15 | 消息队列和事件循环:页面是怎么“活”起来的?
消息队列:
消息队列是一种数据结构,可以存放要执行的任务,它符合队列“先进先出”的特点,也就是说要添加任务的话,添加到队列的尾部;要取出任务的话,从队列头部去取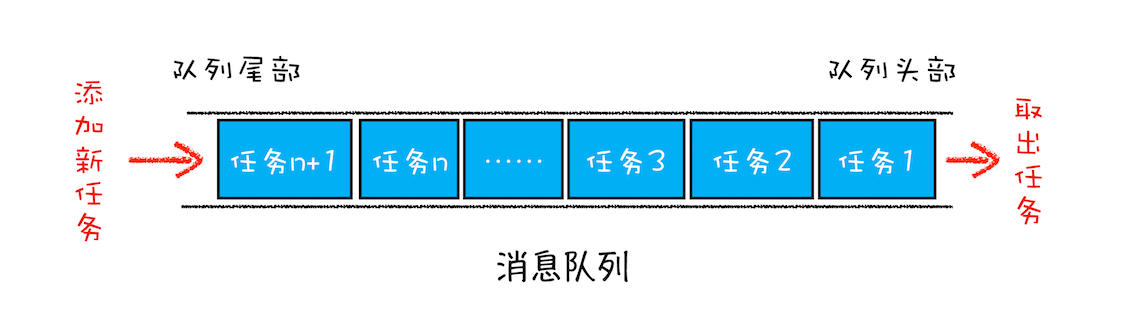
事件循环
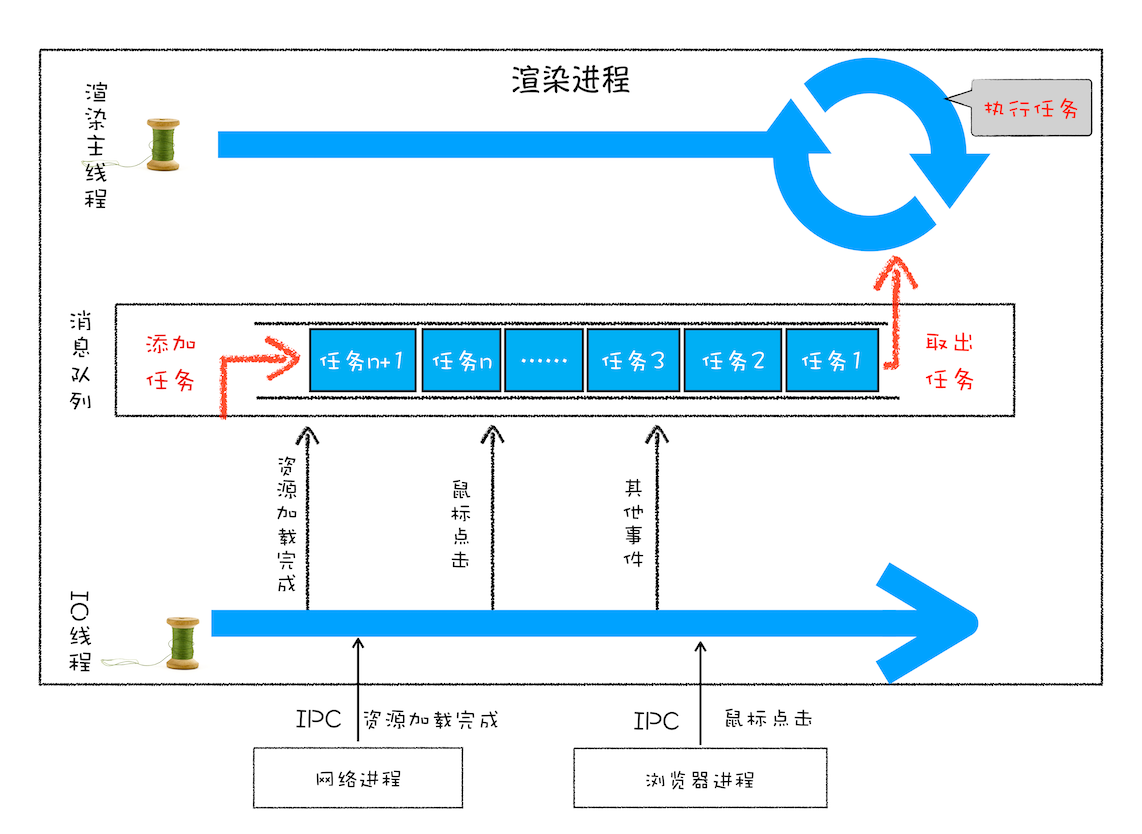
线程模型
- IO 线程将用户事件和从其他进程传递过来的任务,放入消息队列的尾部
- 渲染主线程会循环从消息队列的头部读取任务,执行任务
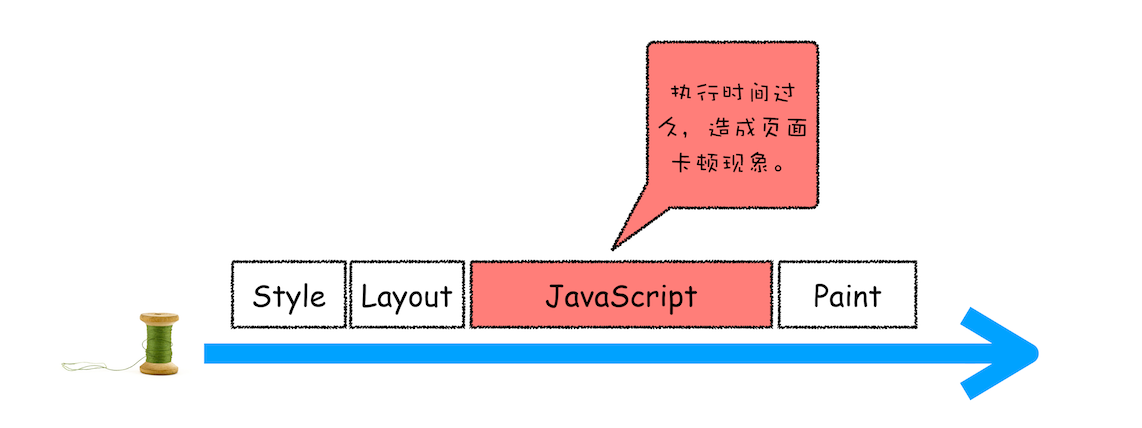
消息队列中的任务类型
- 内部消息类型:输入事件(鼠标滚动、点击)、微任务、文件读写、websocket、JavaScript定时器
- 页面相关的事件:JavaScript执行、解析DOM、样式计算、布局计算、CSS动画
页面使用单线程的缺点
- 第一个问题是如何处理高优先级的任务 ==> 微任务(每一个宏任务都有一个微任务队列)
- 每个宏任务都有一个微任务列表,在宏任务的执行过程中产生微任务会被添加到改列表中,等宏任务快执行结束之后,会执行微任务列表,所以微任务依然运行在当前宏任务的执行环境中,这个特性会导致宏任务和微任务有一些本质上的区别
- 第二个是如何解决单个任务执行时长过久的问题 ==> 回调(让要执行的 JavaScript 任务滞后执行)
16 | WebAPI:setTimeout是如何实现的?
浏览器怎么实现 setTimeout**
消息队列和事件循环系统
渲染进程中所有运行在主线程的任务都需要先添加到消息队列中,然后事件循环再按照顺序执行消息队列中的任务。异步任务:
在Chrome中除了正常使用的消息队列之外,还维护了一个需要延迟执行的任务列表,包括了定时器和Chromium内部一些需要延迟执行的任务,当JS 创建了一个定时器时,渲染进程会将定时器的回调任务添加到延迟队列中。
延迟执行队列的定义
DelayedIncomingQueue delayed_incoming_queue;
当通过 JavaScript 调用 setTimeout 设置回调函数的时候
struct DelayTask{int64 id;CallBackFunction cbf;int start_time;int delay_time;};DelayTask timerTask;timerTask.cbf = showName;timerTask.start_time = getCurrentTime(); //获取当前时间timerTask.delay_time = 200;//设置延迟执行时间
创建好回调任务之后,再将该任务添加到延迟执行队列中
delayed_incoming_queue.push(timerTask);
现在通过定时器发起的任务就被保存到延迟队列中了,那接下来我们再来看看消息循环系统是怎么触发延迟队列的。
void ProcessTimerTask(){//从delayed_incoming_queue中取出已经到期的定时器任务//依次执行这些任务}TaskQueue task_queue;void ProcessTask();bool keep_running = true;void MainTherad(){for(;;){//执行消息队列中的任务Task task = task_queue.takeTask();ProcessTask(task);//执行延迟队列中的任务ProcessDelayTask()if(!keep_running) //如果设置了退出标志,那么直接退出线程循环break;}}
