算法学习其实是一种提高思维能力的过程。无论是学习算法,还是在面试或实际的工作、生活中,我们都会碰见一些从没遇到过的问题。解决方法也类似,先推敲最直观的解法,再对某个步骤进行优化。例如,讲前缀树的例题时,我们正是为了要提高匹配字符串的速度才借用了前缀树的。
从这节课开始,我们会将宝贵的时间、精力针对性地去学习面试中最常考的、最核心的算法。而这节课要学习的是排序算法,包括:
- 基本的排序算法
- 冒泡排序(Bubble Sort)
- 插入排序(Insertion Sort)
- 常考的排序算法
- 归并排序(Merge Sort)
- 快速排序(Quick Sort)
- 拓扑排序(Topological Sort)
- 其他排序算法
- 堆排序(Heap Sort)
- 桶排序(Bucket Sort)
注意:冒泡排序和插入排序是最基础的,面试官有时候喜欢拿它们来考察你的基础知识,并且看看你能不能快速地写出没有 bug 的代码。
归并排序、快速排序和拓扑排序的思想是解决绝大部分涉及排序问题的关键,我们将在这节课里重点介绍它们。
堆排序和桶排序,本节课不作深入研究,但有时间的话一定要看看,尤其是桶排序,在一定的场合中(例如知道所有元素出现的范围时),能在线性的时间复杂度里解决战斗,掌握好它的解题思想能开阔解题思路。
冒泡排序(Bubble Sort)
基本思想:给定一个数组,我们把数组里的元素通通倒入到水池中,这些元素将通过相互之间的比较,按照大小顺序一个一个地像气泡一样浮出水面。
实现:每一轮,从杂乱无章的数组头部开始,每两个元素比较大小并进行交换,直到这一轮当中最大或最小的元素被放置在数组的尾部,然后不断地重复这个过程,直到所有元素都排好位置。其中,核心操作就是元素相互比较。
例题分析 :给定数组 [2, 1, 7, 9, 5, 8],要求按照从左到右、从小到大的顺序进行排序。
解题思路
从左到右依次冒泡,把较大的数往右边挪动即可。
- 首先指针指向第一个数,比较第一个数和第二个数的大小,由于 2 比 1 大,所以两两交换,[1, 2, 7, 9, 5, 8]。
- 接下来指针往前移动一步,比较 2 和 7,由于 2 比 7 小,两者保持不动,[1, 2, 7, 9, 5, 8]。到目前为止,7 是最大的那个数。
- 指针继续往前移动,比较 7 和 9,由于 7 比 9 小,两者保持不动,[1, 2, 7, 9, 5, 8]。现在,9 变成了最大的那个数。
- 再往后,比较 9 和 5,很明显,9 比 5 大,交换它们的位置,[1, 2, 7, 5, 9, 8]。
- 最后,比较 9 和 8,9 比 8 大,交换它们的位置,[1, 2, 7, 5, 8, 9]。经过第一轮的两两比较,9 这个最大的数就像冒泡一样冒到了数组的最后面。
接下来进行第二轮的比较,把指针重新指向第一个元素,重复上面的操作,最后,数组变成了:[1, 2, 5, 7, 8, 9]。
在进行新一轮的比较中,判断一下在上一轮比较的过程中有没有发生两两交换,如果一次交换都没有发生,就证明其实数组已经排好序了。
代码示例
void sort(int[] nums) {//定义一个布尔变量 hasChange,用来标记每轮遍历中是否发生了交换boolean hasChange = true;//每轮遍历开始,将 hasChange 设置为 falsefor (int i = 0; i < nums.length - 1 && hasChange; i++) {hasChange = false;//进行两两比较,如果发现当前的数比下一个数还大,那么就交换这两个数,同时记录一下有交换发生for (int j = 0; j < nums.length - 1 - i; j++) {if (nums[j] > nums[j + 1]) {swap(nums, j, j + 1);hasChange = true;}}}}
