- 报文结构
- 起始行 (请求方法 请求url http协议以及版本)
- 请求行 响应行
- 头部
- 请求头 响应头
- 空格
- 很重要,用来区分开头部和实体。
- 起始行 (请求方法 请求url http协议以及版本)
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。
- 实体
- 也就是body部分。请求报文对应请求体, 响应报文对应响应体
2.请求方法
- 分类
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
- TRACE: 追踪请求-响应的传输路径
- GET 和 POST
- web 中的绝大多数请求都是用 get 完成的,post 请求目前为止我只是在 ajax 以及 form 表单中有见过
- 语义上 获取数据 提交
- 具体的差别
- 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。(get 请求会有缓存,所以在开发过程中,很多时候我们要手动清除缓存,不然看不到修改后的样子所以一般要获取最新的文件(非缓存文件),可以加个类似时间戳一样的参数。)
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET是幂等,而POST不是。(幂等表示执行相同的操作,结果也是相同的)
- 从TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
3.uri
- scheme 表示协议名,比如http, https, file等等。后面必须和://连在一起。
user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用。
host:port表示主机名和端口。
path表示请求路径,标记资源所在位置。
query表示查询参数,为key=val这种形式,多个键值对之间用&隔开。
fragment表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置。
4.HTTP 状态码
- 1xx: 表示目前是协议处理的中间状态,还需要后续操作。
- 100 接到了请求必须响应
- 101Switching Protocols 升级webstock,如果服务器统一 返回101
- 2xx: 表示成功状态。
- 200 OK是见得最多的成功状态码。通常在响应体中放有数据
- 204 No Content含义与 200 相同,但响应头后没有 body 数据
- 206 Partial Content顾名思义,表示部分内容,它的使用场景为 HTTP 分块下载和断点续传,当然也会带上相应的响应头字段Content-Range。
- 3xx: 重定向状态,资源位置发生变动,需要重新请求。
- 301 Moved Permanently即永久重定向,对应着302 Found,即临时重定向。
比如你的网站从 HTTP 升级到了 HTTPS 了,以前的站点再也不用了,应当返回301,这个时候浏览器默认会做缓存优化,在第二次访问的时候自动访问重定向的那个地址。
而如果只是暂时不可用,那么直接返回302即可,和301不同的是,浏览器并不会做缓存优化。
- **304 Not Modified**: 当协商缓存命中时会返回这个状态码。详见[浏览器缓存](https://link.juejin.cn?target=http%3A%2F%2F47.98.159.95%2Fmy_blog%2Fperform%2F001.html)
- 4xx: 请求报文有误。
- 400 Bad Request:
- 1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。
- 2、请求参数有误。
- 403 Forbidden: 这实际上并不是请求报文出错,而是服务器禁止访问,原因有很多,比如法律禁止、信息敏感。
- 404 Not Found: 资源未找到,表示没在服务器上找到相应的资源。
- 405 Method Not Allowed: 请求方法不被服务器端允许。
- 406 Not Acceptable: 资源无法满足客户端的条件。