- 处理完消息队列中的一个任务后,就开始执行ProcessDelayTask函数
- ProcessDelayTask函数会根据发起时间和延迟时间计算出到期的任务,然后依次执行这些到期的任务
-
取消定时器任务
当一个定时器的任务还没有被执行的时候,是可以取消的,通过调用
clearTimeout函数传入需要取消的定时器ID,本质是从 delayed_incoming_queue 延迟队列中,通过 ID 查找到对应的任务,然后再将其从队列中删除掉就可以了使用 setTimeout 的一些注意事项
如果当前任务执行时间过久,会影响定时器任务的执行
如果消息队列中的任务执行时间过长,会延迟执行延迟队列里的任务,导致setTimeout里回调任务执 行时间比预期要久
如果 setTimeout 存在嵌套调用,那么系统会设置最短时间间隔为 4 毫秒
function cb() { setTimeout(cb, 0); }setTimeout(cb, 0);
在 Chrome 中,定时器被嵌套调用 5 次以上,系统会判断该函数方法被阻塞了,如果定时器的调用时间间隔小于 4 毫秒,那么浏览器会将每次调用的时间间隔设置为 4 毫秒未激活的页面,setTimeout 执行最小间隔是 1000 毫秒
- 延时执行时间有最大值
延时执行的最大时间不能超过 2也就是2147483647 毫秒(大约 24.8 天)
超过就会溢出,那么相当于延时值被设置为 0 了,这导致定时器会被立即执行
function showName(){console.log("极客时间")}var timerID = setTimeout(showName,2147483648);//会被理解调用执行
使用 setTimeout 设置的回调函数中的 this 不符合直觉
var name= 1;var MyObj = {name: 2,showName: function(){console.log(this.name); // 输出1,非严格模式下,this指向window,严格模式下,被设置为undefined}}setTimeout(MyObj.showName,1000)
解决方案:
将MyObj.showName放在匿名函数中执行
//箭头函数setTimeout(() => {MyObj.showName()}, 1000);//或者function函数setTimeout(function() {MyObj.showName();}, 1000)
使用 bind 方法
setTimeout(MyObj.showName.bind(MyObj), 1000)
思考时间
由于setTimeout 设置的回调任务实时性并不是很好,所有很多场景并不适合使用setTimeout, 比如用JS实现动画等,用requestAnimationFrame会更高
requestAnimationFrame**
- 不需要设置具体的时间,由系统决定回调函数的执行时间
- raf里面设置的回调函数在页面刷新之前执行,它跟着屏幕的刷新频率走,保证每个刷新间隔只执行一次
如果页面未激活,raf也会停止渲染,既可以保证页面的流畅性,也可以节省主线程执行函数的开销
17 | WebAPI:XMLHttpRequest是怎么实现的?
回调函数 VS 系统调用栈