算法分析
空间复杂度:假设数组的元素个数是 n,由于在整个排序的过程中,我们是直接在给定的数组里面进行元素的两两交换,所以空间复杂度是 O(1)。
时间复杂度
1. 给定的数组按照顺序已经排好
在这种情况下,我们只需要进行 n−1 次的比较,两两交换次数为 0,时间复杂度是 O(n)。这是最好的情况。
- 给定的数组按照逆序排列
在这种情况下,我们需要进行 n(n-1)/2 次比较,时间复杂度是 O(n2)。这是最坏的情况。
- 给定的数组杂乱无章
在这种情况下,平均时间复杂度是 O(n2)。
由此可见,冒泡排序的时间复杂度是 O(n2)。它是一种稳定的排序算法。(稳定是指如果数组里两个相等的数,那么排序前后这两个相等的数的相对位置保持不变。)
插入排序(Insertion Sort)
基本思想 :不断地将尚未排好序的数插入到已经排好序的部分。
特点:在冒泡排序中,经过每一轮的排序处理后,数组后端的数是排好序的;而对于插入排序来说,经过每一轮的排序处理后,数组前端的数都是排好序的。
例题分析 :对数组 [2, 1, 7, 9, 5, 8] 进行插入排序。
解题思路
首先将数组分成左右两个部分,左边是已经排好序的部分,右边是还没有排好序的部分,刚开始,左边已排好序的部分只有第一个元素 2。接下来,我们对右边的元素一个一个进行处理,将它们放到左边。
- 先来看 1,由于 1 比 2 小,需要将 1 插入到 2 的前面,做法很简单,两两交换位置即可,[1, 2, 7, 9, 5, 8]。
- 然后,我们要把 7 插入到左边的部分,由于 7 已经比 2 大了,表明它是目前最大的元素,保持位置不变,[1, 2, 7, 9, 5, 8]。
- 同理,9 也不需要做位置变动,[1, 2, 7, 9, 5, 8]。
- 接下来,如何把 5 插入到合适的位置。首先比较 5 和 9,由于 5 比 9 小,两两交换,[1, 2, 7, 5, 9, 8],继续,由于 5 比 7 小,两两交换,[1, 2, 5, 7, 9, 8],最后,由于 5 比 2 大,此轮结束。
- 最后一个数是 8,由于 8 比 9 小,两两交换,[1, 2, 5, 7, 8, 9],再比较 7 和 8,发现 8 比 7 大,此轮结束。到此,插入排序完毕
代码示例
void sort(int[] nums) {// 将数组的第一个元素当作已经排好序的,从第二个元素,即 i 从 1 开始遍历数组for (int i = 1, j, current; i < nums.length; i++) {// 外围循环开始,把当前 i 指向的值用 current 保存current = nums[i];// 指针 j 内循环,和 current 值比较,若 j 所指向的值比 current 值大,则该数右移一位for (j = i - 1; j >= 0 && nums[j] > current; j--) {nums[j + 1] = nums[j];}// 内循环结束,j+1 所指向的位置就是 current 值插入的位置nums[j + 1] = current;}}
算法分析
空间复杂度:假设数组的元素个数是 n,由于在整个排序的过程中,是直接在给定的数组里面进行元素的两两交换,空间复杂度是 O(1)。
