词性标注常用策略
- 规则方法:
- 词典提供候选词性
- 人工整理标注规则
- 基于错误驱动的方法
- 错误驱动学习规则
- 利用规则重新标注词性
- 统计方法
- 问题的形式化描述
- 建立统计模型
- HMM方法
- 最大墒方法
- 条件随机场方法
- 结构化支持向量机方法
决定词性的因素
- 上下文词性
- 上下文词意
隐马尔可夫模型
- 有限视野
- 时间独立
- 输出独立性
给定一个观察序列,找到最好的隐藏状态序列
概率
- 根据模型得到的状态转移概率
- 基于状态和模型得到的输出概率
使用Viterbi算法求解概率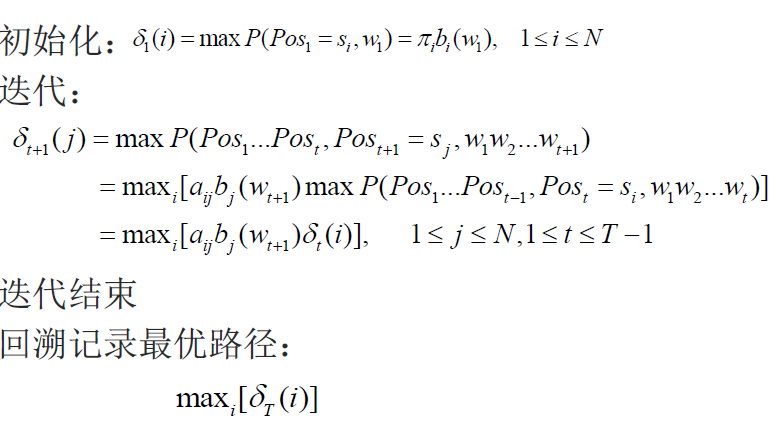

参数学习策略
极大似然估计(有标注预料)
Welch-Baum 算法 (无指导学习参数)
https://www.cnblogs.com/yifanrensheng/p/12684732.html
需要在没有标注的情况下进行学习
训练的目标就是通过当前的模型生成可见序列的概率最大
当前可见序列概率最大就是所有的可能隐藏状态下生成的概率之和最大
再转化条件概率得到基于当前模型得到隐藏状态,以及结合隐藏状态和模型得到可见序列的概率
问题就在于要遍历所有的可能的隐藏状态导致计算量太大
进而进行了转化为一个前向概率和后向概率,把可见序列分成了两个部分。对应的概率就是alpha和beta
进一步的定义了状态转移的概率以及当前时刻所处状态的概率
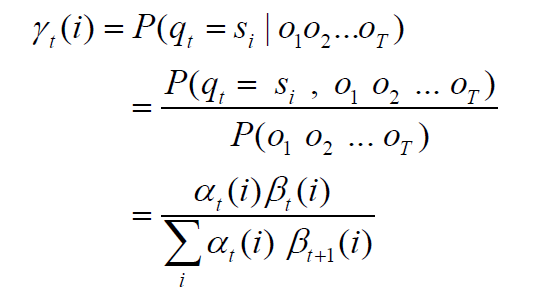
某个时刻从Si转移到Sj的概率就可以看作是状态转移概率除于时刻处于Si的概率即aij
(同时需要对所有的时刻进行累加)

CRF
这一块全都没看懂,崩溃了
生成模型和判别模型的区别
https://www.zhihu.com/question/20446337

若有收获,就点个赞吧
0 人点赞