回调函数(callback function)将一个函数作为参数传递给另一个函数,那作为参数的这个函数就是回调函数
同步回调:回调函数是在主函数返回之前执行的
let callback = function(){console.log('i am do homework')}function doWork(cb) {console.log('start do work')cb()console.log('end do work')}doWork(callback)
异步回调:回调函数 callback 是在主函数 doWork 返回之后执行的
- 第一种是把异步函数做成一个任务,添加到信息队列尾部;
- 第二种是把异步函数添加到微任务队列中,这样就可以在当前任务的末尾处执行微任务了
系统调用栈let callback = function(){console.log('i am do homework')}function doWork(cb) {console.log('start do work')setTimeout(cb,1000)console.log('end do work')}doWork(callback)
当循环系统在执行一个任务的时候,都要为这个任务维护一个系统调用栈,类似于JS的调用栈XMLHttpRequest 运作机制
 ```javascript
```javascript
function GetWebData(URL){ /**
1:新建XMLHttpRequest请求对象 */ let xhr = new XMLHttpRequest()
/**
2:注册相关事件回调处理函数 */ xhr.onreadystatechange = function () { switch(xhr.readyState){ case 0: //请求未初始化
console.log("请求未初始化")break;
case 1://OPENED
console.log("OPENED")break;
case 2://HEADERS_RECEIVED
console.log("HEADERS_RECEIVED")break;
case 3://LOADING
console.log("LOADING")break;
case 4://DONE
if(this.status == 200||this.status == 304){console.log(this.responseText);}console.log("DONE")break;
} }
xhr.ontimeout = function(e) { console.log(‘ontimeout’) } xhr.onerror = function(e) { console.log(‘onerror’) }
/**
- 3:打开请求 */ xhr.open(‘Get’, URL, true);//创建一个Get请求,采用异步
/*** 4:配置参数*/xhr.timeout = 3000 //设置xhr请求的超时时间xhr.responseType = "text" //设置响应返回的数据格式xhr.setRequestHeader("X_TEST","time.geekbang")/*** 5:发送请求*/xhr.send();
}
**第一步:创建 XMLHttpRequest 对象**```javascriptlet xhr = new XMLHttpRequest()
第二步:为 xhr 对象注册回调函数
