聚类任务
目标:将数据样本划分为若干个通常不相交的“簇”(cluster)
即可找寻数据内在的分布结构。也作为分类学习任务中提取特征、判断类别的重要支撑
性能度量

距离计算
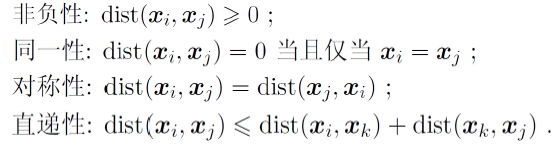
原型聚类
亦称“基于原型的聚类”(prototype-based clustering)
假设:聚类结构能通过一组原型刻画
过程:先对原型初始化,然后对原型进行迭代更新求解
代表:k均值聚类,学习向量量化(LVQ),高斯混合聚类
Kmeans

LVQ

密度聚类
亦称“基于密度的聚类”(density-based clustering)
假设:聚类结构能通过样本分布的紧密程度确定
过程:从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇
代表:DBSCAN, OPTICS, DENCLUE
DBSCAN
核心对象:邻域的样本多到一定程度
密度直达:邻域样本和核心对象,且可以传递
密度可达:传递成为密度可达
密度相连:不同方向
聚类的时候就随机选择一个核心对象,把密度可达的认为是一个等价类
然后删除这个等价类的成员,重复操作
层次聚类
假设:能够产生不同粒度的聚类结果
过程:在不同层次对数据集进行划分,从而形成树形的聚类结构
代表:AGNES (自底向上),DIANA (自顶向下)
AGNES
假设每一个样本都是一个簇,然后合并最接近的两个样本

若有收获,就点个赞吧
0 人点赞