时间复杂度
- 给定的数组按照顺序已经排好
只需要进行 n-1 次的比较,两两交换次数为 0,时间复杂度是 O(n)。这是最好的情况。
- 给定的数组按照逆序排列
在这种情况下,我们需要进行 n(n-1)/2 次比较,时间复杂度是 O(n2)。这是最坏的情况。
- 给定的数组杂乱无章
在这种情况下,平均时间复杂度是 O(n2)。
由此可见,和冒泡排序一样,插入排序的时间复杂度是 O(n2),并且它也是一种稳定的排序算法。
建议:LeetCode 第 147 题,要求对一个链表进行插入排序,希望大家去试一试。
归并排序(Merge Sort)
基本思想 :核心是分治,就是把一个复杂的问题分成两个或多个相同或相似的子问题,然后把子问题分成更小的子问题,直到子问题可以简单的直接求解,最原问题的解就是子问题解的合并。归并排序将分治的思想体现得淋漓尽致。
实现
一开始先把数组从中间划分成两个子数组,一直递归地把子数组划分成更小的子数组,直到子数组里面只有一个元素,才开始排序
排序的方法就是按照大小顺序合并两个元素,接着依次按照递归的返回顺序,不断地合并排好序的子数组,直到最后把整个数组的顺序排好。
代码示例
主体函数的代码实现如下。
void sort(int[] A, int lo, int hi) {// 判断是否只剩下最后一个元素if (lo >= hi) return;// 从中间将数组分成两个部分int mid = lo + (hi - lo) / 2;// 分别递归地将左右两半排好序sort(A, lo, mid);sort(A, mid + 1, hi);// 将排好序的左右两半合并merge(A, lo, mid, hi);}
归并操作的代码实现如下。
void merge(int[] nums, int lo, int mid, int hi) {// 复制一份原来的数组int[] copy = nums.clone();// 定义一个 k 指针表示从什么位置开始修改原来的数组,i 指针表示左半边的起始位置,j 表示右半边的起始位置int k = lo, i = lo, j = mid + 1;while (k <= hi) {if (i > mid) {nums[k++] = copy[j++];} else if (j > hi) {nums[k++] = copy[i++];} else if (copy[j] < copy[i]) {nums[k++] = copy[j++];} else {nums[k++] = copy[i++];}}}
其中,While 语句比较,一共可能会出现四种情况。
- 左半边的数都处理完毕,只剩下右半边的数,只需要将右半边的数逐个拷贝过去。
- 右半边的数都处理完毕,只剩下左半边的数,只需要将左半边的数逐个拷贝过去就好。
- 右边的数小于左边的数,将右边的数拷贝到合适的位置,j 指针往前移动一位。
- 左边的数小于右边的数,将左边的数拷贝到合适的位置,i 指针往前移动一位。
例题分析
例题:利用归并排序算法对数组 [2, 1, 7, 9, 5, 8] 进行排序。
解题思路
首先不断地对数组进行切分,直到各个子数组里只包含一个元素。
接下来递归地按照大小顺序合并切分开的子数组,递归的顺序和二叉树里的前向遍历类似。
- 合并 [2] 和 [1] 为 [1, 2]。
- 子数组 [1, 2] 和 [7] 合并。
- 右边,合并 [9] 和 [5]。
- 然后合并 [5, 9] 和 [8]。
- 最后合并 [1, 2, 7] 和 [5, 8, 9] 成 [1, 2, 5, 8, 9],就可以把整个数组排好序了。