- 408 Request Timeout: 服务器等待了太长时间。
- 409 Conflict: 多个请求发生了冲突。
- 413 Request Entity Too Large: 请求体的数据过大。
- 414 Request-URI Too Long: 请求行里的 URI 太大。
- 429 Too Many Request: 客户端发送的请求过多。
- 431 Request Header Fields Too Large请求头的字段内容太大。
- 400 Bad Request:
- 5xx: 服务器端发生错误。
- 500 Internal Server Error: 内部错误 无法解析
- 501 Not Implemented: 表示客户端请求的功能还不支持。
- 502 Bad Gateway: 服务器无法响应 重启?``
- 503 Service Unavailable: 表示服务器当前很忙,暂时无法响应服务。
5.HTTP 的特点
- 灵活可扩展,主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
- 可靠传输。HTTP 基于 TCP/IP,因此把这一特性继承了下来。这属于 TCP 的特性,不具体介绍了。
- 请求-应答。也就是一发一收、有来有回, 当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。
- 无状态。这里的状态是指通信过程的上下文信息,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
6.HTTP 缺点
- 无状态 所谓的优点和缺点还是要分场景来看的,对于 HTTP 而言,最具争议的地方在于它的无状态。 在需要长连接的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。 但与此同时,另外一些应用仅仅只是为了获取一些数据,不需要保存连接上下文信息,无状态反而减少了网络开销,成为了 http 的优点。
- 明文传输 即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。 这当然对于调试提供了便利,但同时也让 HTTP 的报文信息暴露给了外界,给攻击者也提供了便利。WIFI陷阱就是利用 HTTP 明文传输的缺点,诱导你连上热点,然后疯狂抓你所有的流量,从而拿到你的敏感信息。
- 队头阻塞问题 当 http 开启长连接时,共用一个 TCP 连接,同一时刻只能处理一个请求,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态,也就是著名的队头阻塞问题。接下来会有一小节讨论这个问题。
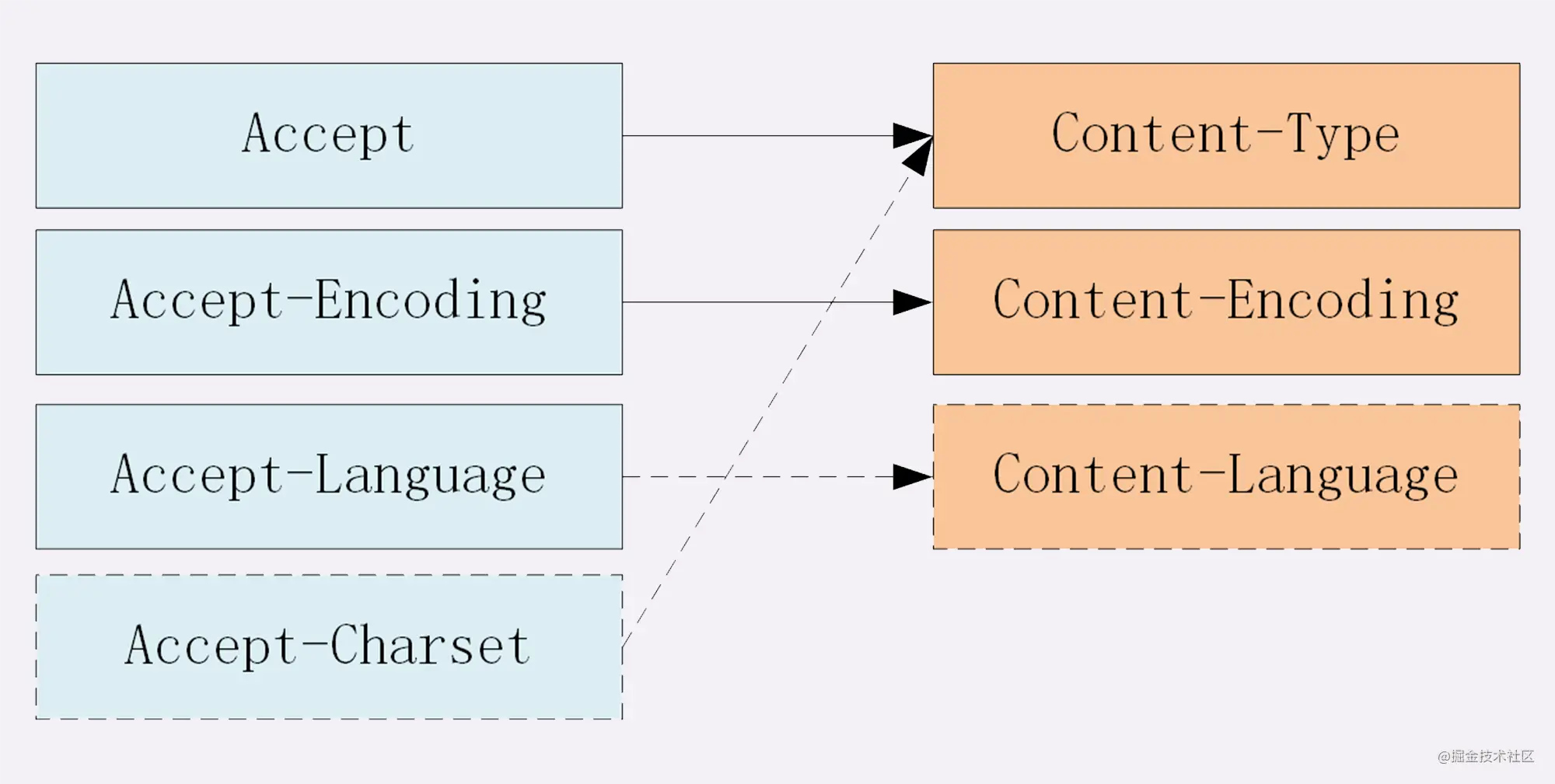
7.Accept 系列字段
- 数据格式 MIME(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)
发送端:Content-Type 接受端Accept
- text: text/html, text/plain, text/css 等- image: image/gif, image/jpeg, image/png 等- audio/video: audio/mpeg, video/mp4 等- application: application/json, application/javascript, application/pdf, application/octet-stream
- 压缩方式
发送方的Content-Encoding 接受方的Accept-Encoding
- gzip: 当今最流行的压缩格式- deflate: 另外一种著名的压缩格式- br: 一种专门为 HTTP 发明的压缩算法
- 支持语言
- 发送端 Content-Language: zh-CN, zh, en // 接收端 Accept-Language: zh-CN, zh, en
- 字符集
发送端并没有对应的Content-Charset, 而是直接放在了Content-Type中,以charset属性指定 接收端对应为Accept-Charset指定可以接受的字符集