因为网络请求比较耗时,所以要注册回调函数,这样后台任务执行完成之后就会通过调用回调函数来告诉其执行结果
- ontimeout,用来监控超时请求,如果后台请求超时了,该函数会被调用;
- onerror,用来监控出错信息,如果后台请求出错了,该函数会被调用;
- onreadystatechange,用来监控后台请求过程中的状态,比如可以监控到 HTTP 头加载完成的消息、HTTP 响应体消息以及数据加载完成的消息等。
第三步:配置基础的请求信息
第四步:发起请求
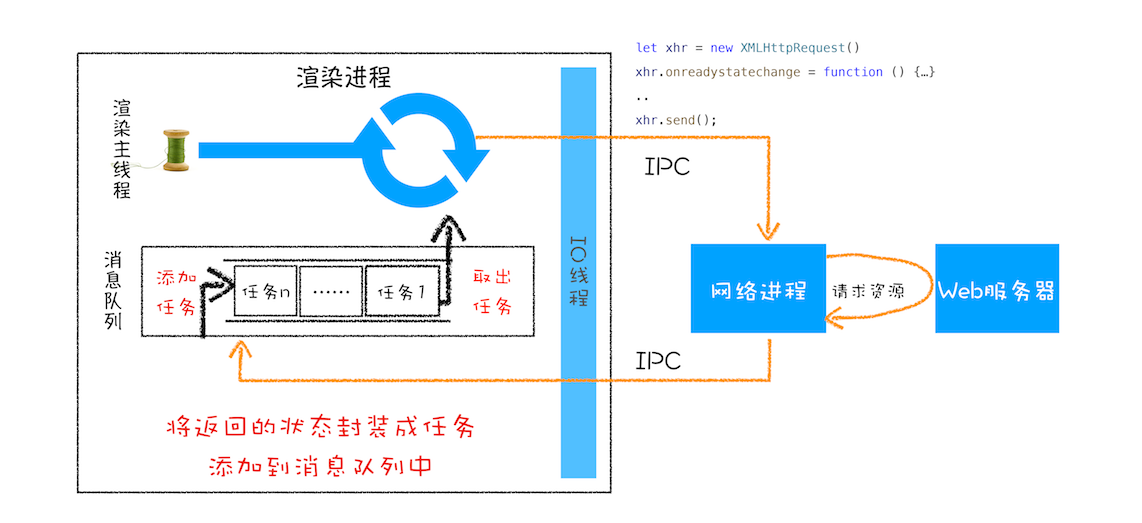
- 通过调用xhr.send发起网络请求
- 渲染进程会将请求发送给网络进程,然后网络进程负责资源的下载
- 等网络进程接收到数据以后,就会利用IPC来通知渲染进程
渲染进程接受到消息之后,会将xhr 的回调函数封装成任务并添加到消息队列中,等主线程循环系统执行到该任务的时候,就会根据相关的状态来调用对应的回调函数
跨域问题
- HTTPS 混合内容的问题
18 | 宏任务和微任务:不是所有任务都是一个待遇
宏任务
把这些消息队列中的任务称为宏任务
- 渲染事件(如解析 DOM、计算布局、绘制);
- 用户交互事件(如鼠标点击、滚动页面、放大缩小等);
- JavaScript 脚本执行事件;
- 网络请求完成、文件读写完成事件
事件循环机制流程(消息队列中宏任务的执行过程)
- 先从多个消息队列中选出一个最老的任务,这个任务称为 oldestTask;
- 然后循环系统记录任务开始执行的时间,并把这个 oldestTask 设置为当前正在执行的任务;
- 当任务执行完成之后,删除当前正在执行的任务,并从对应的消息队列中删除掉这个 oldestTask;
- 最后统计执行完成的时长等信息。
宏任务的问题
宏任务的时间粒度比较大,执行的时间间隔是不能准确控制的,对于一些高实时性的需求就不太符合了
<!DOCTYPE html><html><body><div id='demo'><ol><li>test</li></ol></div></body><script type="text/javascript">function timerCallback2(){console.log(2)}function timerCallback1(){console.log(1)setTimeout(timerCallback2,0)}setTimeout(timerCallback1,0)</script></html>
如下两个嵌套的setTimeout任务,因为setTimeout是宏任务,所以在两个宏任务之间和可能会插入一些系统级别的其他任务,会导致第二个setTimeout晚于预期执行
微任务**
异步回调
- 第一种是把异步回调函数封装成一个宏任务,添加到消息队列尾部,当循环系统执行到该任务的时候执行回调函数,如setTimeout(这个不是延迟队列么?) 和XMLHttpRequest的回调函数
- 第二种方式的执行时机是在主函数执行结束之后、当前宏任务结束之前执行回调函数,这通常都是以微任务形式体现的
微任务就是一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前
微任务产生的时机
- 使用MutationObserver监控某个DOM节点
- 使用Promise,调用Promise.resolve() 和Promise.then()
执行微任务队列的时机**