合并数组 [1, 2, 7] 和 [5, 8, 9] 的操作步骤如下。
- 把数组 [1, 2, 7] 用 L 表示,[5, 8, 9] 用 R 表示。
- 合并的时候,开辟分配一个新数组 T 保存结果,数组大小应该是两个子数组长度的总和
- 然后下标 i、j、k 分别指向每个数组的起始点。
- 接下来,比较下标i和j所指向的元素 L[i] 和 R[j],按照大小顺序放入到下标 k 指向的地方,1 小于 5。
- 移动 i 和 k,继续比较 L[i] 和 R[j],2 比 5 小。
- i 和 k 继续往前移动,5 比 7 小。
- 移动 j 和 k,继续比较 L[i] 和 R[j],7 比 8 小。
- 这时候,左边的数组已经处理完毕,直接将右边数组剩余的元素放到结果数组里就好。
合并之所以能成功,先决条件必须是两个子数组都已经分别排好序了。
算法分析
空间复杂度 :由于合并 n 个元素需要分配一个大小为 n 的额外数组,合并完成之后,这个数组的空间就会被释放,所以算法的空间复杂度就是 O(n)。归并排序也是稳定的排序算法。
时间复杂度 :归并算法是一个不断递归的过程。
举例:数组的元素个数是 n,时间复杂度是 T(n) 的函数。
解法:把这个规模为 n 的问题分成两个规模分别为 n/2 的子问题,每个子问题的时间复杂度就是 T(n/2),那么两个子问题的复杂度就是 2×T(n/2)。当两个子问题都得到了解决,即两个子数组都排好了序,需要将它们合并,一共有 n 个元素,每次都要进行最多 n-1 次的比较,所以合并的复杂度是 O(n)。由此我们得到了递归复杂度公式:T(n) = 2×T(n/2) + O(n)。
对于公式求解,不断地把一个规模为 n 的问题分解成规模为 n/2 的问题,一直分解到规模大小为 1。如果 n 等于 2,只需要分一次;如果 n 等于 4,需要分 2 次。这里的次数是按照规模大小的变化分类的。
以此类推,对于规模为 n 的问题,一共要进行 log(n) 层的大小切分。在每一层里,我们都要进行合并,所涉及到的元素其实就是数组里的所有元素,因此,每一层的合并复杂度都是 O(n),所以整体的复杂度就是 O(nlogn)。
建议:归并算法的思想很重要,其中对两个有序数组合并的操作,在很多面试题里都有用到,建议大家一定要把这个算法练熟。
快速排序(Quick Sort)
基本思想:快速排序也采用了分治的思想。
实现:把原始的数组筛选成较小和较大的两个子数组,然后递归地排序两个子数组。
举例:把班里的所有同学按照高矮顺序排成一排。
解法:老师先随机地挑选了同学 A,让所有其他同学和 A 比高矮,比 A 矮的都站在 A 的左边,比 A 高的都站在 A 的右边。接下来,老师分别从左边和右边的同学里选择了同学 B 和 C,然后不断地筛选和排列下去。
在分成较小和较大的两个子数组过程中,如何选定一个基准值(也就是同学 A、B、C 等)尤为关键。
例题分析
对数组 [2, 1, 7, 9, 5, 8] 进行排序。
解题思路
按照快速排序的思想,首先把数组筛选成较小和较大的两个子数组。
随机从数组里选取一个数作为基准值,比如 7,于是原始的数组就被分成了两个子数组。注意:快速排序是直接在原始数组里进行各种交换操作,所以当子数组被分割出来的时候,原始数组里的排列也被改变了。
接下来,在较小的子数组里选 2 作为基准值,在较大的子数组里选 8 作为基准值,继续分割子数组。
继续将元素个数大于 1 的子数组进行划分,当所有子数组里的元素个数都为 1 的时候,原始数组也被排好序了。