// 发送端
Content-Type: text/html; charset=utf-8
// 接收端
Accept-Charset: charset=utf-8
8.定长和不定长的数据,HTTP 是怎么传输
- 定长包体 Content-Length
- 不定长包体Transfer-Encoding: chunked
- Content-Length 字段会被忽略
- 基于长连接持续推送动态内容
9.处理大文件的传输
- 如何支持
- Accept-Ranges: none
- Range 字段拆解
// 单段数据
Range: bytes=0-9
// 多段数据
Range: bytes=0-9, 30-39
- 单段数据
- 多段数据
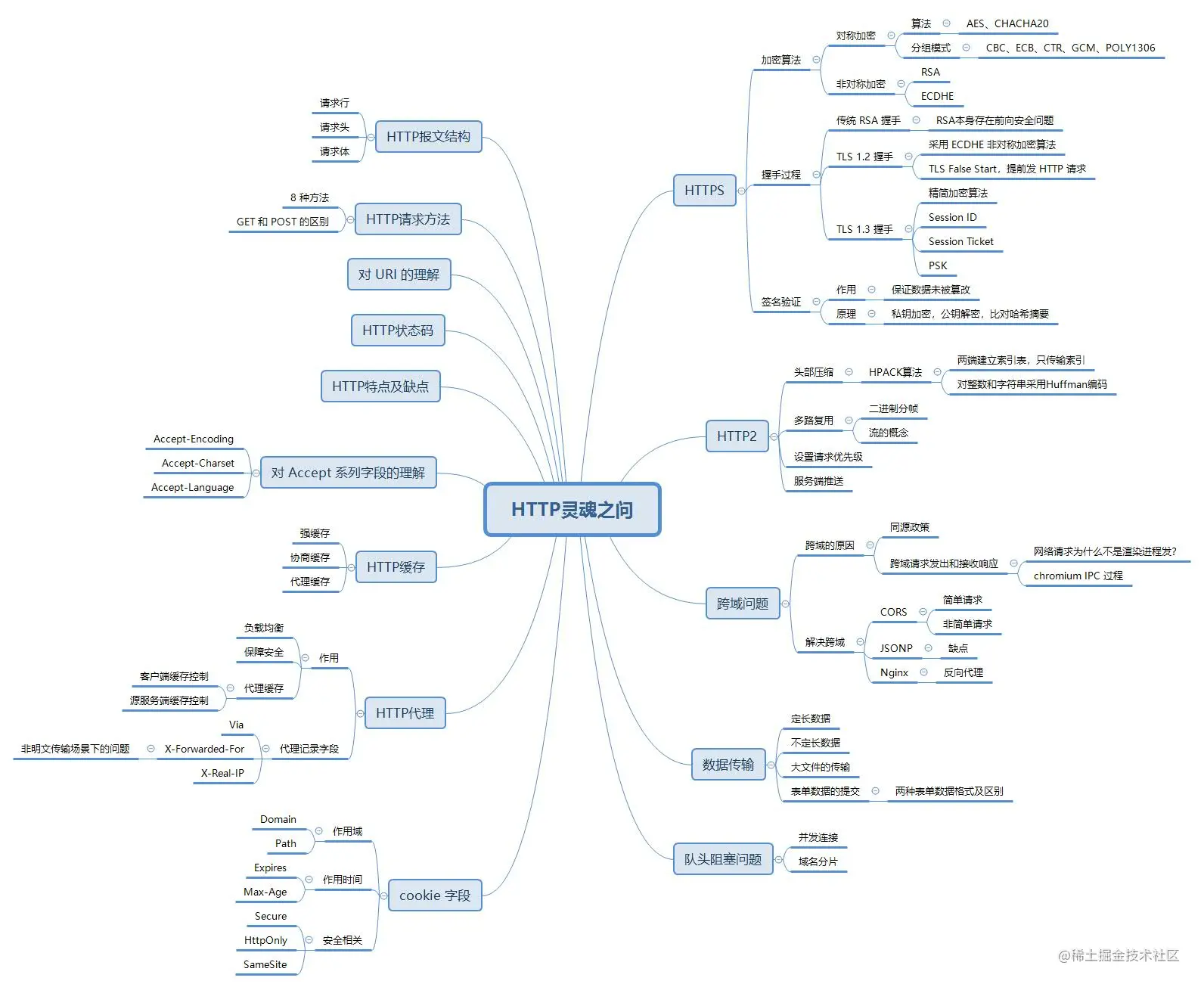
001. HTTP 报文结构是怎样的?
