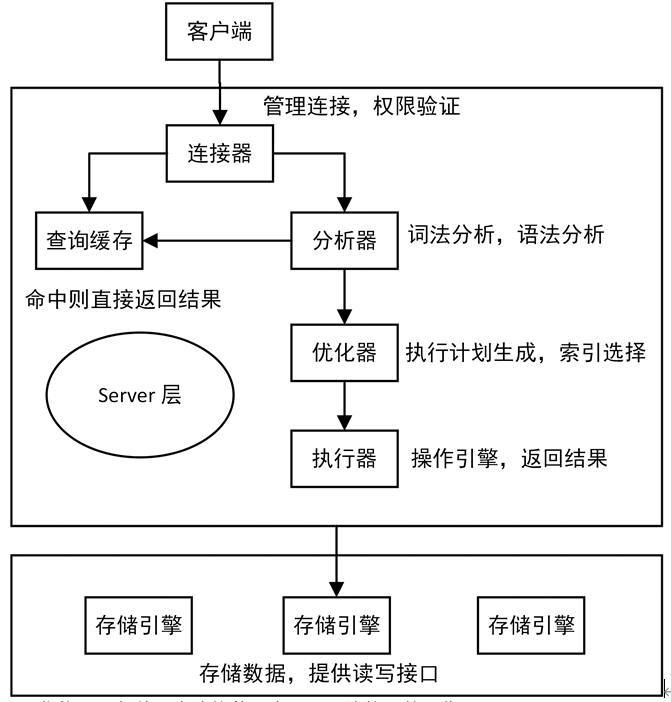
- 你执行语句前要先连接数据库,这是连接器的工作。
- 前面我们说过,在一个表上有更新的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表 T 上所有缓存结果都清空。这也就是我们一般不建议使用查询缓存的原因。
- 接下来,分析器会通过词法和语法解析知道这是一条更新语句。优化器决定要使用 ID 这个索引。然后,执行器负责具体执行,找到这一行,然后更新。
- 与查询流程不一样的是,更新流程还涉及两个重要的日志模块,它们正是我们今天要讨论的主角:redo log(重做日志)和 binlog(归档日志)。如果接触 MySQL,那这两个词肯定是绕不过的,我后面的内容里也会不断地和你强调。不过话说回来,redo log 和 binlog 在设计上有很多有意思的地方,这些设计思路也可以用到你自己的程序里。
2. redo log
1. 引出问题
不知道你还记不记得《孔乙己》这篇文章,酒店掌柜有一个粉板,专门用来记录客人的赊账记录。如果赊账的人不多,那么他可以把顾客名和账目写在板上。但如果赊账的人多了,粉板总会有记不下的时候,这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话,掌柜一般有两种做法:
- 一种做法是直接把账本翻出来,把这次赊的账加上去或者扣除掉;
- 另一种做法是先在粉板上记下这次的账,等打烊以后再把账本翻出来核算。
在生意红火柜台很忙时,掌柜一定会选择后者,因为前者操作实在是太麻烦了。首先,你得找到这个人的赊账总额那条记录。你想想,密密麻麻几十页,掌柜要找到那个名字,可能还得带上老花镜慢慢找,找到之后再拿出算盘计算,最后再将结果写回到账本上。
这整个过程想想都麻烦。相比之下,还是先在粉板上记一下方便。你想想,如果掌柜没有粉板的帮助,每次记账都得翻账本,效率是不是低得让人难以忍受?
在 MySQL 里也有这个问题,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。为了解决这个问题,MySQL 的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
而粉板和账本配合的整个过程,其实就是 MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log(粉板)里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
如果今天赊账的不多,掌柜可以等打烊后再整理。但如果某天赊账的特别多,粉板写满了,又怎么办呢?这个时候掌柜只好放下手中的活儿,把粉板中的一部分赊账记录更新到账本中,然后把这些记录从粉板上擦掉,为记新账腾出空间。
与此类似,InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。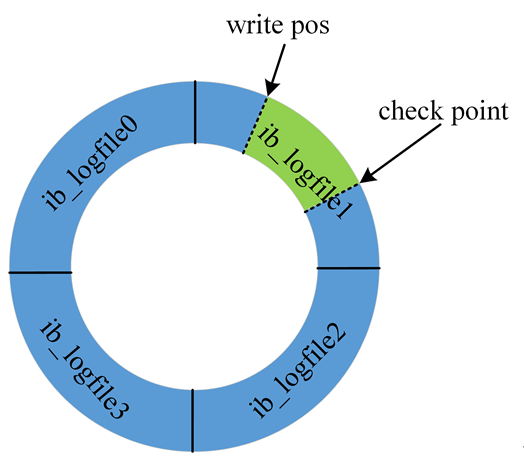
- write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
- write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
- 要理解 crash-safe 这个概念,可以想想我们前面赊账记录的例子。只要赊账记录记在了粉板上或写在了账本上,之后即使掌柜忘记了,比如突然停业几天,恢复生意后依然可以通过账本和粉板上的数据明确赊账账目。
innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘。这个参数建议设置成 1,这样可以保证 MySQL 异常重启之后数据不丢失。
3. binlog(二进制日志)
前面我们讲过,MySQL 整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
我想你肯定会问,为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同:
- redo log是InnoDB引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log是物理日志,记录的是“在某个数据页上做了什么修改”(例如一个数据由5->3->2,只需记住这个数据最终是2即可);binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”,即SQL语句。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
- 两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而innodb存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
有了对这两个日志的概念性理解,我们再来看执行器和 InnoDB 引擎在执行这个简单的 update 语句时的内部流程。
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
下图为 update 语句的执行流程图,图中灰色框表示是在 InnoDB 内部执行的,绿色框表示是在执行器中执行的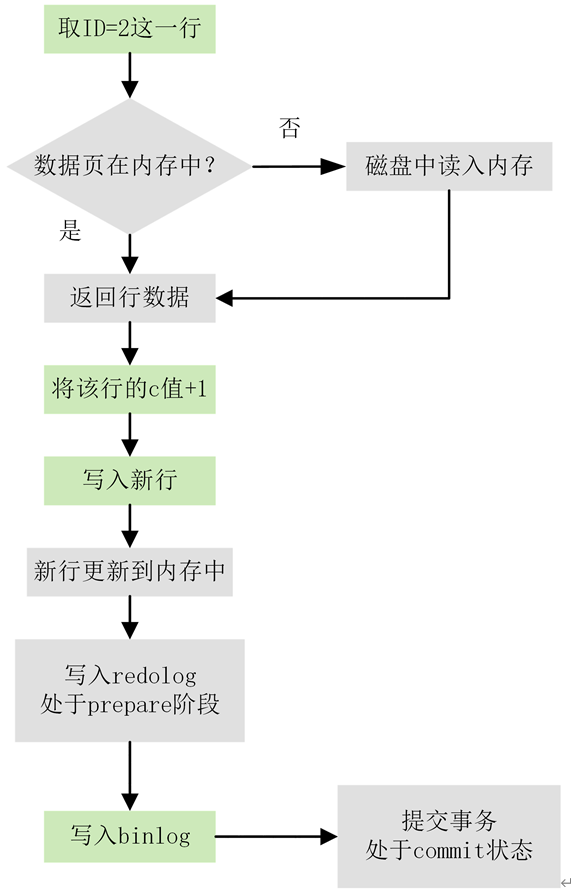
其中将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是两阶段提交(2PC)