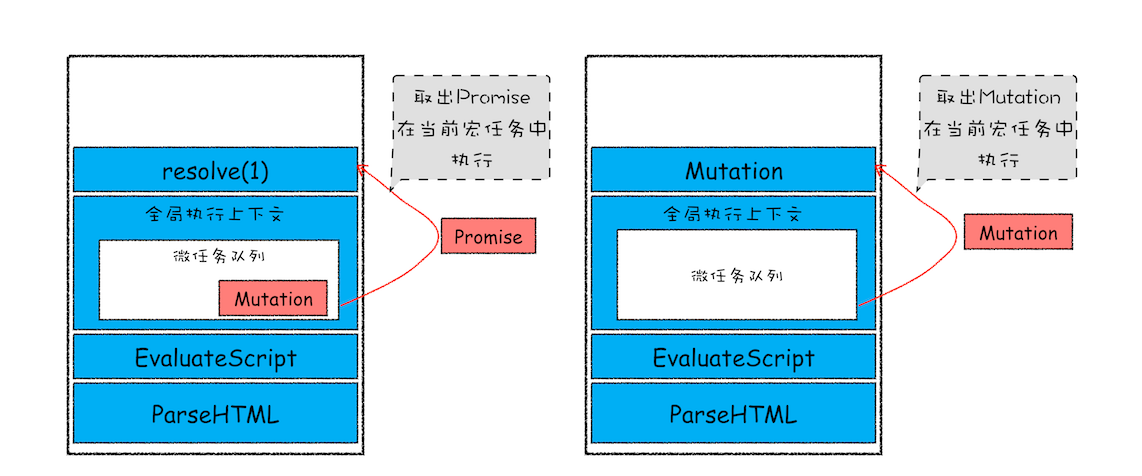
- 当前宏任务中的JS块执行完成时,也就是JS引擎准备退出全局执行上下文并清空调用栈时,JS引擎会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务
- 如果在执行微任务的过程中,产生了新的微任务,同样会将该微任务添加到微任务队列中,V8引擎会一直循环执行微任务队列中的任务,直到队列为空才算结束
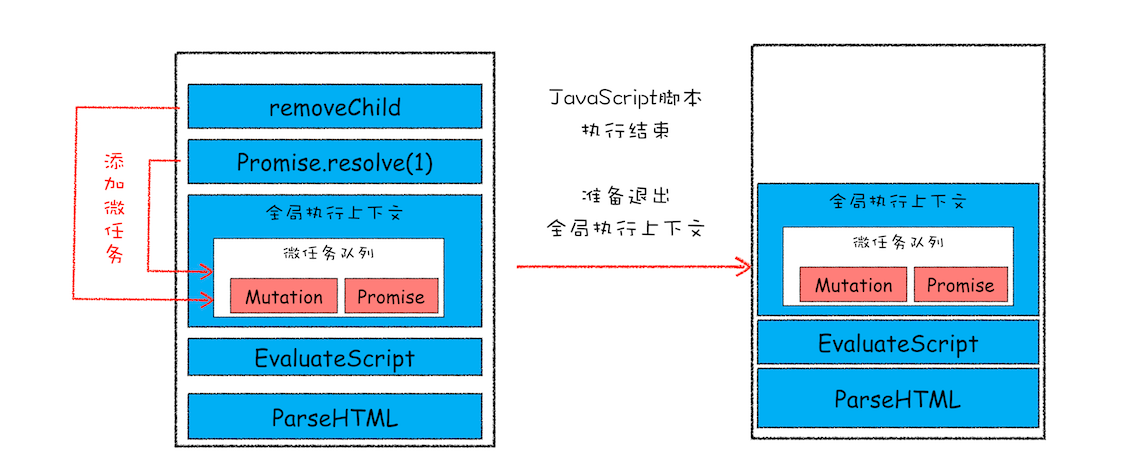
- 在执行一个 ParseHTML 的宏任务,在执行过程中,遇到了 JavaScript 脚本,那么就暂停解析流程,进入到 JavaScript 的执行环境
- 在 JavaScript 脚本的后续执行过程中,分别通过 Promise 和 removeChild 创建了两个微任务,并被添加到微任务列表中
- 接着 JavaScript 执行结束,准备退出全局执行上下文,这时候就到了检查点了,JavaScript 引擎会检查微任务列表,发现微任务列表中有微任务,那么接下来,依次执行这两个微任务
- 等微任务队列清空之后,就退出全局执行上下文。
结论
- 微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列
- 微任务的执行时长会影响到当前宏任务的时长
- 在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况下,微任务都早于宏任务执行
监听 DOM 变化方法演变
- 轮询检测:使用 setTimeout 或者 setInterval 来定时检测 DOM 是否有改变
- 如果时间间隔设置过长,DOM 变化响应不够及时;
- 反过来如果时间间隔设置过短,又会浪费很多无用的工作量去检查 DOM,会让页面变得低效
- Mutation Event:采用了观察者的设计模式,当 DOM 有变动时就会立刻触发相应的事件,这种方式属于同步回调
- 同步调用,会导致页面性能问题
Mutation Observe:监视 DOM 的变化,包括属性的变化、节点的增减、内容的变化等
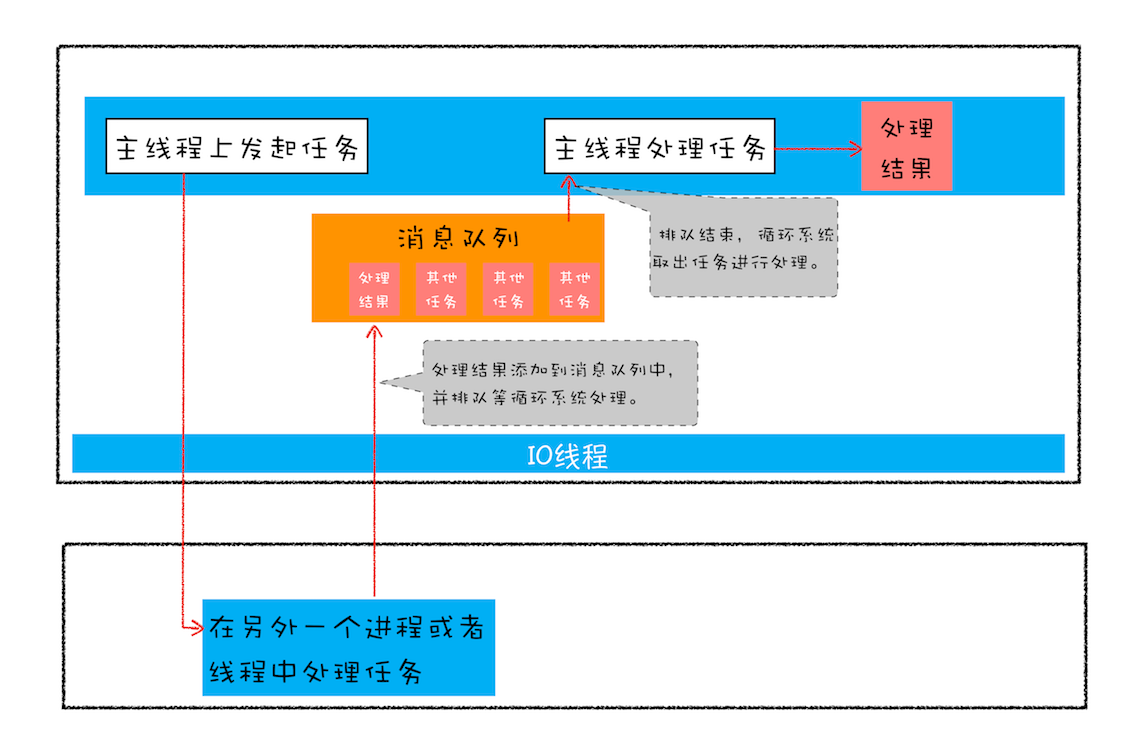
页面主线程发起了一个耗时的任务,并将任务交给另外一个进程去处理,这时页面主线程会继续执行消息队列中的任务
- 等该进程处理完这个任务后,会将该任务添加到渲染进程的消息队列中,并排队等待循环系统的处理。
- 排队结束之后,循环系统会取出消息队列中的任务进行处理,并触发相关的回调操作
版本1
// 执行状态function onResolve(resolve){console.log(resolve);}function onReject(error){console.log(error);}let xhr = new XMLHttpRequest()xhr.ontimeout = function(e){onReject(e)}xhr.onerror = function(e){onReject(e)}xhr.onreadystatechange = function(){onResolve(xhr.response)}// 设置请求类型 请求URL 是否同步信息let URL = 'https://time.geekbang.com'xhr.open('GET', URL, true)// 设置参数xhr.timeout = 3000xhr.responseType = 'text'xhr.setRequestHeader('X_TEST', 'time.geekbang')// 发起请求xhr.send();
