发展历程简介
–基于规则的机器翻译
–基于实例的机器翻译
–统计机器翻译
–神经网络机器翻译
基于规则的机器翻译
更新和加强模型
- 扩大词典
- 指定新的规则
- 需要和旧的规则兼容
- 不引入新的错误
- 规则很多
- 需要专家的参与
基于实例的机器翻译
从语料库里学习翻译的实例
使用的是一种类比的思路
统计机器翻译
词对齐:自动学习翻译的对应关系,无监督方法,通过共现
短语对齐:
语法树对齐
翻译顺序的调整
翻译结果评价
人工评价
- 充分性
- 流畅性
自动评价
- WordErrorRate 计算编辑距离
- Position independent WER 不考虑顺序
- BLEU,计算precision,
- 加上了一个cap保证最大计数,避免出现全冗余
- 可能出现翻译过短,用recall
- 长度惩罚,用Sentence Brevity Penalty
- Translation Error Rate 避免译文之间的干扰,选一个最接近的参考译文


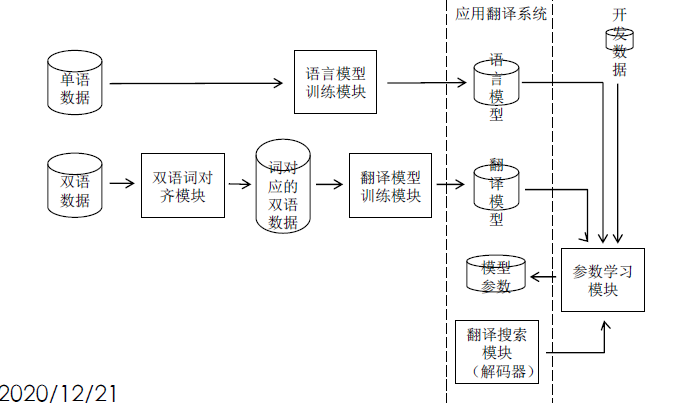

神经网络机器翻译
Seq2Seq,从单词序列到单词序列的模式
不再抽取带有噪音的规则,也不需要构造复杂的规则组合了
RNN\CNN + Attention
Self-Attention
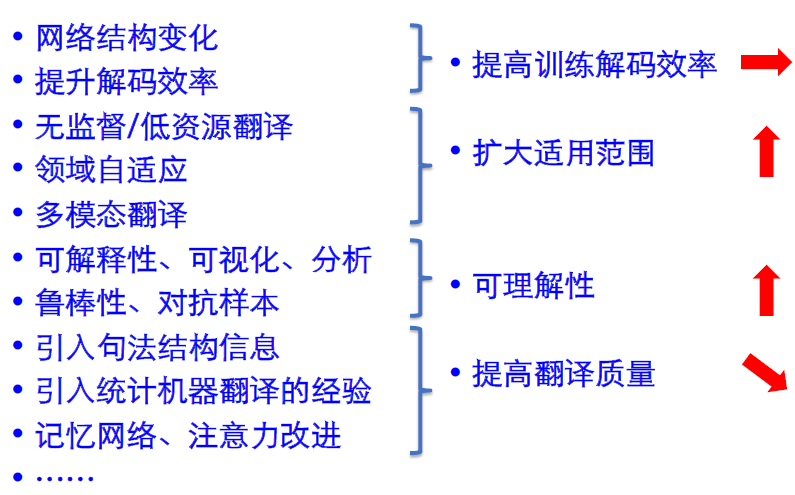
拓展研究方向

若有收获,就点个赞吧
0 人点赞