1.1 两阶段提交(2PC)
1,MySQL 使用两阶段提交主要解决 binlog 和 redo log 的数据一致性的问题。
2,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。下图为 MySQL 二阶段提交简图:
3,两阶段提交原理描述:
| 3.1 InnoDB redo log 写盘,InnoDB 事务进入 prepare 状态。 3.2如果前面 prepare 成功,binlog 写盘,那么再继续将事务日志持久化到 binlog,如果持久化成功,那么 InnoDB 事务则进入 commit 状态(在 redo log 里面写一个 commit 记录) |
|---|
备注: 每个事务 binlog 的末尾,会记录一个 XID event,标志着事务是否提交成功,也就是说,recovery 过程中,binlog 最后一个 XID event 之后的内容都应该被 purge。
redo log 和 binlog 有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
1.2 数据恢复
1,我们得从文章开头的那个问题说起:怎样让数据库恢复到半个月内任意一秒的状态?前面我们说过了,binlog 会记录所有的逻辑操作,并且是采用“追加写”的形式。如果你的 DBA 承诺说半个月内可以恢复,那么备份系统中一定会保存最近半个月的所有 binlog,同时系统会定期做整库备份。这里的“定期”取决于系统的重要性,可以是一天一备,也可以是一周一备。
2,当需要恢复到指定的某一秒时,比如某天下午两点发现中午十二点有一次误删表,需要找回数据,那你可以这么做:
| 2.1首先,找到最近的一次全量备份,如果你运气好,可能就是昨天晚上的一个备份,从这个备份恢复到临时库; 2.2然后,从备份的时间点开始,将备份的 binlog 依次取出来,重放到中午误删表之前的那个时刻。 2.3这样你的临时库就跟误删之前的线上库一样了,然后你可以把表数据从临时库取出来,按需要恢复到线上库去。 |
|---|
1.3 小结
1.3.1 redo log与binlog的区别
第一:redo log是在InnoDB存储引擎层产生,而binlog是MySQL数据库的上层产生的,并且二进制日志不仅仅针对INNODB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
第二:两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,其记录是对应的SQL语句。而innodb存储引擎层面的重做日志是物理日志。
第三:两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而innodb存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
二进制日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于innodb存储引擎的重做日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
第四:binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redo log是循环使用。
第五:binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
1.3.2 数据写入后的最终落盘,是从 redo log 更新过来的还是从 buffer pool 更新过来的呢?
实际上,redo log 并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在由 redo log 更新过去数据最终落盘的情况。
数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程与 redo log 毫无关系。
在崩溃恢复场景中,InnoDB 如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让 redo log 更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
1.3.3 为什么日志需要“两阶段提交”
由于 redo log 和 binlog 是两个独立的逻辑,如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序。我们看看这两种方式会有什么问题。
仍然用前面的 update 语句来做例子。假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。
然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
你可能会说,这个概率是不是很低,平时也没有什么动不动就需要恢复临时库的场景呀?
其实不是的,不只是误操作后需要用这个过程来恢复数据。当你需要扩容的时候,也就是需要再多搭建一些备库来增加系统的读能力的时候,现在常见的做法也是用全量备份加上应用 binlog 来实现的,这个“不一致”就会导致你的线上出现主从数据库不一致的情况。
简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
1.3.4 redo log buffer 是什么?是先修改内存,还是先写 redo log 文件?