问题: 代码的逻辑不连贯、不线性
版本2 封装异步代码,让处理流程变得线性
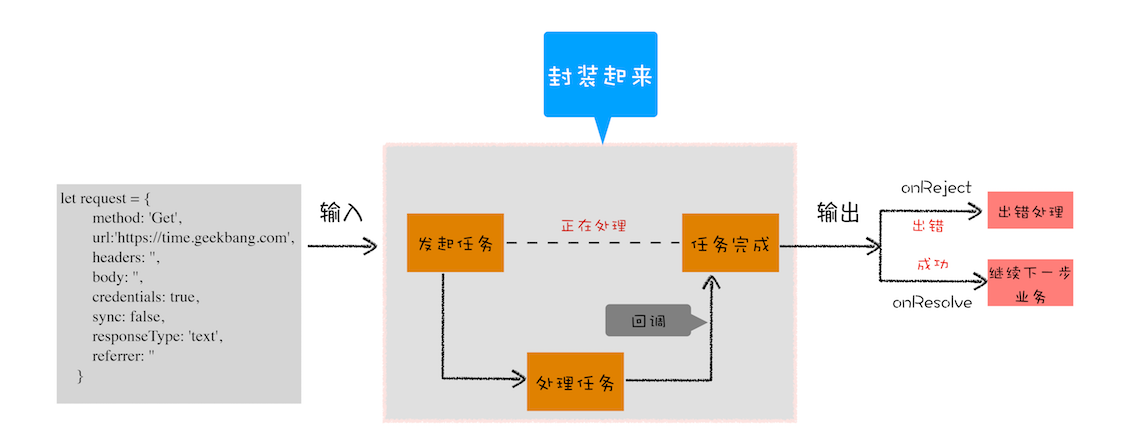
//makeRequest用来构造request对象function makeRequest(request_url){let request = {method: 'GET',url: request_ur;,headers: '',body: '',credentials: false,sync: true,responseType: 'text',referrer: ''}return request}//[in] request,请求信息,请求头,延时值,返回类型等//[out] resolve, 执行成功,回调该函数//[out] reject 执行失败,回调该函数function XFetch(request, resolve, reject){let xhr = new XMLHttpRequest()xhr.onerror = function(e){reject(e)}xhr.ontimeout = function(e){reject(e)}xhr.onreadystatechange = function(){if(xhr.status === 200){resolve(xhr.responose)}}xhr.open(request.method, request.url, request.sync);xhr.timeout = request.timeout;xhr.responseType = request.responseType;// ...xhr.send();}// 使用XFetch(makeRequest('https://time.geekbang.org'),funciton resolve(data){console.log(data);},function reject(e){console.log(e);})
问题:回调地狱
- 嵌套调用 ==> 消灭嵌套调用
- 任务的不确定性 ==> 合并多个任务的错误处理
XFetch(makeRequest('https://time.geekbang.org/?category'),function resolve(response) {console.log(response)XFetch(makeRequest('https://time.geekbang.org/column'),function resolve(response) {console.log(response)XFetch(makeRequest('https://time.geekbang.org')function resolve(response) {console.log(response)}, function reject(e) {console.log(e)})}, function reject(e) {console.log(e)})}, function reject(e) {console.log(e)})
版本3 Promise:消灭嵌套调用和多次错误处理
```javascript function XFetch(request){ function executor(resolve, reject){
