作者:
数据科学工作小组的角色有哪些?各个角色的主要任务和角色之间如何配合的自己的理解。
P2
our survey questions dive into 5 major roles in a data science team (engineer/analyst/programmer, researcher/scientist, domain expert, manager/executive, and communicator), and 6 stages (understand problem and create plan, access and clean data, select and engineer features, train and apply models, evaluate model outcomes, and communicate with clients or stakeholders) in a data science workflow
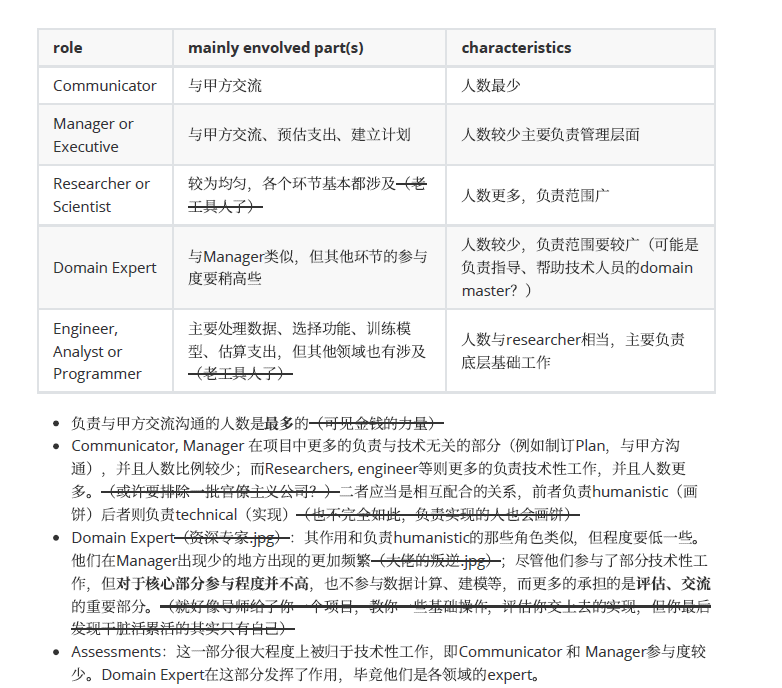
对于5个在数据科学团队中的关键角色:
- 工程师,分析员,程序员
- 研究者,科学家
- 相关领域的专家
- 经理
- 沟通者
论文中的数据从哪里来?
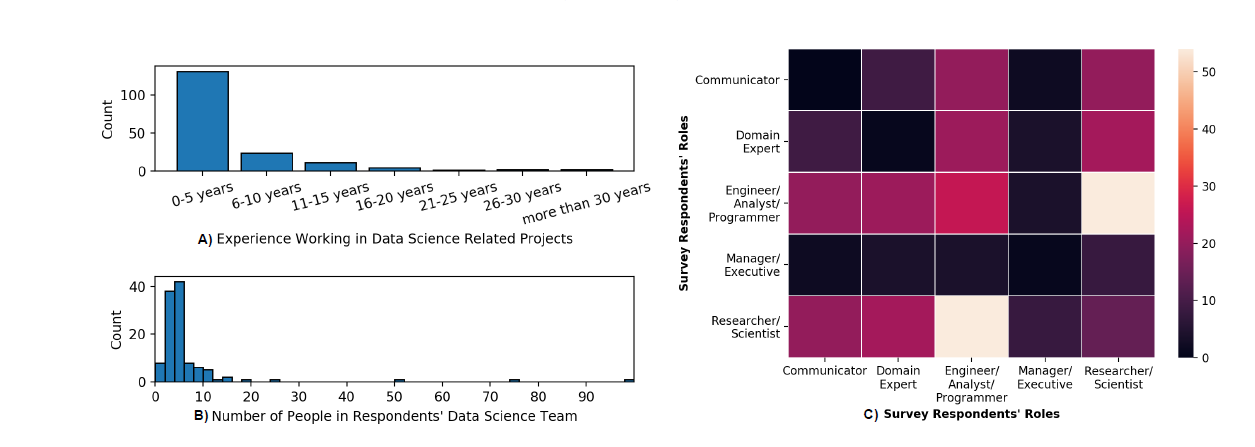
数据来源于在Slack channel贡献过或者是阅读关于数据科学的内容
他们匿名的对问卷进行回答,平时大约有1000名,参与者183人大致代表20%的人
他们匿名回答,数据来自于他们对问卷的回答以及他们在数据科学团队里的位置(角色)
Participants were a self-selected convenience sample of employees in IBM who read or contributed to Slack channels about data science (e.g., channel-names such as “deeplearning”, “data-science-atibm”, “ibm-nlp”, and similar). Participants worked in diverse roles in research, engineering, health sciences, management, and related line-of-business organizations. We estimate that the Slack channels were read by approximately 1000 employees. Thus, the 183 people who provided data constituted a 20% percent participation rate.