在一个事务的更新过程中,日志是要写多次的。比如下面这个事务:
| begin; INSERT INTO T1 VALUES (‘1’, ‘1’); INSERT INTO T2 VALUES (‘1’, ‘1’); commit; |
|---|
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没 commit 的时候就直接写到 redo log 文件里。
因此就需要 redo log buffer 出场了,它就是一块内存,用来先存 redo 日志的。也就是说,在执行第一个 insert 的时候,数据的内存被修改了,redo log buffer 也写入了日志。
但是,真正把日志写到 redo log 文件,是在执行 commit 语句的时候做的。
二、Buffer pool
2.1 简介
1,buffer pool 是 innodb的数据缓存,保存了 data page、index page、undo page、insert buffer page、adaptive hash index、data dictionary、lock info。buffer pool绝大多数page都是 data page(包括index page)。innodb 还有日志缓存 log buffer,保存redo log。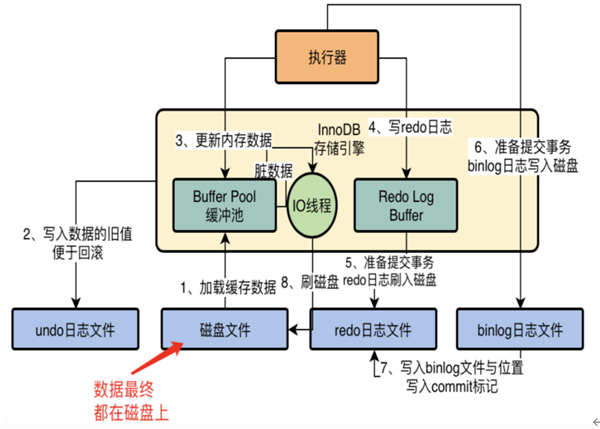
2,但是我们在对数据库执行增删改操作的时候,不可能直接更新磁盘上的数据的,因为如果你对磁盘进行随机读写操作,那速度是相当的慢,随便一个大磁盘文件的随机读写操作,可能都要几百毫秒。如果要是那么搞的话,可能你的数据库每秒也就只能处理几百个请求了! 在对数据库执行增删改操作的时候,实际上主要都是针对内存里的Buffer Pool中的数据进行的,也就是实际上主要是对数据库的内存里的数据结构进行了增删改,如下图所示。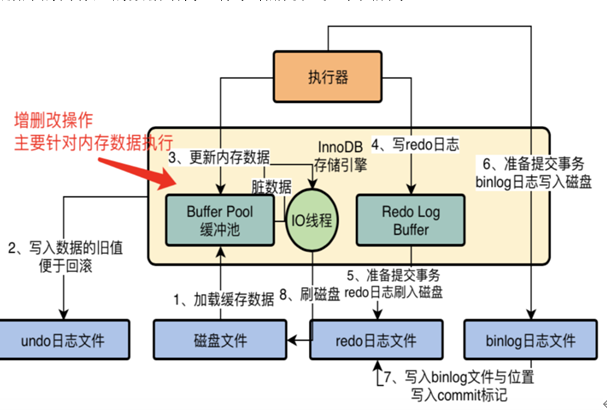
3,其实每个人都担心一个事,就是你在数据库的内存里执行了一堆增删改的操作,内存数据是更新了,但是这个时候如果数据库突然崩溃了,那么内存里更新好的数据不是都没了吗? MySQL就怕这个问题,所以引入了一个redo log机制,你在对内存里的数据进行增删改的时候,他同时会把增删改对应的日志写入redo log中,如下图。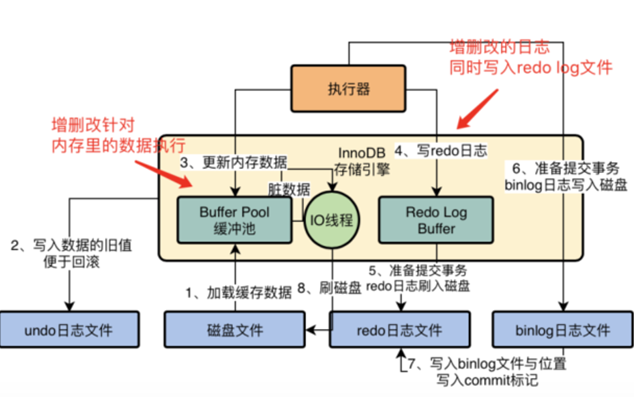
4,万一你的数据库突然崩溃了,没关系,只要从redo log日志文件里读取出来你之前做过哪些增删改操作,瞬间就可以重新把这些增删改操作在你的内存里执行一遍,这就可以恢复出来你之前做过哪些增删改操作了。 当然对于数据更新的过程,他是有一套严密的步骤的,还涉及到undo log、binlog、提交事务、buffer pool脏数据刷回磁盘,等等。
5,小结
Buffer Pool是数据库中我们第一个必须要搞清楚的核心组件,因为增删改操作首先就是针对这个内存中的Buffer Pool里的数据执行的,同时配合了后续的redo log、刷磁盘等机制和操作。
所以Buffer Pool就是数据库的一个内存组件,里面缓存了磁盘上的真实数据,然后我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的。
2.2 Buffer Pool内存数据结构
1、如何配置你的Buffer Pool的大小?
