句法分析类似于在自动机里学习的上下文无关语言,直接使用推导式子一点点的推导到终结字符组成的串
PCFG:产生式是有概率的,对于一个字符串可能使用不同的产生式序列,对应的就会有不同大小的概率
- 语法从哪里来?树库中抽取
- 概率怎么学习?极大似然估计,无监督方法(EM估计)
- 极大似然估计就是直接统计,A推导到B的概率除于A的所有推导
- 乔姆斯基范式,即每一个推导要么是非终止符推导到终止符,要么是一个推导到两个
- 怎么解码decoding?类似于HMM里的模型似然计算,太复杂了
- 向内算法
- 向外算法
向内算法
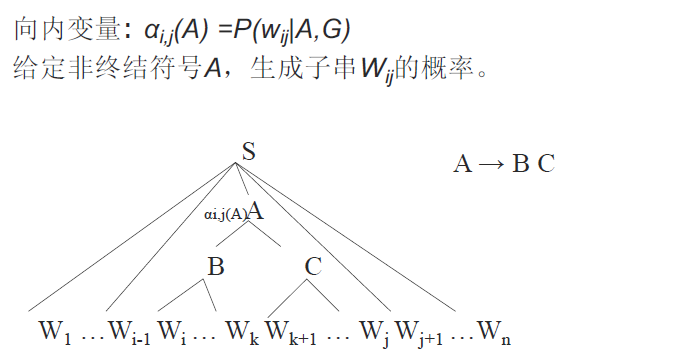
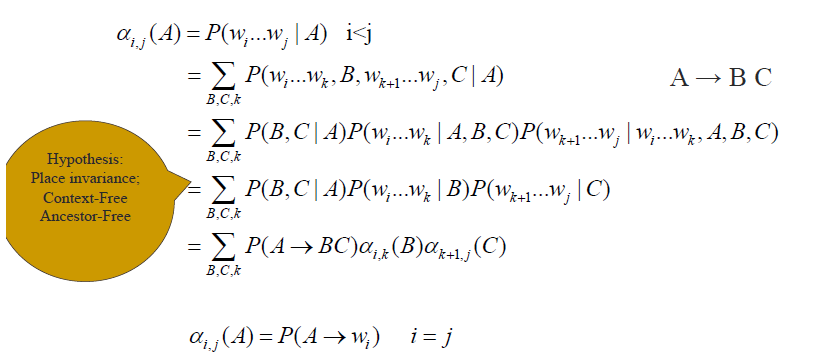
类似于从叶子节点开始向上建立一棵树的过程,先计算alpha(i,i)就是从非终止符到终止符的概率
然后开始拉大区间长度,计算使用区间内的每一个可能的推导的累加概率
直到计算到S树顶的位置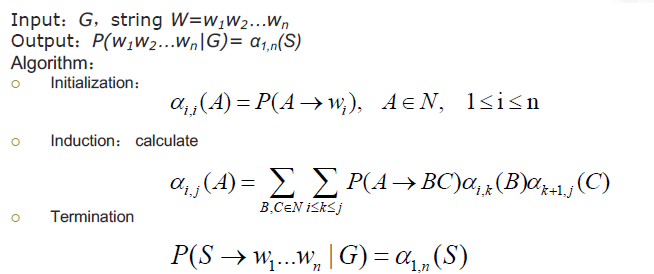
向外算法
向外算法考虑的是生成左边终止符串和A以及右边终止符串的概率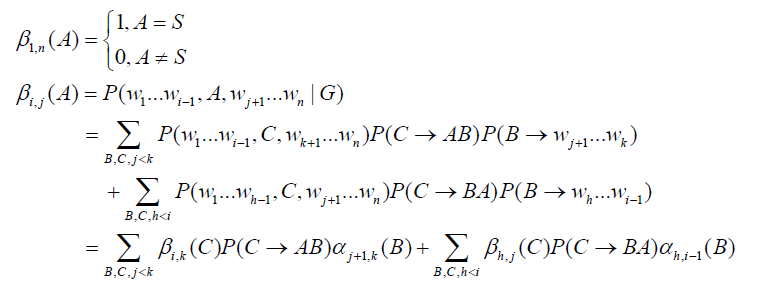
原概率即父节点概率乘上推导概率乘上另一半推导的概率,剩下的就是A的概率,分类分为B在左边或者是右边
最后的计算就是对所有可能的A计算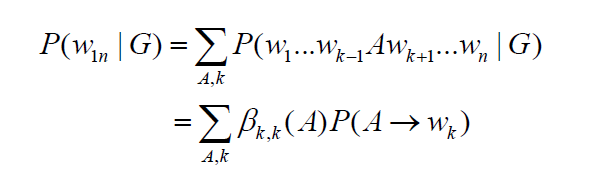
维特比算法求最大概率生成树

性能分析
空间复杂大致在:符号n^2。主要的问题就是在存储分数上,可以使用beamsearch
时间复杂度大致于:规则n^3
正确率分析:三元组描述结果:[start,end,label],C是正确的,M是总预测数目,N是标注数目
- precision=C/M
- recall = C/N
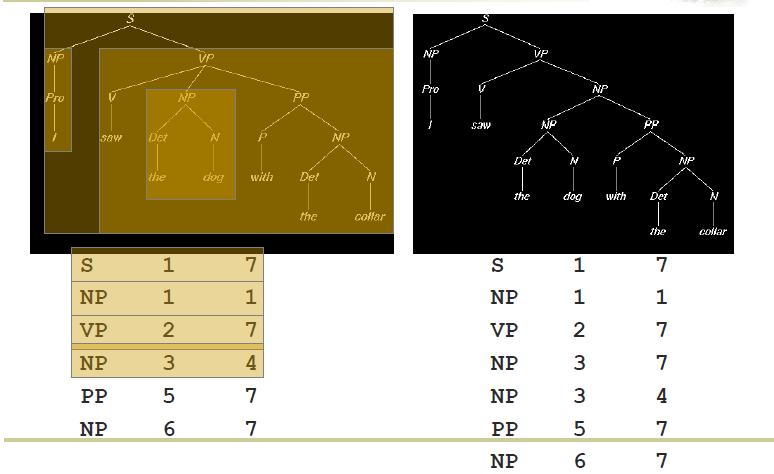
纠正
之前的独立假设太强了,实际上是上下文有关的
某个成分的展开和他的上下文(父子节点是有关系的)
- 一种方法就是在展开的时候记忆了他的父节点,笛卡尔积作为一个新的状态
- 还有一种就是记忆了叶节点的词
原先的模型假设了上下文无关
对结构的偏好不能体现
对结果词的偏好不能提现
Lexicalized parsing
在一个产生式的右边存在有一个head(关键部分)
然后可以层层的传递,进而在整个树里的每一个层级都存在一个headWord
在求解树结构的时候就可以把headword的信息加入

若有收获,就点个赞吧
0 人点赞