xhr.open(‘GET’, request.url, true); xhr.ontimeout = function(e){reject(e)} xhr.onerror = function(e){reject(e)} xhr.onreadystatechange = function(){let xhr = new XMLHttpRequest()
} xhr.send() } return new Promise(executor) }if(this.readyState === 4){if(this.status === 200){resolve(this.responseText, this)}else{let error = {code: this.status,response: this.response}reject(error, this)}}
var x1 = XFetch(makeRequest(‘https://time.geekbang.org/?category‘)) var x2 = x1.then(value=>{ console.log(value); return XFetch(makeRequest(‘https://time.geekbang.org/?category‘)) }) var x3 = x2.then(value=>{ console.log(value); return XFetch(makeRequest(‘https://time.geekbang.org/?category‘)) }) x3.catch(error=>{ console.log(error); })
- 首先我们引入了 Promise,在调用 XFetch 时,会返回一个 Promise 对象。- 构建 Promise 对象时,需要传入一个 executor 函数,XFetch 的主要业务流程都在 executor 函数中执行- 如果运行在 excutor 函数中的业务执行成功了,会调用 resolve 函数;如果执行失败了,则调用 reject 函数。- 在 excutor 函数中调用 resolve 函数时,会触发 promise.then 设置的回调函数;而调用 reject 函数时,会触发 promise.catch 设置的回调函数<br /><a name="G7su3"></a>### Promise是如何解决嵌套回调的- **Promise 实现了回调函数的延时绑定**创建好 Promise 对象 x1 之后,再使用 x1.then 来设置回调函数```javascript//创建Promise对象x1,并在executor函数中执行业务逻辑function executor(resolve, reject){resolve(100)}let x1 = new Promise(executor)//x1延迟绑定回调函数onResolvefunction onResolve(value){console.log(value)}x1.then(onResolve)
- 需要将回调函数 onResolve 的返回值穿透到最外层

- Promise对象的错误可以”冒泡“到最外层,将多个Promise对象的错误统一处理
Promise 与微任务