我们应该如何配置你的Buffer Pool到底有多大呢? 因为Buffer Pool本质其实就是数据库的一个内存组件,你可以理解为他就是一片内存数据结构,所以这个内存数据结构肯定是有一定的大小的,不可能是无限大的。 这个Buffer Pool默认情况下是128MB,还是有一点偏小了,我们实际生产环境下完全可以对Buffer Pool进行调整。 比如我们的数据库如果是16核32G的机器,那么你就可以给Buffer Pool分配个2GB的内存,使用下面的配置就可以了。 [server] innodb_buffer_pool_size = 2147483648 如果你不知道数据库的配置文件在哪里以及如何修改其中的配置,那建议可以先在网上搜索一些MySQL入门的资料去看看,其实这都是最基础和简单的。 我们先来看一下下面的图,里面就画了数据库中的Buffer Pool内存组件
2、数据页:MySQL中抽象出来的数据单位
假设现在我们的数据库中一定有一片内存区域是Buffer Pool了,那么我们的数据是如何放在Buffer Pool中的?
我们都知道数据库的核心数据模型就是 表+字段+行 的概念,所以大家觉得我们的数据是一行一行的放在Buffer Pool里面的吗? 这就明显不是了,实际上MySQL对数据抽象出来了一个数据页的概念,他是把很多行数据放在了一个数据页里,也就是说我们的磁盘文件中就是会有很多的数据页,每一页数据里放了很多行数据,如下图所示。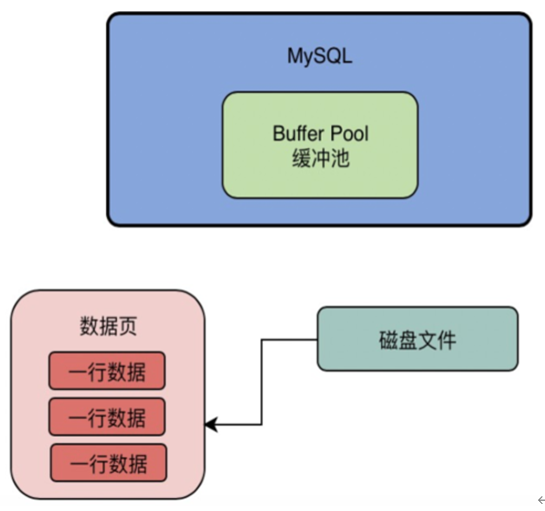
所以实际上假设我们要更新一行数据,此时数据库会找到这行数据所在的数据页,然后从磁盘文件里把这行数据所在的数据页直接给加载到Buffer Pool里去。 也就是说,Buffer Pool中存放的是一个一个的数据页,如下图。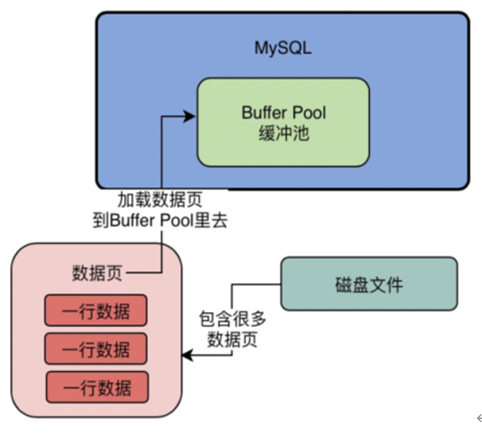
3、磁盘上的数据页和Buffer Pool中的缓存页是如何对应起来的?
实际上默认情况下,磁盘中存放的数据页的大小是16KB,也就是说,一页数据包含了16KB的内容。 而Buffer Pool中存放的一个一个的数据页,我们通常叫做缓存页,因为毕竟Buffer Pool是一个缓冲池,里面的数据都是从磁盘缓存到内存去的。 而Buffer Pool中默认情况下,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应起来的,都是16KB。 我们看下图,我给图中的Buffer Pool标注出来了他的内存大小,假设他是128MB吧,然后数据页的大小是16KB。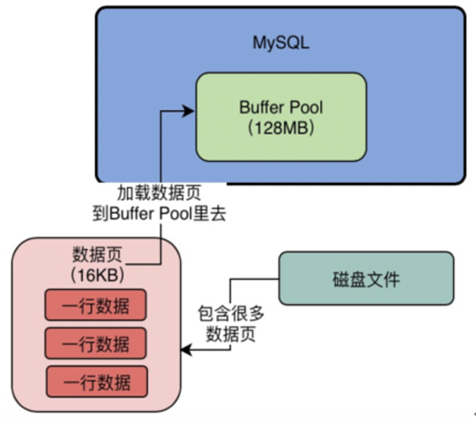
4、缓存页对应的描述信息是什么?