Participants had the option to complete the survey anonymously. Therefore, our knowledge of
the participants is derived from their responses to survey items about their roles on data science
teams (Figure 2).
问题:
- 最近的数据科学项目
- 协作,角色和使用的技巧(如果可以透露)
- 在数据科学分析工作流程中的不同阶段的角色
- 在协作过程中使用的工具
- 最后形容一下在协作过程中对代码分享和代码重用等等的工作
论文中的数据使用了哪些数据分析方法帮助得到结论?
结合丰富的图表展示数据,同时利用图标的特征对数据的特性进行分析,最后得到自己的结论
论文中的数据可视化形式有哪些,你觉得哪种形式比较好,理由呢?
- 条形图
- 优势:对比很清晰,对于各个数据的大小明显
- 堆积柱形图
- 优势:包含的信息量很⼤并且直观,并且能够看出各个项⼤致的⽐例。
- 缺点:⽤于显⽰趋势不够明显,但这个research中并不涉及到这⼀点。
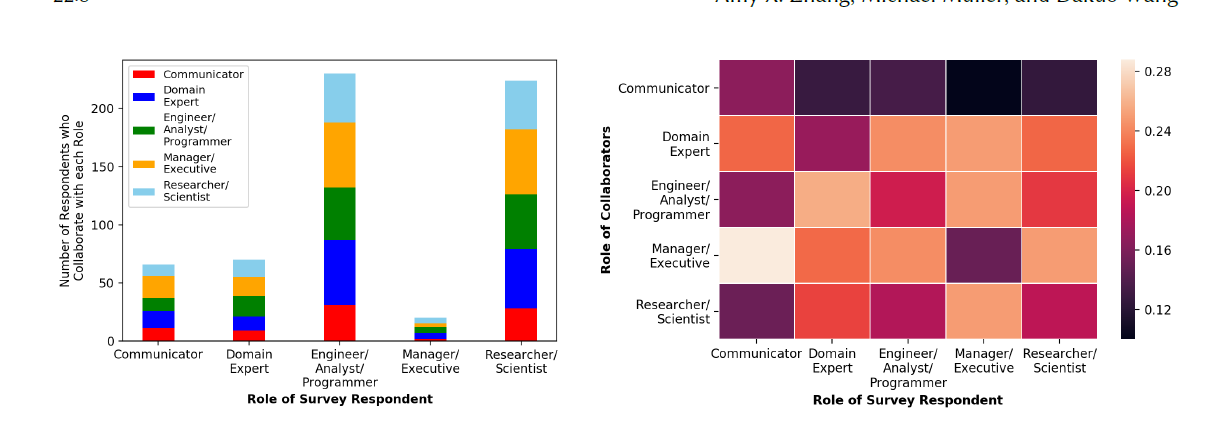
- 热力图(热力图可以观察到是否具有对称性,原文中A对B的态度是否和B对A的态度是一致的)
- 有向图,有向图的方向代表着态度,线的粗细代表程度
- 优势:很直观,譬如Fig 4很容易看出各个⻆⾊之间的关系的紧密程度(线条粗细)
- 缺点:仅仅只有定性的观测,不够精确。
- 表格