对于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。
而 HTTP 类似,也是header + body的结构,具体而言:
起始行 + 头部 + 空行 + 实体
由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。
起始行
对于请求报文来说,起始行类似下面这样:
GET /home HTTP/1.1
也就是方法 + 路径 + http版本。
对于响应报文来说,起始行一般张这个样:
HTTP/1.1 200 OK
响应报文的起始行也叫做状态行。由http版本、状态码和原因三部分组成。
值得注意的是,在起始行中,每两个部分之间用空格隔开,最后一个部分后面应该接一个换行,严格遵循ABNF语法规范。
头部
展示一下请求头和响应头在报文中的位置: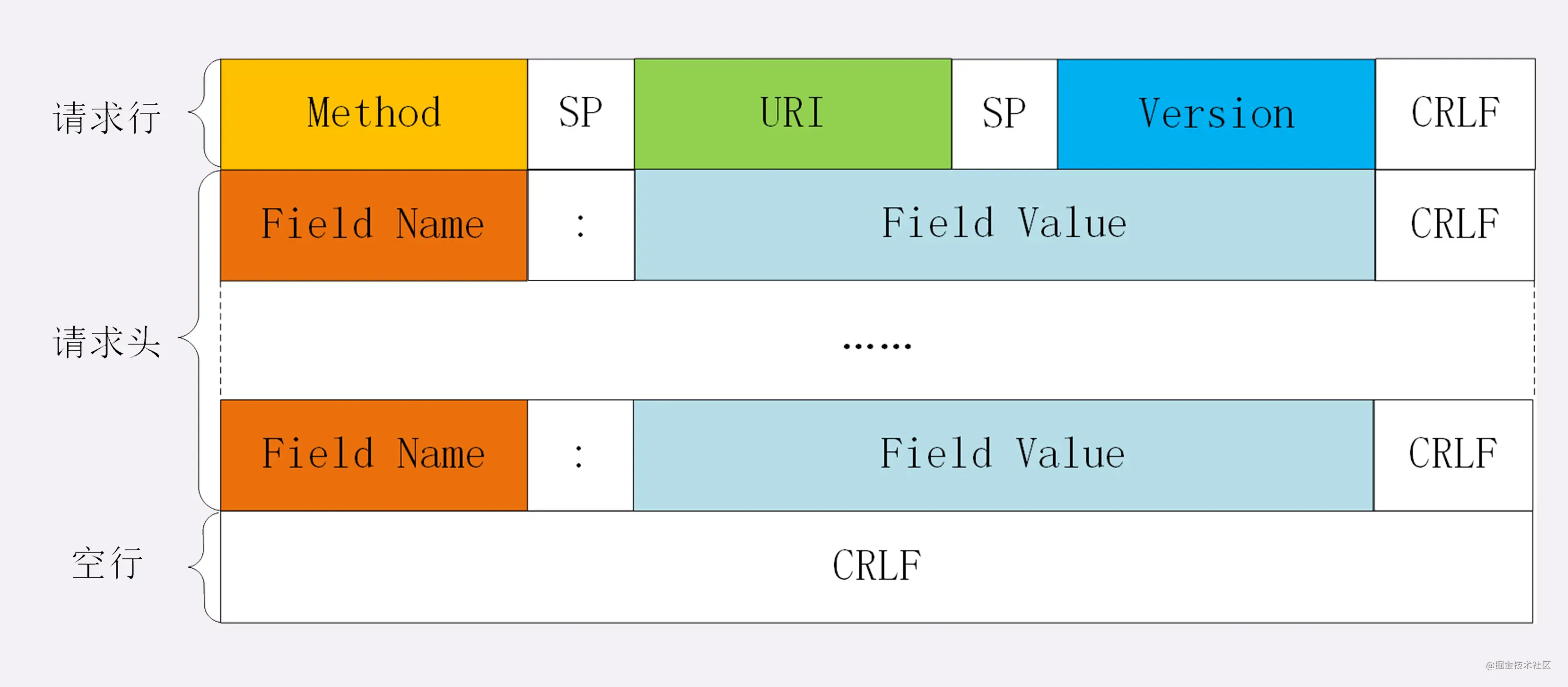