对于每个缓存页,他实际上都会有一个描述信息,这个描述信息大体可以认为是用来描述这个缓存页的。 比如包含如下的一些东西:这个数据页所属的表空间、数据页的编号、这个缓存页在Buffer Pool中的地址以及别的一些杂七杂八的东西。 每个缓存页都会对应一个描述信息,这个描述信息本身也是一块数据,在Buffer Pool中,每个缓存页的描述数据放在最前面,然后各个缓存页放在后面。所以此时我们看下面的图,Buffer Pool实际看起来大概长这个样子。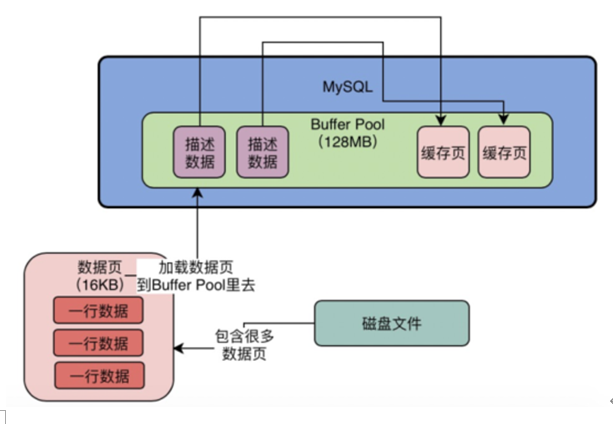
而且这里我们要注意一点,Buffer Pool中的描述数据大概相当于缓存页大小的5%左右,也就是每个描述数据大概是800个字节左右的大小,然后假设你设置的buffer pool大小是128MB,实际上Buffer Pool真正的最终大小会超出一些,可能有个130多MB的样子,因为他里面还要存放每个缓存页的描述数据。
5,思考
对于Buffer Pool而言,他里面会存放很多的缓存页以及对应的描述数据,那么假设Buffer Pool里的内存都用尽了,已经没有足够的剩余内存来存放缓存页和描述数据了,此时Buffer Pool里就一点内存都没有了吗?还是说Buffer Pool里会残留一些内存碎片呢? 如果你觉得Buffer Pool里会有内存碎片的话,那么你觉得应该怎么做才能尽可能减少Buffer Pool里的内存碎片呢?
2.3 在生产环境中设置Buffer Pool
1、生产环境中应该给buffer pool设置多少内存?
- 首先考虑第一个问题,我们现在数据库部署在一台机器上,这台机器可能有个8G、16G、32G、64G、128G的内存大小,那么此时buffer pool应该设置多大呢? 有的人可能会想,假设我有32G内存,那么给buffer pool设置个30GB得了,这样的话,MySQL大量的crud操作都是基于内存来执行的,性能那是绝对高! 这么想就大错特错了,虽然你的机器有32GB的内存,但是你的操作系统内核就要用掉起码几个GB的内存!你的机器上可能还有别的东西在运行!你的数据库里除了buffer pool是不是还有别的内存数据结构!所以上面那种想法是绝对不可取的! 如果你胡乱设置一个特别大的内存给buffer,会导致你的mysql启动失败的,他启动的时候就发现操作系统的内存根本不够用! 所以通常来说,我们建议一个比较合理的、健康的比例,是给buffer pool设置你的机器内存的50%~60%左右 比如你有32GB的机器,那么给buffer设置个20GB的内存,剩下的留给OS和其他人来用,这样比较合理一些。 假设你的机器是128GB的内存,那么buffer pool可以设置个80GB左右,大概就是这样的一个规则。
2、buffer pool总大小=(chunk大小 * buffer pool数量)的2倍数
- 接着确定了buffer pool的总大小之后,就得考虑一下设置多少个buffer pool,以及chunk的大小。 此时有一个很关键的公式:buffer pool总大小 = (chunk大小 buffer pool数量) 的倍数 比如默认的chunk大小是128MB,那么此时如果你的机器的内存是32GB,你打算给buffer pool总大小在20GB左右,此时你的buffer pool的数量应该是多少个呢?
- 假设你的buffer pool的数量是16个,这是没问题的,那么此时chunk大小 buffer pool的数量 = 16 128MB = 2048MB,然后buffer pool总大小如果是20GB,此时buffer pool总大小就是2048MB的10倍,这就符合规则了。 当然,此时你可以设置多一些buffer pool数量,比如设置32个buffer pool,那么此时buffer pool总大小(20GB)就是(chunk大小128MB 32个buffer pool)的5倍,也是可以的。 那么此时你的buffer pool大小就是20GB,然后buffer pool数量是32个,每个buffer pool的大小是640MB,然后每个buffer pool包含5个128MB的chunk,算下来就是这么一个结果了。
3、一点总结
- 数据库在生产环境运行时,必须根据机器的内存设置合理的buffer pool的大小,然后设置buffer pool的数量,这样可以尽可能的保证你的数据库的高性能和高并发能力。 在线上运行时,buffer pool是有多个的,每个buffer pool里多个chunk但是共用一套链表数据结构,然后执 行crud的时候,就会不停的加载磁盘上的数据页到缓存页里来,然后会查询和更新缓存页里的数据,同时维护一系列的链表结构。 然后后台线程定时根据lru链表和flush链表,去把一批缓存页刷入磁盘释放掉这些缓存页,同时更新free链表。 如果执行crud的时候发现缓存页都满了,没法加载自己需要的数据页进缓存,此时就会把lru链表冷数据区域的缓存页刷入磁盘,然后加载自己需要的数据页进来。 整个buffer pool的结构设计以及工作原理,就是上面我们总结的这套东西了,大家只要理解了这个,首先你对MySQL执行crud的时候,是如何在内存里查询和更新数据的,你就彻底明白了。
4、SHOW ENGINE INNODB STATUS
- 当你的数据库启动之后,你随时可以通过上述命令,去查看当前innodb里的一些具体情况,执行SHOW ENGINE INNODB STATUS就可以了。此时你可能会看到如下一系列的东西:
| Total memory allocated xxxx; Dictionary memory allocated xxx Buffer pool size xxxx Free buffers xxx Database pages xxx Old database pages xxxx Modified db pages xx Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young xxxx, not young xxx xx youngs/s, xx non-youngs/s Pages read xxxx, created xxx, written xxx xx reads/s, xx creates/s, 1xx writes/s Buffer pool hit rate xxx / 1000, young-making rate xxx / 1000 not xx / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: xxxx, unzip_LRU len: xxx I/O sum[xxx]:cur[xx], unzip sum[16xx:cur[0] |
|---|
- 下面解释一下这里的东西,主要讲解这里跟buffer pool相关的一些东西。
| Total memory allocated,这就是说buffer pool最终的总大小是多少 Buffer pool size,这就是说buffer pool一共能容纳多少个缓存页 Free buffers,这就是说free链表中一共有多少个空闲的缓存页是可用的 Database pages和Old database pages,就是说lru链表中一共有多少个缓存页,以及冷数据区域里的缓存页数量 Modified db pages,这就是flush链表中的缓存页数量 Pending reads和Pending writes,等待从磁盘上加载进缓存页的数量,还有就是即将从lru链表中刷入磁盘的数量、即将从flush链表中刷入磁盘的数量 Pages made young和not young,这就是说已经lru冷数据区域里访问之后转移到热数据区域的缓存页的数量,以及在lru冷数据区域里1s内被访问了没进入热数据区域的缓存页的数量 youngs/s和not youngs/s,这就是说每秒从冷数据区域进入热数据区域的缓存页的数量,以及每秒在冷数据区域里被访问了但是不能进入热数据区域的缓存页的数量 Pages read xxxx, created xxx, written xxx,xx reads/s, xx creates/s, 1xx writes/s,这里就是说已经读取、创建和写入了多少个缓存页,以及每秒钟读取、创建和写入的缓存页数量 Buffer pool hit rate xxx / 1000,这就是说每1000次访问,有多少次是直接命中了buffer pool里的缓存的 young-making rate xxx / 1000 not xx / 1000,每1000次访问,有多少次访问让缓存页从冷数据区域移动到了热数据区域,以及没移动的缓存页数量 LRU len:这就是lru链表里的缓存页的数量 I/O sum:最近50s读取磁盘页的总数 I/O cur:现在正在读取磁盘页的数量 |
|---|
- 执行 show engine innodb status\G 时,显示的信息不全,DEADLOCK相关信息太多,后面的都没了
原因:
这是mysql客户端的一个bug:BUG#19825,交互式客户端限制了输出信息最大为 64KB,因此更多的信息无法显示。
- 解决方法有两种:
| 1. 启用 innodb_status_file 修改 my.cnf,增加类似下面一行 innodb_status_file = 1 就可以了。 2. 启用 innodb_monitor mysqld在线运行时,创建 innodb_monitor 表,即可记录相关信息到日志文件 mysql> create table innodb_monitor ( id int ) engine = innodb; 相关的信息就会输出到 .err 日志文件里了。 |
|---|
2.4 大查询会不会把内存用光?
1,由于 MySQL 采用的是边算边发的逻辑,因此对于数据量很大的查询结果来说,不会在 server 端保存完整的结果集。所以,如果客户端读结果不及时,会堵住 MySQL 的查询过程,但是不会把内存打爆。
2,而对于 InnoDB 引擎内部,由于有淘汰策略,大查询也不会导致内存暴涨。并且,由于 InnoDB 对 LRU 算法做了改进,冷数据的全表扫描,对 Buffer Pool 的影响也能做到可控。
2.4.1 全表扫描对 InnoDB 的影响
1,之前介绍 WAL 机制的时候,和你分析了 InnoDB 内存的一个作用,是保存更新的结果,再配合 redo log,就避免了随机写盘。
2,内存的数据页是在 Buffer Pool (BP) 中管理的,在 WAL 里 Buffer Pool 起到了加速更新的作用。而实际上,Buffer Pool 还有一个更重要的作用,就是加速查询。
3,有同学问道,由于有 WAL 机制,当事务提交的时候,磁盘上的数据页是旧的,那如果这时候马上有一个查询要来读这个数据页,是不是要马上把 redo log 应用到数据页呢?
