需要用一些技术把输入的文本转化为表示
One-Hot编码
Bag-Of-Word
N-gram的Bag-Of-Word
更多的结构,语法,语意信息
有一些问题
- 维度灾难
- 两个词之间丝毫不相似
上下文表示
LSI和SVD
使用一个文档和单词的矩阵,但是这个矩阵会太大了,所以需要映射到低维空间:使用SVD降维
https://www.cnblogs.com/pinard/p/6805861.html
这里我们简要回顾下SVD:对于一个m×nm×n的矩阵AA,可以分解为下面三个矩阵:
Am×n=Um×mΣm×nVTn×nAm×n=Um×mΣm×nVn×nT
有时为了降低矩阵的维度到k,SVD的分解可以近似的写为:
Am×n≈Um×kΣk×kVTk×nAm×n≈Um×kΣk×kVk×nT
如果把上式用到我们的主题模型,则SVD可以这样解释:我们输入的有m个文本,每个文本有n个词。而AijAij则对应第i个文本的第j个词的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后,UilUil对应第i个文本和第l个主题的相关度。VjmVjm对应第j个词和第m个词义的相关度。ΣlmΣlm对应第l个主题和第m个词义的相关度。
- 计算复杂
- 线性模型
- 对K有要求
- 词序没有考虑
- 对于新词文档不兼容
Word2vec
CBOW用周边预测自己
SkipGram用自己预测周边
训练的时候使用了负采样技术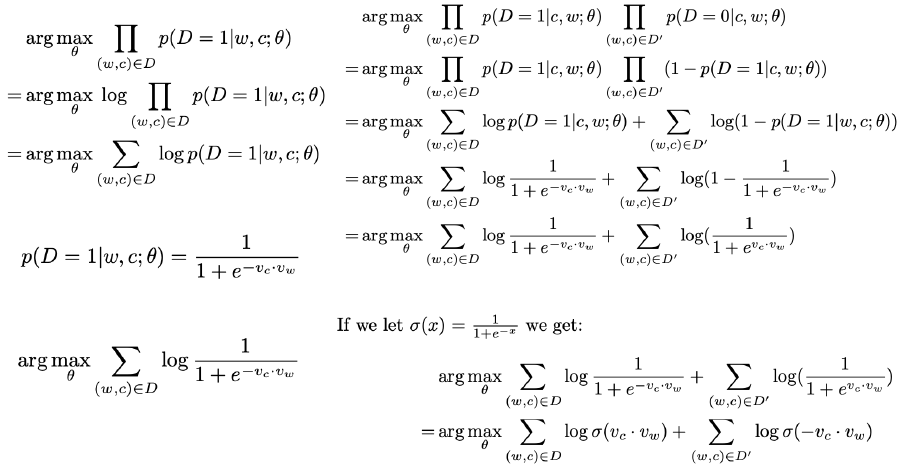
词向量好玩的地方
- 词的类比,可以看到相似词类比
- 表示句子,可以用平均

若有收获,就点个赞吧
0 人点赞
