[TOC]
浏览器渲染主要流程
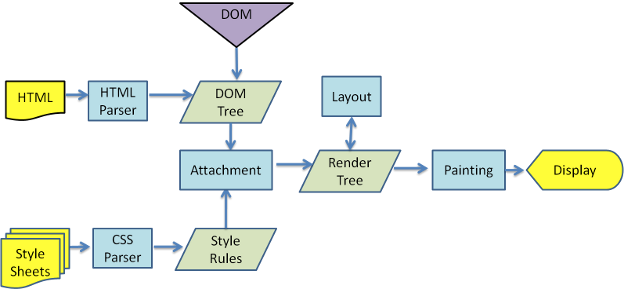
1.HTML 解析出 DOM Tree
2.CSS 解析出 Style Rules
3.将两者关联生成 Render Tree
4.Layout 根据 Render Tree 计算每个节点的信息
5.Painting 根据计算好的信息绘制整个页面
1)浏览器会解析三个东西
- 一个是html/svg/xhtml ,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
- CSS,解析CSS会产生CSS规则树。
- Javascript,脚本,主要是通过DOM API 和 CSSOM API 来操作DOM Tree 和 CSS Rule Tree
2) 解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造Rendering Tree。注意:
- Rendering Tree 渲染树并不等同于DOM树,因为像一些Header或display:none的东西就没必要放在渲染树中了
- CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule 附加上 Rendering Tree 上的每个Element,也就是DOM节点,所谓的Frame。
- 然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI 的API绘制。
HTML 解析
HTML Parser 的任务是将HTML 标记解析成 DOM Tree
例如:
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>
经过解析之后的DOM Tree 差不多就是
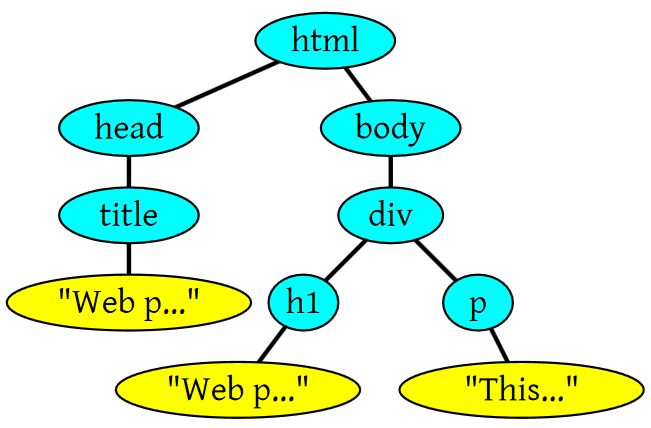
将文本的HTML文档,提炼出关键信息,嵌套层级的树形结构,便于计算拓展,这就是HTML Parse的作用。
CSS 解析
CSS Parse 将CSS解析成 Style Rules,Style Rules也叫CSSOM(CSS Object Model).
StyleRules 也是一个树形结构,根据CSS文件整理出来的类似DOM Tree的树形结构
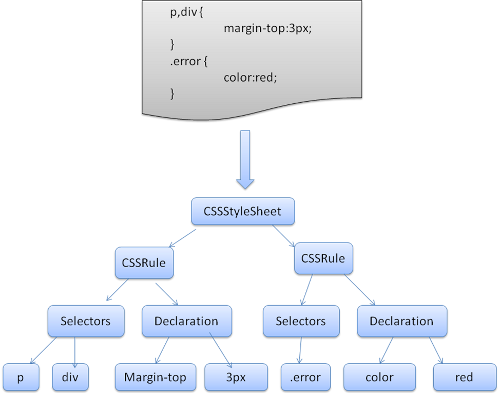
于 HTML Parser 相似,CSS Parser作用就是将很多个CSS文件中的样式合并解析出具有树形结构Style Rules.
脚本处理
浏览器解析文档,当遇到

若有收获,就点个赞吧
0 人点赞
