原文地址
React 18 正式发布啦,是时候卷一波新知识了。接下来的几篇文章,我将跟大家详细的分享 React 18 每一个新特性。有兴趣跟我一起玩的可以关注我一波。
在新的官方文档中,我们发现 hooks api 新增了一个奇怪的新 hook useId。
const id = useId();
这个 hook 有什么用呢?
在之前的版本中,我们可以使用 React 进行服务端渲染(SSR)。在开发模式上,我们可以在客户端与服务端共享同一个 React 组件。但是,这里就会有一个小问题。
如果当前组件已经在服务端渲染过了,但是在客户端我们并没有什么手段知道这个事情,于是客户端还会重新再渲染一次,这样就造成了冗余的渲染。
要理解这个背景,我们需要对 SSR 的流程有一个简单的概念。
在服务端,我们会将 React 组件渲染成为一个字符串,这个过程叫做脱水「dehydrate」。字符串以 html 的形式传送给客户端,作为首屏直出的内容。到了客户端之后,React 还需要对该组件重新激活,用于参与新的渲染更新等过程中,这个过程叫做「hydrate」
脱水与注水的取名灵感来源,我感觉是从三体人的特性中来的

那么这个过程中,同一个组件在服务端和客户端之间就需要有一个相对稳定的 id 来确定对应的匹配关系。
如何解决这个问题呢?
如果客户端和服务端的组件渲染顺序是一致的。那么我们就可以在全局通过递增的计数器来达到这个目标
var fieldCounter = 0export default function Field(props) {const [inputId, setInputId] = useState(++fieldCounter)return (<div className='field'><label htmlFor={inputId}>props.label</label><input type={props.type} id={inputId} name={props.name} value="" /></div>)}
但是,React 在后续的更新中,就开始搞事情,客户端渲染有 reconciler ,服务端渲染有 fizz,他们的作用大概相同,那就是根据某种优先级进行任务调度。于是,无论是客户端还是服务端,都可能不会按照稳定的顺序渲染组件了,这种递增的计数器方案就无法解决问题。
那么,有没有一种属性,是在客户端和服务端都绝对稳定的呢?
当然有,那就是组件的树状结构。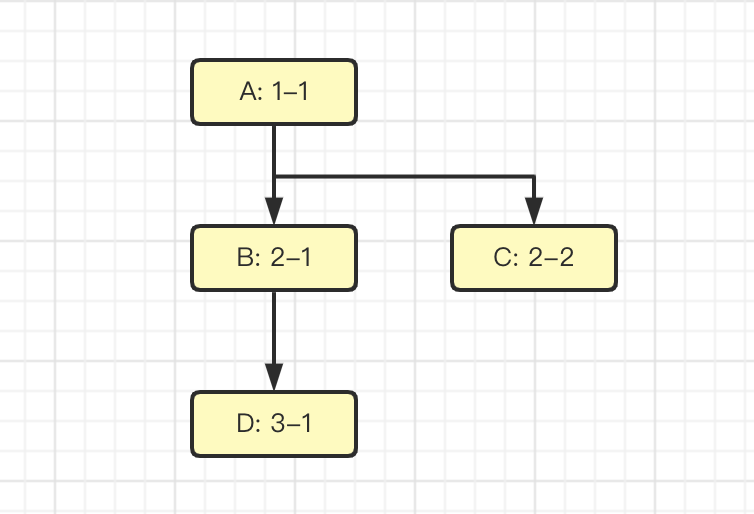
图中有组件 A B C D,那么有可能因为优先级的问题,导致 B、C 的渲染顺序不同,但是他们的树状结构始终稳定。因此,我们就可以使用这种思路来解决问题。
如何使用
当一个组件,同时会被服务端和客户端渲染时,我们就可以使用 useId 来创建当前组件的唯一身份。
function Checkbox() {const id = useId();return (<><label htmlFor={id}>Do you like React?</label><input id={id} type="checkbox" name="react"/></>);};
如果在同一个组件中,我们需要多个 id,那么一定不要重复的使用 useId,而是基于一个 id 来创建不同的身份标识。额外添加不同的字符串即可。
function NameFields() {const id = useId();return (<div><label htmlFor={id + '-firstName'}>First Name</label><div><input id={id + '-firstName'} type="text" /></div><label htmlFor={id + '-lastName'}>Last Name</label><div><input id={id + '-lastName'} type="text" /></div></div>);}
兴趣了解:身份生成算法
身份 id 是 32 进制的字符串,其二进制表示对应树中节点的位置。
每次树分叉成多个子节点时,我们都会在序列的左侧添加额外的位数,表示子节点在当前子节点层级中的位置。
00101 00010001011010101╰─┬─╯ ╰───────┬───────╯Fork 5 of 20 Parent id
这里我们使用了两个前置 0 位。如果只考虑当前的子节点,我们使用 101 就可以了,但是要表达当前层级所有的子节点,三位就不够用。因此需要 5 位。
出于同样的原因,slots 是 1-indexed 而不是 0-indexed。否则就无法区分该层级第 0 个子节点与父节点。
如果一个节点只有一个子节点,并且没有具体化的 id,声明时没有包含 useId hook。那么我们不需要在序列中分配任何空间。例如这两颗数会产生相同的 id:
<> <><Indirection> <A /><A /> <B /></Indirection> </><B /></>
但是我们不能跳过任何包含了 useId 的节点。否则,只有一个子节点的父节点就无法区分开来。比如,这棵树只有一个子节点,但是父子节点必须有不同的 id
<Parent><Child /></Parent>
为了处理这种情况,每次我们生成一个 id 时,都会分配一个一个新的层级。当然这个层级就只有一个节点「长度为 1 的数组」。
最后,序列的大小可能会超出 32 位,发生这种情况时,我们通过将 id 的右侧部分转换为字符串并将其存储在溢出变量中。之所以使用 32 位字符串,是因为 32 是 toString() 支持的 2 的最大幂数。这样基数足够大就能够得到紧凑的 id 序列,并且我们希望基数是 2 的幂,因为每个 log2(base) 对应一个字符,也就是 log2(32) = 5 bits = 1 ,这样意味着我们可以在不影响最终结果的情况下删除末尾 5 的位。

若有收获,就点个赞吧
0 人点赞