// Bromise构造函数function Bromise(executor){var onResolve_ = null;var onReject_ = null;this.then = function(onResolve, onReject){onResolve_ = onResolve};function resolve(value){// onResolve_(value) // onResolve_ is not a function 回调函数延迟绑定setTimeout(()=>{ // 使用定时器来模拟,实际Promise内部使用的是微任务onResolve_(value)},0)}executor(resolve, null);}function executor(resolve, reject){resolve(100)}let demo = new Bromise(executor)function onResolve(value){console.log(value);}demo.then(onResolve) // 绑定回调函数(在Promise实际是延迟绑定的)
思考时间
- Promise 中为什么要引入微任务?
由于promise采用.then延时绑定回调机制,而new Promise时又需要直接执行promise中的方法,即发生了先执行方法后添加回调的过程,此时需等待then方法绑定两个回调后才能继续执行方法回调,便可将回调添加到当前js调用栈中执行结束后的任务队列中,由于宏任务较多容易堵塞,则采用了微任务
- Promise 中是如何实现回调函数返回值穿透的?
首先Promise的执行结果保存在promise的data变量中,然后是.then方法返回值为使用resolved或rejected回调方法新建的一个promise对象,即例如成功则返回new Promise(resolved),将前一个promise的data值赋给新建的promise
- Promise 出错后,是怎么通过“冒泡”传递给最后那个捕获异常的函数?
promise内部有resolved和rejected变量保存成功和失败的回调,进入.then(resolved,rejected)时会判断rejected参数是否为函数,若是函数,错误时使用rejected处理错误;若不是,则错误时直接throw错误,一直传递到最后的捕获,若最后没有被捕获,则会报错。可通过监听unhandledrejection事件捕获未处理的promise错误
20 | async/await:使用同步的方式去写异步代码
生成器 VS 协程
生成器函数是一个带星号函数,而且是可以暂停执行和恢复执行的
function* genDemo() {console.log("开始执行第一段")yield 'generator 2'console.log("开始执行第二段")yield 'generator 2'console.log("开始执行第三段")yield 'generator 2'console.log("执行结束")return 'generator 2'}console.log('main 0')let gen = genDemo()console.log(gen.next().value)console.log('main 1')console.log(gen.next().value)console.log('main 2')console.log(gen.next().value)console.log('main 3')console.log(gen.next().value)console.log('main 4')

若有收获,就点个赞吧
0 人点赞