- 优势:信息紧凑,包含最⼤的信息量,并且可以得到精确的数据而不是⼤致的估计。
- 缺点:不够直观,阅读量⼤。
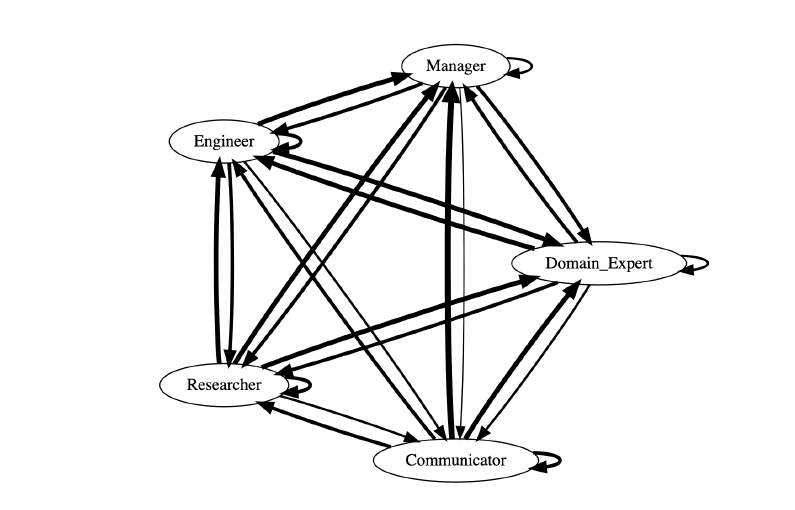
我觉得都不错,数据的可视化手段需要和数据的特征以及展示的目的所匹配
上文也有提到,对不同的数据和侧重的不同的特征维度都有适合的可视化方法
尝试和选课的同学一起构建一个3人左右的数据科学小组,最好是不同专业的同学构成。
- 18计科佘帅杰
- 18自动化张恩茂
- 19电子任天骐
第三部分
第三部分涉及了一些有关合作的问题。
1、我们可以从间接利益相关者中选取合作对象。(间接利益相关者是指受数据科学系统,代码或数据影响的人)。
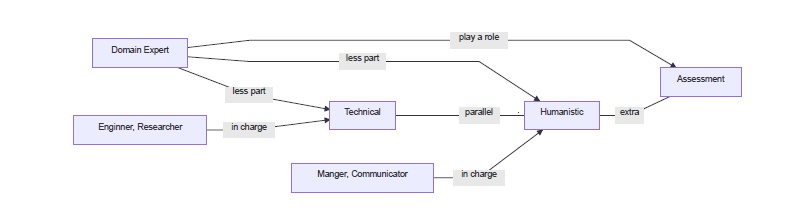
2、在合作方面,数据科学工作中存在着不平衡的合作,不同角色之间的合作认知是不匹配的,我们应该加强沟通交流,尽量消除不平衡。
3、在数据科学工作中,围绕AI的公平性和偏差检测与缓解的活动是有发生,但是很大程度上似乎被当做技术问题来解决,目前参与这个过程的主要是数据科学家和领域专家,最了解政策和对AI负面后果最担心的人群——传播者和经理人却很少参与。在未来,管理者会更多地参与这个阶段。
4、该论文所获取数据方面的局限性:
①:调查对象都来自与一个大型的科技公司,他们的观点可能并不能代表从事数据科学相关项目的广大专业人士。
②:所有的受访者都在小团体中扮演角色,这显然不能包含所有情况。
③:研究结果基于在线调查的自我报告数据,这样的数据带有较为强烈的受访者的主观意愿。

若有收获,就点个赞吧
0 人点赞