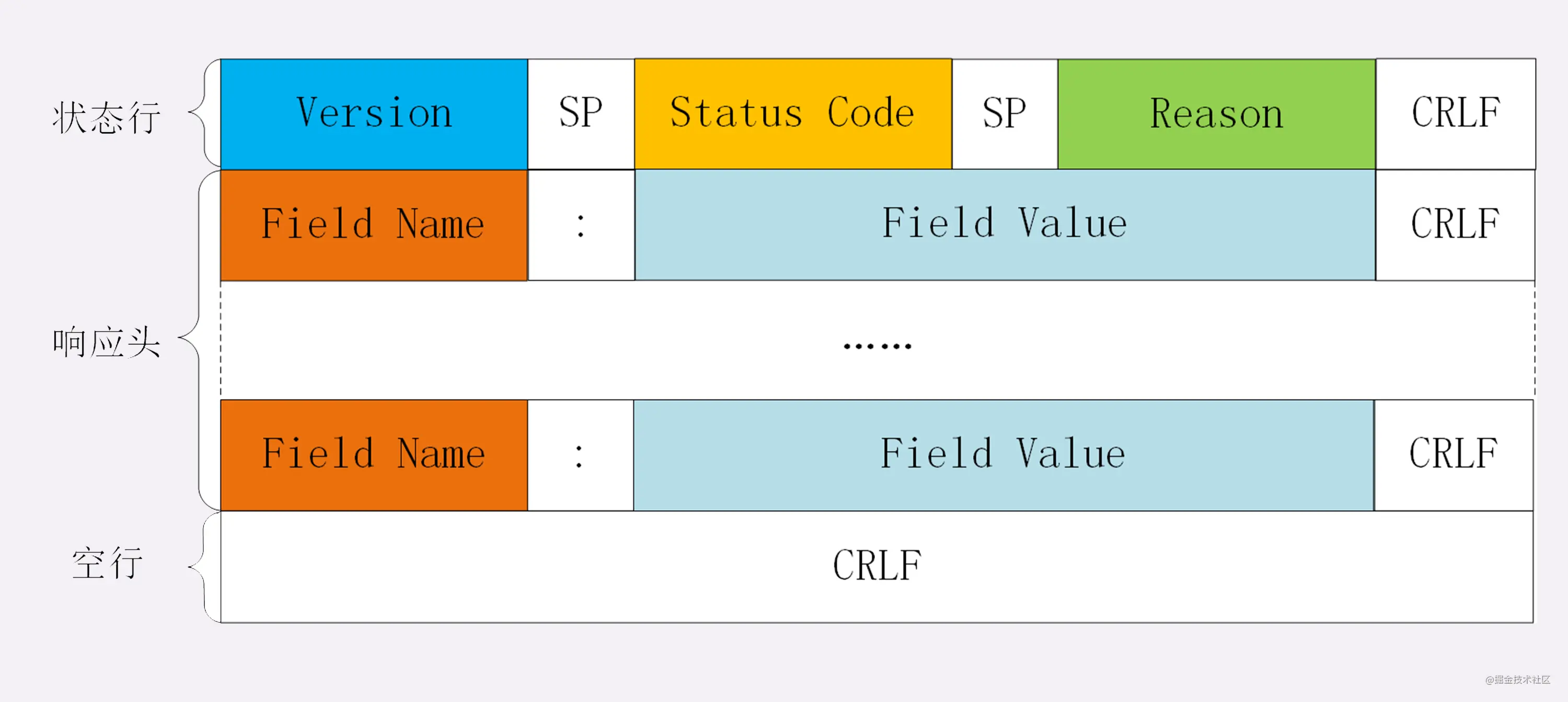
不管是请求头还是响应头,其中的字段是相当多的,而且牵扯到http非常多的特性,这里就不一一列举的,重点看看这些头部字段的格式:
- 字段名不区分大小写
- 字段名不允许出现空格,不可以出现下划线_
- 字段名后面必须紧接着
空行
很重要,用来区分开头部和实体。
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。实体
就是具体的数据了,也就是body部分。请求报文对应请求体, 响应报文对应响应体。002. 如何理解 HTTP 的请求方法?
有哪些请求方法?
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
-
GET 和 POST 有什么区别?