- 答案是不需要。因为这时候内存数据页的结果是最新的,直接读内存页就可以了。你看,这时候查询根本不需要读磁盘,直接从内存拿结果,速度是很快的。所以说,Buffer Pool 还有加速查询的作用。
4,而 Buffer Pool 对查询的加速效果,依赖于一个重要的指标,即:内存命中率。
你可以在 show engine innodb status 结果中,查看一个系统当前的 BP 命中率。一般情况下,一个稳定服务的线上系统,要保证响应时间符合要求的话,内存命中率要在 99% 以上。
5,执行 show engine innodb status ,可以看到“Buffer pool hit rate”字样,显示的就是当前的命中率。比如图 5 这个命中率,就是 100.0%。
图 5 show engine innodb status 显示内存命中率
6,如果所有查询需要的数据页都能够直接从内存得到,那是最好的,对应的命中率就是 100%。但,这在实际生产上是很难做到的。
7,InnoDB Buffer Pool 的大小是由参数 innodb_buffer_pool_size 确定的,一般建议设置成可用物理内存的 60%~80%。
8,在大约十年前,单机的数据量是上百个 G,而物理内存是几个 G;现在虽然很多服务器都能有 128G 甚至更高的内存,但是单机的数据量却达到了 T 级别。所以,innodb_buffer_pool_size 小于磁盘的数据量是很常见的。如果一个 Buffer Pool 满了,而又要从磁盘读入一个数据页,那肯定是要淘汰一个旧数据页的。
2.4.2 LRU算法
1,InnoDB 内存管理用的是最近最少使用 (Least Recently Used, LRU) 算法,这个算法的核心就是淘汰最久未使用的数据。
下图是一个 LRU 算法的基本模型。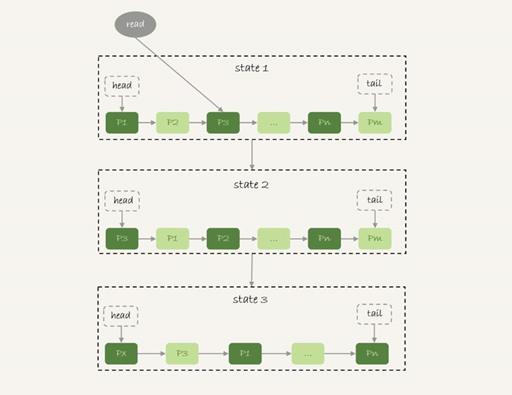
2,InnoDB 管理 Buffer Pool 的 LRU 算法,是用链表来实现的。
| 1,在图 6 的状态 1 里,链表头部是 P1,表示 P1 是最近刚刚被访问过的数据页;假设内存里只能放下这么多数据页; 2,这时候有一个读请求访问 P3,因此变成状态 2,P3 被移到最前面; 3,状态 3 表示,这次访问的数据页是不存在于链表中的,所以需要在 Buffer Pool 中新申请一个数据页 Px,加到链表头部。但是由于内存已经满了,不能申请新的内存。于是,会清空链表末尾 Pm 这个数据页的内存,存入 Px 的内容,然后放到链表头部。 4,从效果上看,就是最久没有被访问的数据页 Pm,被淘汰了。 |
|---|
3,这个算法乍一看上去没什么问题,但是如果考虑到要做一个全表扫描,会不会有问题呢?
| 1,假设按照这个算法,我们要扫描一个 200G 的表,而这个表是一个历史数据表,平时没有业务访问它。 2,那么,按照这个算法扫描的话,就会把当前的 Buffer Pool 里的数据全部淘汰掉,存入扫描过程中访问到的数据页的内容。也就是说 Buffer Pool 里面主要放的是这个历史数据表的数据。 3,对于一个正在做业务服务的库,这可不妙。你会看到,Buffer Pool 的内存命中率急剧下降,磁盘压力增加,SQL 语句响应变慢。 |
|---|
4,所以,InnoDB 不能直接使用这个 LRU 算法。实际上,InnoDB 对 LRU 算法做了改进。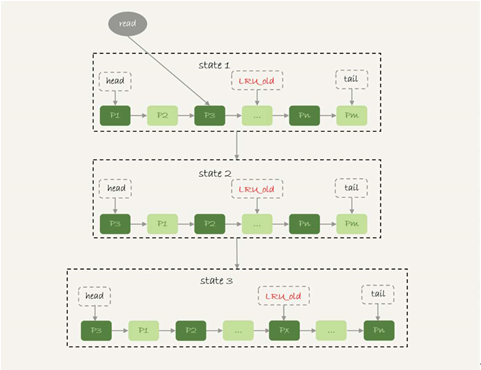
5,在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。图中 LRU_old 指向的就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。
6,改进后的 LRU 算法执行流程变成了下面这样。
| 1,图 7 中状态 1,要访问数据页 P3,由于 P3 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部,变成状态 2。 2,之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 Pm,但是新插入的数据页 Px,是放在 LRU_old 处。 3,处于 old 区域的数据页,每次被访问的时候都要做下面这个判断: - 若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部; - 如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。 |
|---|
7,这个策略,就是为了处理类似全表扫描的操作量身定制的。还是以刚刚的扫描 200G 的历史数据表为例,我们看看改进后的 LRU 算法的操作逻辑:
| 1,扫描过程中,需要新插入的数据页,都被放到 old 区域 ; 2,一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域; 3,再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。 |
|---|
8,可以看到,这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了 Buffer Pool,但是对 young 区域完全没有影响,从而保证了 Buffer Pool 响应正常业务的查询命中率。
3 MySql日志操作
3.1 redo log的操作
3.1.1 日志大小设置
1,显示当前redo log的基本配置
| show variables like ‘%innodb_log_file%’; |
|---|
- innodb_log_files_in_group:日志文件的数量,默认是2
- innodb_log_file_size:日志文件的大小,默认是48M
2,一般太小的logfile size的表现情况就是checkpoint比较频繁,导致刷新dirty page到磁盘的次数增加,在刷新时会使整个系统变得很慢.所以这种情况要尽量避免.直接在my.ini(windows)或者my.cnf(linux)直接设置
| innodb_log_files_in_group =4 innodb_log_file_size =1024M |
|---|
3.1.2 日志操作设置
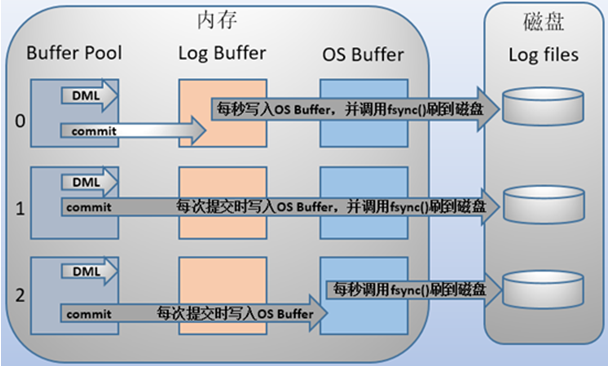
1,redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
-在概念上,innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务日志写入到磁盘上的redo log file和undo log file中进行持久化。