代码示例
主体函数代码如下。
void sort(int[] nums, int lo, int hi) {if (lo >= hi) return; // 判断是否只剩下一个元素,是,则直接返回// 利用 partition 函数找到一个随机的基准点int p = partition(nums, lo, hi);// 递归地对基准点左半边和右半边的数进行排序sort(nums, lo, p - 1);sort(nums, p + 1, hi);}
下面用代码实现 partition 函数获得基准值。
int partition(int[] nums, int lo, int hi) {// 随机选择一个数作为基准值,nums[hi] 就是基准值swap(nums, randRange(lo, hi), hi);int i, j;// 从左到右用每个数和基准值比较,若比基准值小,则放到指针 i 所指向的位置。循环完毕后,i 指针之前的数都比基准值小for (i = lo, j = lo; j < hi; j++) {if (nums[j] <= nums[hi]) {swap(nums, i++, j);}}// 末尾的基准值放置到指针 i 的位置,i 指针之后的数都比基准值大swap(nums, i, j);// 返回指针 i,作为基准点的位置return i;}
算法分析
时间复杂度
1. 最优情况:被选出来的基准值都是当前子数组的中间数。
这样的分割,能保证对于一个规模大小为 n 的问题,能被均匀分解成两个规模大小为 n/2 的子问题(归并排序也采用了相同的划分方法),时间复杂度就是:T(n) = 2×T(n/2) + O(n)。
把规模大小为 n 的问题分解成 n/2 的两个子问题时,和基准值进行了 n-1 次比较,复杂度就是 O(n)。很显然,在最优情况下,快速排序的复杂度也是 O(nlogn)。
- 最坏情况:基准值选择了子数组里的最大或者最小值
每次都把子数组分成了两个更小的子数组,其中一个的长度为 1,另外一个的长度只比原子数组少 1
举例:对于数组来说,每次挑选的基准值分别是 9、8、7、5、2
解法:划分过程和冒泡排序的过程类似。
算法复杂度为 O(n2)。
提示:可以通过随机地选取基准值来避免出现最坏的情况。
空间复杂度
和归并排序不同,快速排序在每次递归的过程中,只需要开辟 O(1) 的存储空间来完成交换操作实现直接对数组的修改,又因为递归次数为 logn,所以它的整体空间复杂度完全取决于压堆栈的次数,因此它的空间复杂度是 O(logn)
举例:LeetCode 第 215 题,给定一个尚未排好序的数组,要求找出第 k 大的数。
解法 1:直接将数组进行排序,然后得出结果。
解法 2:快速排序。
每次随机选取一个基准值,将数组分成较小的一半和较大的一半,然后检查这个基准值最后所在的下标是不是 k,算法复杂度只需要 O(n)。
拓扑排序(Topological Sort)
基本思想: 和前面介绍的几种排序不同,拓扑排序应用的场合不再是一个简单的数组,而是研究图论里面顶点和顶点连线之间的性质。拓扑排序就是要将这些顶点按照相连的性质进行排序。
要能实现拓扑排序,得有几个前提:
- 图必须是有向图
- 图里面没有环
拓扑排序一般用来理清具有依赖关系的任务。
举例:假设有三门课程 A、B、C,如果想要学习课程 C 就必须先把课程 B 学完,要学习课程 B,还得先学习课程 A,所以得出课程的学习顺序应该是 A -> B -> C。
实现:将问题用一个有向无环图(DAG, Directed Acyclic Graph)进行抽象表达,定义出哪些是图的顶点,顶点之间如何互相关联。
