什么是前端监控?
它指的是通过一定的手段来获取用户行为以及跟踪产品在用户端的使用情况,并以监控数据为基础,为产品优化指明方向,为用户提供更加精确、完善的服务。
前端监控
一般来讲一个成熟的产品,运营与产品团队需要关注用户在产品内的行为记录,通过用户的行为记录来优化产品,研发与测试团队则需要关注产品的性能以及异常,确保产品的性能体验以及安全迭代。
所以前端监控一般也分为三大类:
数据监控(监控用户行为)
- PV/UV: PV(page view):即页面浏览量或点击量;UV独立IP访客(Unique Visitor):指访问某个站点或点击某条新闻的不同 IP 地址的人数
- 用户在每一个页面的停留时间
- 用户通过什么入口来访问该网页
- 用户在相应的页面中触发的行为,等…
统计这些数据是有意义的,比如我们知道了用户来源的渠道,可以促进产品的推广,知道用户在每一个页面停留的时间,可以针对停留较长的页面,增加广告推送等等。
性能监控(监控页面性能)
- 不同用户,不同机型和不同系统下的首屏加载时间
- 白屏时间
- http 等请求的响应时间
- 静态资源整体下载时间
- 页面渲染时间
- 页面交互动画完成时间,等…
这些性能监控的结果,可以展示前端性能的好坏,根据性能监测的结果可以进一步的去优化前端性能,尽可能的提高用户体验。
异常监控(监控产品、系统异常)
及时的上报异常情况,可以避免线上故障的发上。虽然大部分异常可以通过 try catch 的方式捕获,但是比如内存泄漏以及其他偶现的异常难以捕获。常见的需要监控的异常包括:
- Javascript 的异常监控
- 样式丢失的异常监控
埋点上报
OK,上面我们说到了前端监控的三个分类,了解了一个产品需要监控哪些内容以及为什么需要监控这些内容,那么我们应该怎么实现前端监控呢?
实现前端监控,第一步肯定是将我们要监控的事项(数据)给收集起来,再提交给后台进行入库,最后再给数据分析组进行数据分析,最后处理好的数据再同步给运营或者是产品。数据收集的丰富性和准确性会直接影响到我们做前端监控的质量,因为我们会以此为基础,为产品的未来发展指引方向。
现在常见的埋点上报方法有三种:手动埋点、可视化埋点、无埋点
手动埋点
手动埋点,也叫代码埋点,即纯手动写代码,调用埋点 SDK 的函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据,像[友盟]、[百度统计]等第三方数据统计服务商大都采用这种方案。手动埋点让使用者可以方便地设置自定义属性、自定义事件;所以当你需要深入下钻,并精细化自定义分析时,比较适合使用手动埋点。
手动埋点的缺陷就是,项目工程量大,需要埋点的位置太多,而且需要产品开发运营之间相互反复沟通,容易出现手动差错,如果错误,重新埋点的成本也很高。
可视化埋点
通过可视化交互的手段,代替上述的代码埋点。将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义的增加埋点事件等等,最后输出的代码耦合了业务代码和埋点代码。
可视化埋点的缺陷就是可以埋点的控件有限,不能手动定制。
无埋点
无埋点则是前端自动采集全部事件,上报埋点数据,由后端来过滤和计算出有用的数据。优点是前端只要一次加载埋点脚本,缺点是流量和采集的数据过于庞大,服务器性能压力山大。
为什么都用GIF来做埋点?