首先最直观的是语义上的区别。
而后又有这样一些具体的差别: 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET是幂等的,而POST不是。(幂等表示执行相同的操作,结果也是相同的)
从TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
003: 如何理解 URI?
URI, 全称为(Uniform Resource Identifier), 也就是统一资源标识符,它的作用很简单,就是区分互联网上不同的资源。
但是,它并不是我们常说的网址, 网址指的是URL, 实际上URI包含了URN和URL两个部分,由于 URL 过于普及,就默认将 URI 视为 URL 了。URI 的结构
URI 真正最完整的结构是这样的。

可能你会有疑问,好像跟平时见到的不太一样啊!先别急,我们来一一拆解。
scheme 表示协议名,比如http, https, file等等。后面必须和://连在一起。
user:passwd@ 表示登录主机时的用户信息,不过很不安全,不推荐使用,也不常用。
host:port表示主机名和端口。
path表示请求路径,标记资源所在位置。
query表示查询参数,为key=val这种形式,多个键值对之间用&隔开。
fragment表示 URI 所定位的资源内的一个锚点,浏览器可以根据这个锚点跳转到对应的位置。
举个例子:https://www.baidu.com/s?wd=HTTP&rsv_spt=1
这个 URI 中,https即scheme部分,www.baidu.com为host:port部分(注意,http 和 https 的默认端口分别为80、443),/s为path部分,而wd=HTTP&rsv_spt=1就是query部分。URI 编码
URI 只能使用ASCII, ASCII 之外的字符是不支持显示的,而且还有一部分符号是界定符,如果不加以处理就会导致解析出错。
因此,URI 引入了编码机制,将所有非 ASCII 码字符和界定符转为十六进制字节值,然后在前面加个%。
如,空格被转义成了%20,三元被转义成了%E4%B8%89%E5%85%83。004: 如何理解 HTTP 状态码?
RFC 规定 HTTP 的状态码为三位数,被分为五类:
1xx: 表示目前是协议处理的中间状态,还需要后续操作。
- 2xx: 表示成功状态。
- 3xx: 重定向状态,资源位置发生变动,需要重新请求。
- 4xx: 请求报文有误。
- 5xx: 服务器端发生错误。
接下来就一一分析这里面具体的状态码。
1xx
101 Switching Protocols。在HTTP升级为WebSocket的时候,如果服务器同意变更,就会发送状态码 101。
2xx
200 OK是见得最多的成功状态码。通常在响应体中放有数据。
204 No Content含义与 200 相同,但响应头后没有 body 数据。
206 Partial Content顾名思义,表示部分内容,它的使用场景为 HTTP 分块下载和断点续传,当然也会带上相应的响应头字段Content-Range。
3xx
301 Moved Permanently即永久重定向,对应着302 Found,即临时重定向。
比如你的网站从 HTTP 升级到了 HTTPS 了,以前的站点再也不用了,应当返回301,这个时候浏览器默认会做缓存优化,在第二次访问的时候自动访问重定向的那个地址。
而如果只是暂时不可用,那么直接返回302即可,和301不同的是,浏览器并不会做缓存优化。
304 Not Modified: 当协商缓存命中时会返回这个状态码。详见浏览器缓存
4xx
400 Bad Request: 开发者经常看到一头雾水,只是笼统地提示了一下错误,并不知道哪里出错了。
403 Forbidden: 这实际上并不是请求报文出错,而是服务器禁止访问,原因有很多,比如法律禁止、信息敏感。
404 Not Found: 资源未找到,表示没在服务器上找到相应的资源。
405 Method Not Allowed: 请求方法不被服务器端允许。
406 Not Acceptable: 资源无法满足客户端的条件。
408 Request Timeout: 服务器等待了太长时间。
409 Conflict: 多个请求发生了冲突。
413 Request Entity Too Large: 请求体的数据过大。
414 Request-URI Too Long: 请求行里的 URI 太大。
429 Too Many Request: 客户端发送的请求过多。
431 Request Header Fields Too Large请求头的字段内容太大。
5xx
500 Internal Server Error: 仅仅告诉你服务器出错了,出了啥错咱也不知道。
501 Not Implemented: 表示客户端请求的功能还不支持。
502 Bad Gateway:错误的网关,服务器作为网关或代理,从上游服务器收到了无效的响应
503 Service Unavailable: 表示服务器当前很忙,暂时无法响应服务。
005: 简要概括一下 HTTP 的特点?HTTP 有哪些缺点?
