 正则表达式是用来描述字符模式的对象。它被用来在文本中执行模式匹配(pattern-matching)以及”查找-替换”(search-and-replace)的任务。
正则表达式是用来描述字符模式的对象。它被用来在文本中执行模式匹配(pattern-matching)以及”查找-替换”(search-and-replace)的任务。
前端开发中,我们常常会在这些地方看到正则:
- 验证手机号,邮件,身份证号等是否合法。
- 删除字符串前后多余的空格。
- 从浏览器的UserAgent信息中提取出当前是什么浏览器,以及浏览器的版本。来做一些兼容性处理。
正则表达式给人的感觉:很难读懂,也难写。谁知道下面2个正则是干嘛的吗😂
/<\/?[a-zA-Z]+(\s+[a-zA-Z]+=".*")*>/g/^w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$/ /^[a-zA-Z][a-zA-Z0-9_]{2,6}$/
为什么要学习正则?
正则表达式用简短的代码,能实现非常复杂的文本查找替换操作。用字符串的api来实现同样的功能,代码会复杂的多,代码量也会多的多。比如,验证手机号是否合法。我们假定,合法的手机号指:以1开头的11位数字。
用字符串的api,这么写:
function validPhone(phone) {let isValid = falsephone += ''if (phone.length === 11 && phone[0] === '1' && !isNaN(phone)) {isValid = true}return isValid}
用正则,一行代码搞定:
/^1\d{10}$/.test(phone)
可见,熟练掌握正则表达式,能极大的提升开发文本的查找替换功能的开发效率。
例子
学习正则表达式的最好方法是从例子开始,理解例子之后再自己对例子进行修改。下面,我们就开始吧~
例子1: 精确匹配
查找文本中是否包含cat。代码实现如下:
/cat/.test('I have a cat.') // 返回true/cat/.test('I have a dog.') // 返回 false
上面的代码中,/cat/ 创建了一个匹配 cat 的正则。有两种方式创建正则对象:
/匹配模式/。 如/cat/。new RegExp(匹配模式字符串)。 如new RegExp('cat')。
这两种方式的不同点在于,方式2支持传入变量。
test 是正则对象上的方法,用来检索字符串中是否包含指定的值。返回 true 或 false。还有一个常见的正则方法 exec,用来检索字符串中指定的值。
字符串的split,search,replace,match方法支持传入正则。
例子2: 匹配一类字符:数字,字母,空格等
查找文本是否有数字。代码实现如下
/\d/.test('3C') // true
常见字符类型的匹配方式如下:
.: 匹配一个任意字符。\d: 匹配一个数字。\D: 匹配一个非数字字符。[a-z]: 匹配一个小写字母。[A-Z]: 匹配一个大写字母。[\u4e00-\u9fa5]: 匹配一个中文字。\w: 匹配字母、数字、下划线。等价于[A-Za-z0-9_]。\s: 匹配任何空白字符,包括空格、制表符、换页符等等。\S: 匹配任何非空白字符。\\: 匹配\。
例子3: 匹配指定范围内字符
查找文本中是否包含 ab12 中任意一个字符。代码实现如下:
/[ab12]/.test('a') // true/[ab12]/.test('b') // true/[ab12]/.test('1') // true/[ab12]/.test('2') // true
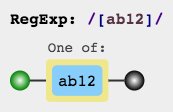
用 [指定范围] 来匹配指定范围内字符。 用 [^指定范围] 来匹配不在指定范围内的字符。如:/[^a-z]/ 匹配非小写字母。
例子4: 匹配重复
查找文本中是否包含5个a。蛮干版,代码实现如下:
/aaaaa/.test('aaaaa') // true
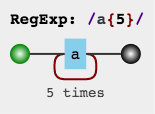
优雅版:
/a{5}/.test('aaaaa') // true
查找文本中是否包含3个ab。代码实现如下:
/(ab){3}/.test('ababab') // true
注意,上面的代码中,用括号包起来ab,把ab变成一个整体。不加括号,匹配的是abbb。
重复字符的匹配方式如下:
- *: 匹配前面的子表达式零次或多次。
- +: 匹配前面的子表达式一次或多次。
- ?: 匹配前面的子表达式零次或一次。
- {n}: 匹配前面的子表达式确定的 n 次。
- {n,}: 匹配前面的子表达式至少 n 次。
- {n,m}: 匹配前面的子表达式 n 到 m之间。
更多例子:
/a\*/ // 匹配任意个a/https?/ // 匹配 http 和 https/1\d{10}/ // 11位手机号
例子5: 匹配文本以…开始和以…结尾
查找文本是否以字母开头,以数字结尾。代码实现如下:
/^[a-zA-Z].*\d$/.test('ab1') // true
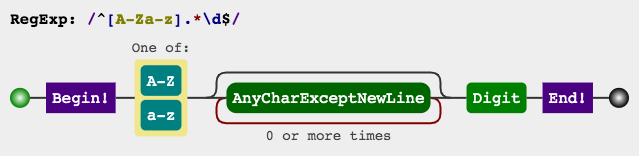
^用来匹配输入字符串的开始位置。$用来匹配输入字符串的结束位置。
例子6: 匹配多种情况
查找文本是包含138或包含159。代码实现如下:
/(138|159)/.test('138') // true/(138|159)/.test('159') // true

|用来匹配多种情况。注意,情况包含的字符数量超过一个,要用括号包起来。反例:
/138|159/.test('138') // false/138|159/.test('13859') // true/138|159/.test('13159') // true
例子7: 匹配模式
查找文本中是否全部是字母。实现方法1:
/^[a-zA-Z]*$/.test('abcABC') // true
方法2:
/^[a-z]*$/i.test('abcABC') // true
方法2中的i是匹配模式。常见的匹配模式如下:
- g : 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)
- i : 执行对大小写不敏感的匹配。
- m : 执行多行匹配。
一个正则可以有多个模式,表示对多个模式的叠加。如 /a/ig。
例子8: 匹配的争夺:贪婪模式和非贪婪模式
匹配文本中的非空白字符和数字,要尽量多匹配数字。代码实现如下:
/(\S+?)(\d*)/.exec('a123') // ["a123", "a", "123"]// 这种写法,会尽可能多的匹配非空白字符:/(\S+)(\d*)/.exec('a123') // ["a123", "a123", ""]

当正则表达式中包重复的限定符(*+,?, {n}, {n,}, {n,m})时,匹配模式是贪婪的:匹配尽可能多的字符。在重复的限定符后加?,会将匹配模式改成非贪婪的:匹配尽可能少的字符。
例子9: 文本替换
将文本中单词”cat”替换成”dog”。代码实现如下:
'I have a cat.'.replace(/cat/, 'dog') // 运行结果 I have a dog.
将文本中所有的单词”cat”替换成”dog”。代码实现如下:
'cat,cat,cat'.replace(/cat/g, 'dog') // 运行结果 dog,dog,dog
将第2个出现的”cat”替换成”dog”。代码实现如下:
let appearNum = 0let res = 'cat,cat,cat'.replace(/cat/g, (matched) => {appearNum++if(appearNum === 2) {return 'dog'} else {return matched}})console.log(res) // 运行结果 cat,dog,cat
推荐工具
RegExr
正则测试工具。
Regulex
JavaScript 正则可视化工具。展示效果:
总结
熟练掌握正则表达式,能极大的提升开发文本的查找替换功能的开发效率。大家有必要去认真学一下。
本文介绍了正则的基础。正则博大精深,还有很多值得研究。
参考&推荐阅读

若有收获,就点个赞吧
0 人点赞