发现过程
首先说一下我是怎么发现的,前一段时间,产品提了个需求,说我们现在的书籍曝光上报规范并不是他们想要的数据,并且以后所有页面的书籍上报都统一成最新规范。
曝光规范:
- 书籍出现在可视区并停留1秒,算作有效曝光
- 书籍不能重复曝光,假如它一直在可视区滚动时只能上报一次
- 当它移出可视区后再回到可视区,再按第一点进行曝光
OK,既然要所有页面统一,那就只能封装成通用库来使用了,这里实现逻辑就不贴了,想看的私聊我发你,主要的难点就是停留时长计算,以及曝光标记。
const exposeReportClass = new exposeReport({scrollDom: "", // 滚动容器,建议指定一个滚动容器,不传默认为windowwatchDom: ".bookitem", // 监听的dom,建议使用class类,标签也支持time: 1000 // 停留有效时长ms});// 提供两个上报方法exposeReportClass.didReport(()=>{// 手动上报//callback})exposeReportClass.scrollReport(()=>{// 滚动动上报//callback})//
具体业务逻辑之需要放在对应的callback里面,而上报逻辑开发者无需考虑,因为我底层已经统一处理好了。
然后我再测试的时候就发现,上报发的请求居然是通过图片发起的,并不是我们认为的接口上报。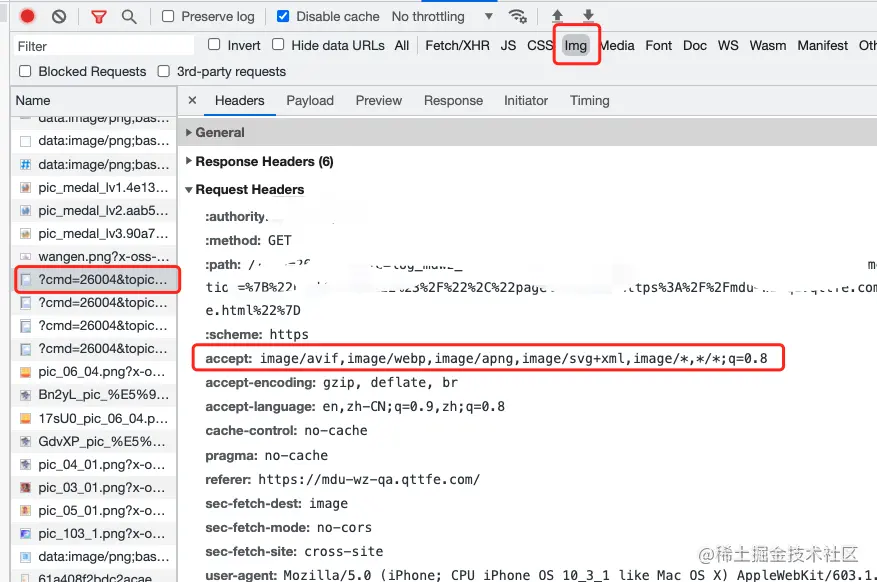
然后我去查了下资料,发现很多大厂的上报都是这么干的!
使用GIF上报的原因
向服务器端上报数据,可以通过请求接口,请求普通文件,或者请求图片资源的方式进行。只要能上报数据,无论是请求GIF文件还是请求js文件或者是调用页面接口,服务器端其实并不关心具体的上报方式。那为什么所有系统都统一使用了请求GIF图片的方式上报数据呢?
- 防止跨域
一般而言,打点域名都不是当前域名,所以所有的接口请求都会构成跨域。而跨域请求很容易出现由于配置不当被浏览器拦截并报错,这是不能接受的。但图片的src属性并不会跨域,并且同样可以发起请求。(排除接口上报)
- 防止阻塞页面加载,影响用户体验
通常,创建资源节点后只有将对象注入到浏览器DOM树后,浏览器才会实际发送资源请求。反复操作DOM不仅会引发性能问题,而且载入js/css资源还会阻塞页面渲染,影响用户体验。
但是图片请求例外。构造图片打点不仅不用插入DOM,只要在js中new出Image对象就能发起请求,而且还没有阻塞问题,在没有js的浏览器环境中也能通过img标签正常打点,这是其他类型的资源请求所做不到的。(排除文件方式)
- 相比PNG/JPG,GIF的体积最小
最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节。
同样的响应,GIF可以比BMP节约41%的流量,比PNG节约35%的流量。
并且大多采用的是1*1像素的透明GIF来上报
1x1像素是最小的合法图片。而且,因为是通过图片打点,所以图片最好是透明的,这样一来不会影响页面本身展示效果,二者表示图片透明只要使用一个二进制位标记图片是透明色即可,不用存储色彩空间数据,可以节约体积。
Image灵活性
- 所有浏览器都支持imge对象
- 不受跨域影响
- 如果使用第三方库,第三方库出错,埋点失效


若有收获,就点个赞吧
0 人点赞