2,为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(即fsync()系统调用)。因为MariaDB/MySQL是工作在用户空间的,MariaDB/MySQL的log buffer处于用户空间的内存中。要写入到磁盘上的log file中(redo:ib_logfileN文件,undo:share tablespace或.ibd文件),中间还要经过操作系统内核空间的os buffer,调用fsync()的作用就是将OS buffer中的日志刷到磁盘上的log file中。
3,可以通过innodb_flush_log_at_trx_commit设置相关策略
| # 查看 select @@innodb_flush_log_at_trx_commit; # 设置 SET GLOBAL innodb_flush_log_at_trx_commit=0; |
|---|
3.2 binlog的操作
3.2.1 二进制日志的基本作用
1,复制:使用二进制日志,可以把对服务器所做的更改以流式方式传输到另一台服务器上。从(slave)服务器充当镜像副本,也可用于分配负载。接收写入的服务器称为(master)服务器
2,时间点恢复:
3.2.2 启动二进制日志
1,查看二进制日志情况
| show variables like ‘%log_bin%’ |
|---|
第一个参数是打开binlog日志
第二个参数是binlog日志的基本文件名,后面会追加标识来表示每一个文件
第三个参数指定的是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录
2,进入到my.ini中进行配置
| # 打开binlog log_bin=mysql-binlog # Server Id.数据库服务器id,这个id用来在主从服务器中标记唯一mysql服务器 server-id=1 |
|---|
3,重启mysql
4,可以看到二进制日志的相关文件
| 1、二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件 2、二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句select)语句事件。 |
|---|
3.2.3 二进制日志的查看
1、查看所有binlog日志列表
| mysql> show master logs; |
|---|
2、查看master状态,即最后(最新)一个binlog日志的编号名称,及其最后一个操作事件pos结束点(Position)值
| show master status; |
|---|
3、刷新log日志,自此刻开始产生一个新编号的binlog日志文件
| flush logs; |
|---|
4、使用show binlog events命令查看
4.1 命令模板
| show binlog events [IN ‘log_name’] [FROM pos] [LIMIT [offset,] row_count]; |
|---|
- IN ‘log_name’ 指定要查询的binlog文件名(不指定就是第一个binlog文件)
- FROM pos 指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)
- LIMIT [offset,] 偏移量(不指定就是0)
- row_count 查询总条数(不指定就是所有行)
4.2 查看指定文件的路径,从0行开始,偏移2行,查询10条
| show binlog events in ‘mysql-binlog.000001’ from 0 limit 2,10\G; |
|---|
3.2.4 通过二进制日志进行恢复
1,基本命令格式
| mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码数据库名 |
|---|
2,常用参数
—start-position=875 起始pos点
—stop-position=954 结束pos点
—start-datetime=”2016-9-25 22:01:08” 起始时间点
—stop-datetime=”2019-9-25 22:09:46” 结束时间点
—database=codehui 指定只恢复codehui数据库(一台主机上往往有多个数据库,只限本地log日志)
3,恢复案例
- 首先从日志中导出sql语句
| mysqlbinlog —start-position=0 —stop-position=10597 mysql-binlog.000001 > e:\\update.sql |
|---|
- 清除原有的日志(不然会引起原有日志的混乱)
| RESET MASTER |
|---|
- 载入备份的sql语句,进行还原
| mysql -uroot -p -v < e:\\update.sql |
|---|
3.2.5 二进制日志的清除
1.自动删除
- 永久生效:修改mysql的配置文件my.cnf,添加binlog过期时间的配置项:expire_logs_days=30,然后重启mysql,这个有个致命的缺点就是需要重启mysql。
- 临时生效:进入mysql,用以下命令设置全局的参数:set global expire_logs_days=30;(上面的数字30是保留30天的意思。)
2.手动删除,可以直接删除binlog文件,但是可以通过mysql提供的工具来删除更安全,因为purge会更新mysql-bin.index中的条目,而直接删除的话,mysql-bin.index文件不会更新。mysql-bin.index的作用是加快查找binlog文件的速度。
| RESET MASTER; — 删除所有binlog日志,新日志编号从头开始 PURGE MASTER LOGS TO ‘mysql-bin.010’; — 删除 mysql-bin.010 之前的所有日志 PURGE MASTER LOGS BEFORE ‘2020-04-14 22:46:26’; — 删除2020-04-14 22:46:26之前产生的所有日志 PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ), INTERVAL 3 DAY); — 清除3天前的 binlog |
|---|
3.2.6 关于备份
1,可以设置每周定时进行一次sql语句的导出
2,然后日志的过期时间就设置成7天

若有收获,就点个赞吧
0 人点赞