可以利用广度优先搜索或深度优先搜索来进行拓扑排序。
例题分析:有一个学生想要修完 5 门课程的学分,这 5 门课程分别用 1、2、3、4、5 来表示,现在已知学习这些课程有如下的要求:
- 课程 2 和 4 依赖于课程 1
- 课程 3 依赖于课程 2 和 4
- 课程 4 依赖于课程 1 和 2
- 课程 5 依赖于课程 3 和 4
那么这个学生应该按照怎样的顺序来学习这 5 门课程呢?
解题思路
可以把 5 门课程看成是一个图里的 5 个顶点,用有向线段按照它们的相互关系连起来,于是得出下面的有向图。
首先可以看到,这个有向图里没有环,无论从哪个顶点出发,都不会再回到那个顶点。并且,这个图里并没有孤岛的出现,因此,我们可以对它进行拓扑排序。
方法就是,一开始的时候,对每个顶点统计它们各自的前驱(也就是入度):1(0),2(1),3(2),4(1),5(2)。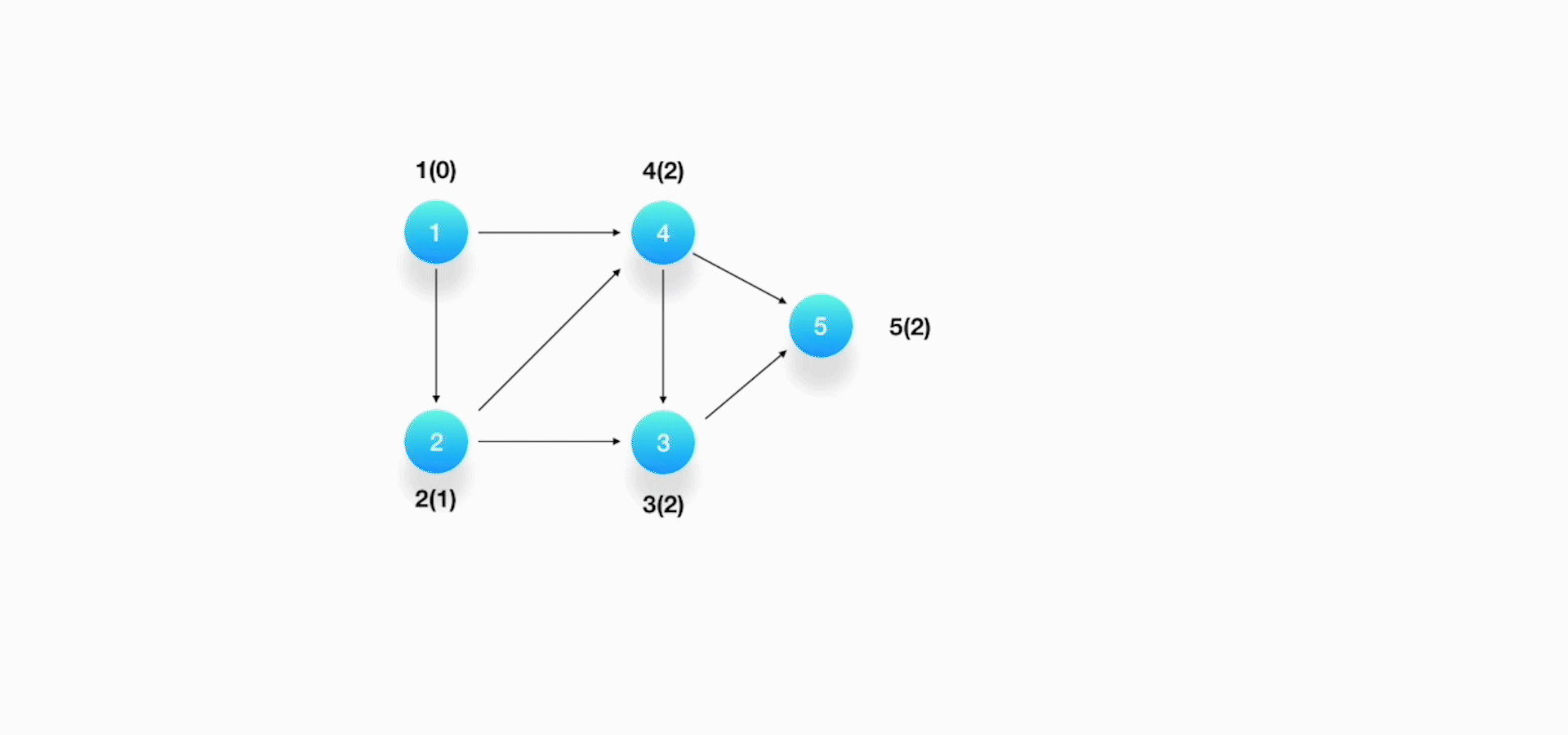 选择其中一个没有前驱(也就是入度为 0)的顶点,在这道题里面,顶点 1 就是我们要找的那个点,将它作为结果输出。同时删除掉该顶点和所有以它作为起始点的有向边,更新顶点的入度表。
选择其中一个没有前驱(也就是入度为 0)的顶点,在这道题里面,顶点 1 就是我们要找的那个点,将它作为结果输出。同时删除掉该顶点和所有以它作为起始点的有向边,更新顶点的入度表。
- 接下来,顶点 2 就是下一个没有前驱的顶点,输出顶点 2,并将以它作为起点的有向边删除,同时更新入度表。
- 再来,顶点 4 成为了没有前驱的顶点,输出顶点 4,删除掉它和顶点 3 和 5 的有向边。
- 然后,顶点 3 没有了前驱,输出它,并删除它与 5 的有向边。
- 最后,顶点 5 没有前驱,输出它,于是得出最后的结果为:1,2,4,3,5。
一般来说,一个有向无环图可以有一个或多个拓扑排序的序列。
代码示例
运用广度优先搜索的方法对这个图的结构进行遍历。在构建这个图的过程中,用一个链接矩阵 adj 来表示这个图的结构,用一个 indegree 的数组统计每个顶点的入度,重点看如何实现拓扑排序。
void sort() {Queue<Integer> q = new LinkedList(); // 定义一个队列 q// 将所有入度为 0 的顶点加入到队列 qfor (int v = 0; v < V; v++) {if (indegree[v] == 0) q.add(v);}// 循环,直到队列为空while (!q.isEmpty()) {int v = q.poll();// 每次循环中,从队列中取出顶点,即为按照入度数目排序中最小的那个顶点print(v);// 将跟这个顶点相连的其他顶点的入度减 1,如果发现那个顶点的入度变成了 0,将其加入到队列的末尾for (int u = 0; u < adj[v].length; u++) {if (--indegree[u] == 0) {q.add(u);}}}}
算法分析
时间复杂度:统计顶点的入度需要 O(n) 的时间,接下来每个顶点被遍历一次,同样需要 O(n) 的时间,所以拓扑排序的时间复杂度是 O(n)。
建议:利用深度优先搜索的方法对这道题实现拓扑排序。
结语:这节课复习了面试中经常会被考到的排序算法,最重点内容是归并排序和快速排序。除了要好好理解它们的思路,还必须要能写出没有 bug 的代码,因此建议多做 LeetCode 里面的经典题目。

若有收获,就点个赞吧
0 人点赞