HTTP 特点
HTTP 的特点概括如下:
- 灵活可扩展,主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
- 可靠传输。HTTP 基于 TCP/IP,因此把这一特性继承了下来。这属于 TCP 的特性,不具体介绍了。
- 请求-应答。也就是一发一收、有来有回, 当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。
- 无状态。这里的状态是指通信过程的上下文信息,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
HTTP 缺点
无状态
所谓的优点和缺点还是要分场景来看的,对于 HTTP 而言,最具争议的地方在于它的无状态。
在需要长连接的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。
但与此同时,另外一些应用仅仅只是为了获取一些数据,不需要保存连接上下文信息,无状态反而减少了网络开销,成为了 http 的优点。明文传输
即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。
这当然对于调试提供了便利,但同时也让 HTTP 的报文信息暴露给了外界,给攻击者也提供了便利。WIFI陷阱就是利用 HTTP 明文传输的缺点,诱导你连上热点,然后疯狂抓你所有的流量,从而拿到你的敏感信息。队头阻塞问题
当 http 开启长连接时,共用一个 TCP 连接,同一时刻只能处理一个请求,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态,也就是著名的队头阻塞问题。接下来会有一小节讨论这个问题。006: 对 Accept 系列字段了解多少?
对于Accept系列字段的介绍分为四个部分: 数据格式、压缩方式、支持语言和字符集。数据格式
上一节谈到 HTTP 灵活的特性,它支持非常多的数据格式,那么这么多格式的数据一起到达客户端,客户端怎么知道它的格式呢?
当然,最低效的方式是直接猜,有没有更好的方式呢?直接指定可以吗?
答案是肯定的。不过首先需要介绍一个标准——MIME(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)。它首先用在电子邮件系统中,让邮件可以发任意类型的数据,这对于 HTTP 来说也是通用的。
因此,HTTP 从MIME type取了一部分来标记报文 body 部分的数据类型,这些类型体现在Content-Type这个字段,当然这是针对于发送端而言,接收端想要收到特定类型的数据,也可以用Accept字段。
具体而言,这两个字段的取值可以分为下面几类:
- text: text/html, text/plain, text/css 等
- image: image/gif, image/jpeg, image/png 等
- audio/video: audio/mpeg, video/mp4 等
application: application/json, application/javascript, application/pdf, application/octet-stream
压缩方式
当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的Content-Encoding字段上, 同样的,接收什么样的压缩方式体现在了接受方的Accept-Encoding字段上。这个字段的取值有下面几种:
gzip: 当今最流行的压缩格式
- deflate: 另外一种著名的压缩格式
- br: 一种专门为 HTTP 发明的压缩算法 ```javascript // 发送端 Content-Encoding: gzip // 接收端 Accept-Encoding: gzip
<a name="fvRyP"></a>### 支持语言对于发送方而言,还有一个Content-Language字段,在需要实现国际化的方案当中,可以用来指定支持的语言,在接受方对应的字段为Accept-Language。如:
// 发送端 Content-Language: zh-CN, zh, en // 接收端 Accept-Language: zh-CN, zh, en
<a name="T25vi"></a>### 字符集最后是一个比较特殊的字段, 在接收端对应为Accept-Charset,指定可以接受的字符集,而在发送端并没有对应的Content-Charset, 而是直接放在了Content-Type中,以**charset**属性指定。如:```javascript// 发送端Content-Type: text/html; charset=utf-8// 接收端Accept-Charset: charset=utf-8
007: 对于定长和不定长的数据,HTTP 是怎么传输的?
定长包体
对于定长包体而言,发送端在传输的时候一般会带上 Content-Length, 来指明包体的长度。
我们用一个nodejs服务器来模拟一下:
const http = require('http');const server = http.createServer();server.on('request', (req, res) => {if(req.url === '/') {res.setHeader('Content-Type', 'text/plain');res.setHeader('Content-Length', 10);res.write("helloworld");}})server.listen(8081, () => {console.log("成功启动");})
启动后访问: localhost:8081。
浏览器中显示如下:
helloworld
这是长度正确的情况,那不正确的情况是如何处理的呢?
我们试着把这个长度设置的小一些:
res.setHeader('Content-Length', 8);
重启服务,再次访问,现在浏览器中内容如下:
hellowor
那后面的ld哪里去了呢?实际上在 http 的响应体中直接被截去了。
然后我们试着将这个长度设置得大一些:
res.setHeader('Content-Length', 12);
此时浏览器显示如下:
直接无法显示了。可以看到Content-Length对于 http 传输过程起到了十分关键的作用,如果设置不当可以直接导致传输失败。
不定长包体
上述是针对于定长包体,那么对于不定长包体而言是如何传输的呢?
这里就必须介绍另外一个 http 头部字段了:
Transfer-Encoding: chunked
表示分块传输数据,设置这个字段后会自动产生两个效果:
- Content-Length 字段会被忽略
- 基于长连接持续推送动态内容
我们依然以一个实际的例子来模拟分块传输,nodejs 程序如下:
const http = require('http');const server = http.createServer();server.on('request', (req, res) => {if(req.url === '/') {res.setHeader('Content-Type', 'text/html; charset=utf8');res.setHeader('Content-Length', 10);res.setHeader('Transfer-Encoding', 'chunked');res.write("<p>来啦</p>");setTimeout(() => {res.write("第一次传输<br/>");}, 1000);setTimeout(() => {res.write("第二次传输");res.end()}, 2000);}})server.listen(8009, () => {console.log("成功启动");})
访问效果入下: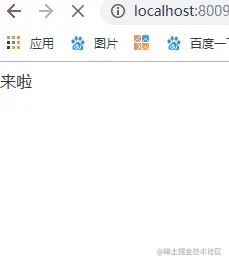
用 telnet 抓到的响应如下: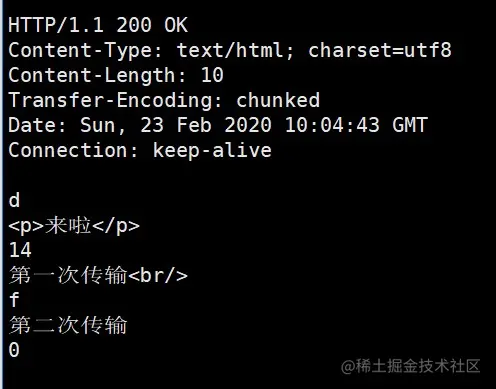
注意,Connection: keep-alive及之前的为响应行和响应头,后面的内容为响应体,这两部分用换行符隔开。
响应体的结构比较有意思,如下所示:
chunk长度(16进制的数)第一个chunk的内容chunk长度(16进制的数)第二个chunk的内容......0
最后是留有有一个空行的,这一点请大家注意。
以上便是 http 对于定长数据和不定长数据的传输方式。
008: HTTP 如何处理大文件的传输?
对于几百 M 甚至上 G 的大文件来说,如果要一口气全部传输过来显然是不现实的,会有大量的等待时间,严重影响用户体验。因此,HTTP 针对这一场景,采取了范围请求的解决方案,允许客户端仅仅请求一个资源的一部分。
如何支持
当然,前提是服务器要支持范围请求,要支持这个功能,就必须加上这样一个响应头:
Accept-Ranges: none
Range 字段拆解
而对于客户端而言,它需要指定请求哪一部分,通过Range这个请求头字段确定,格式为bytes=x-y。接下来就来讨论一下这个 Range 的书写格式:
- 0-499表示从开始到第 499 个字节。
- 500- 表示从第 500 字节到文件终点。
- -100表示文件的最后100个字节。
服务器收到请求之后,首先验证范围是否合法,如果越界了那么返回416错误码,否则读取相应片段,返回206状态码。
同时,服务器需要添加Content-Range字段,这个字段的格式根据请求头中Range字段的不同而有所差异。
具体来说,请求单段数据和请求多段数据,响应头是不一样的。
举个例子:
// 单段数据Range: bytes=0-9// 多段数据Range: bytes=0-9, 30-39
单段数据
对于单段数据的请求,返回的响应如下:
HTTP/1.1 206 Partial ContentContent-Length: 10Accept-Ranges: bytesContent-Range: bytes 0-9/100i am xxxxx
值得注意的是Content-Range字段,0-9表示请求的返回,100表示资源的总大小,很好理解。
多段数据
接下来我们看看多段请求的情况。得到的响应会是下面这个形式:
HTTP/1.1 206 Partial ContentContent-Type: multipart/byteranges; boundary=00000010101Content-Length: 189Connection: keep-aliveAccept-Ranges: bytes--00000010101Content-Type: text/plainContent-Range: bytes 0-9/96i am xxxxx--00000010101Content-Type: text/plainContent-Range: bytes 20-29/96eex jspy e--00000010101--
这个时候出现了一个非常关键的字段Content-Type: multipart/byteranges;boundary=00000010101,它代表了信息量是这样的:
- 请求一定是多段数据请求
- 响应体中的分隔符是 00000010101
因此,在响应体中各段数据之间会由这里指定的分隔符分开,而且在最后的分隔末尾添上—表示结束。
以上就是 http 针对大文件传输所采用的手段。

若有收获,就点个赞吧
0 人点赞
