12 | 栈空间和堆空间:数据是如何存储的?
JavaScript 是什么类型的语言
动态:声明了变量以后,可以动态的修改变量存储值得数据类型 弱类型:有隐式类型转换:不需要告诉JS引擎变量存储的数据类型,JS在运行代码的时候自己可以推断出来
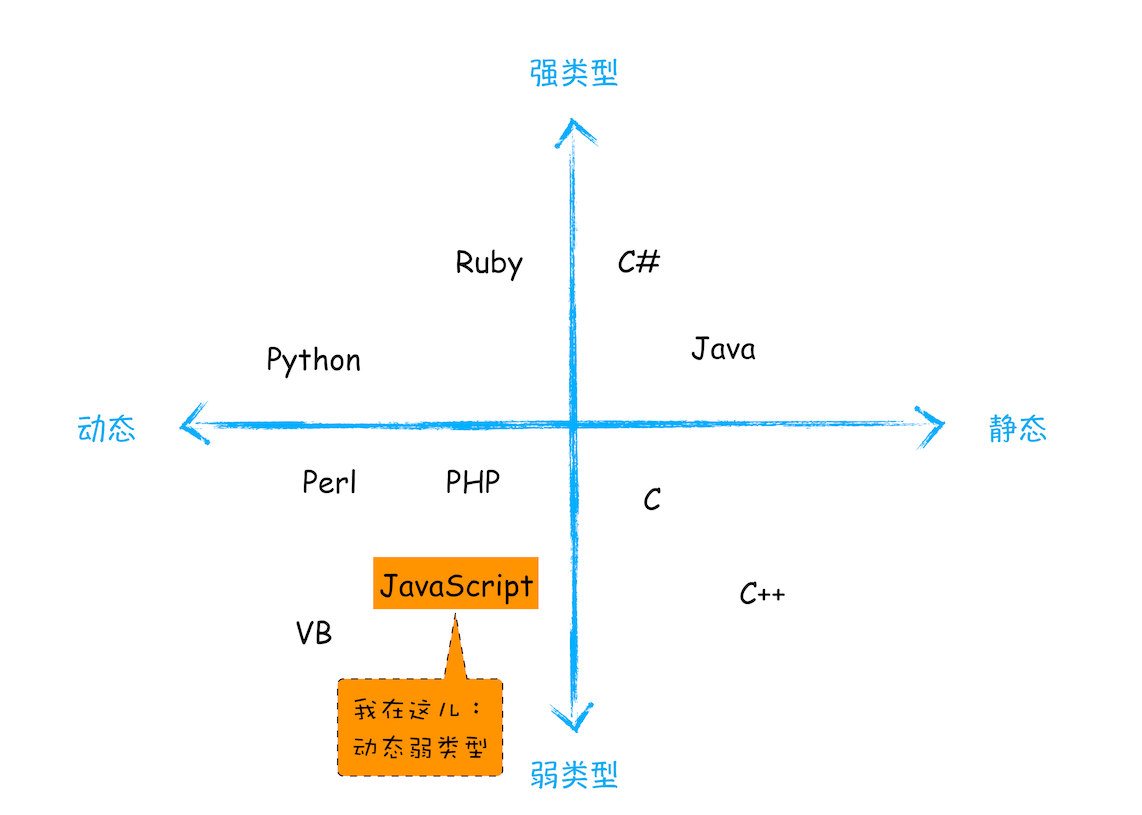
JavaScript 的数据类型

内存空间

代码空间
-
栈空间和堆空间:
原始数据类型都是保存在”栈”中的,引用类型都是保存在”堆”中的
function foo(){var a = "极客时间"var b = avar c = {name:"极客时间"}var d = c}foo()
- 初始调用栈
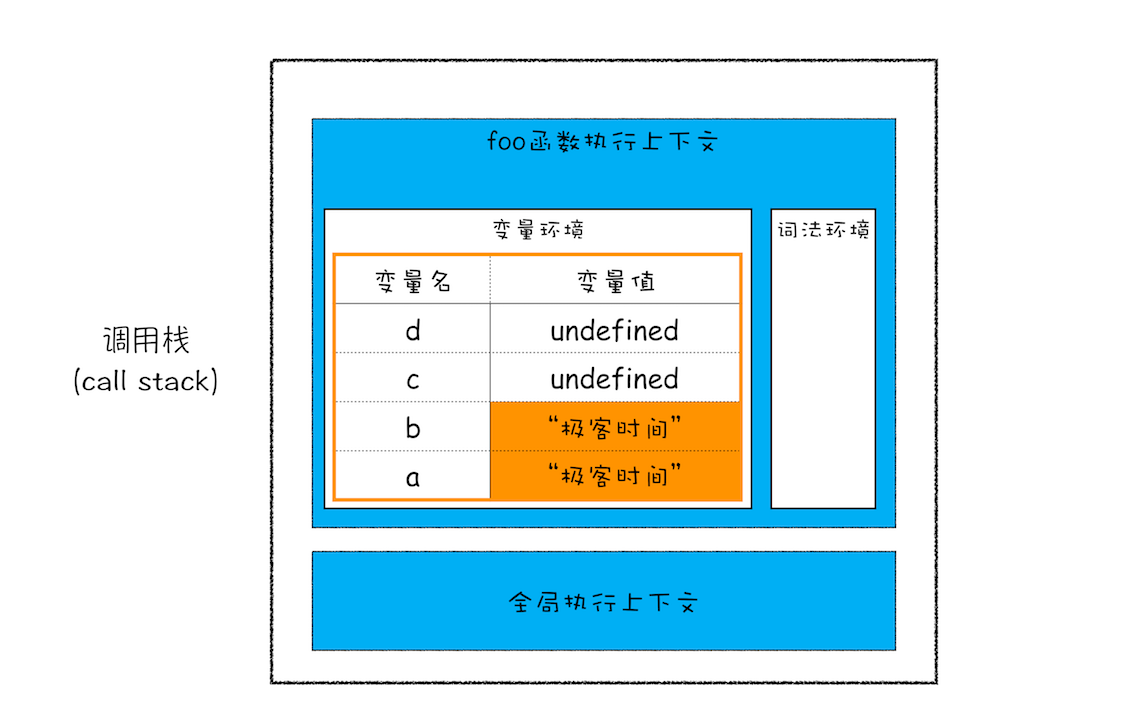
- 执行到第四行,为引用数据类型声明、赋值
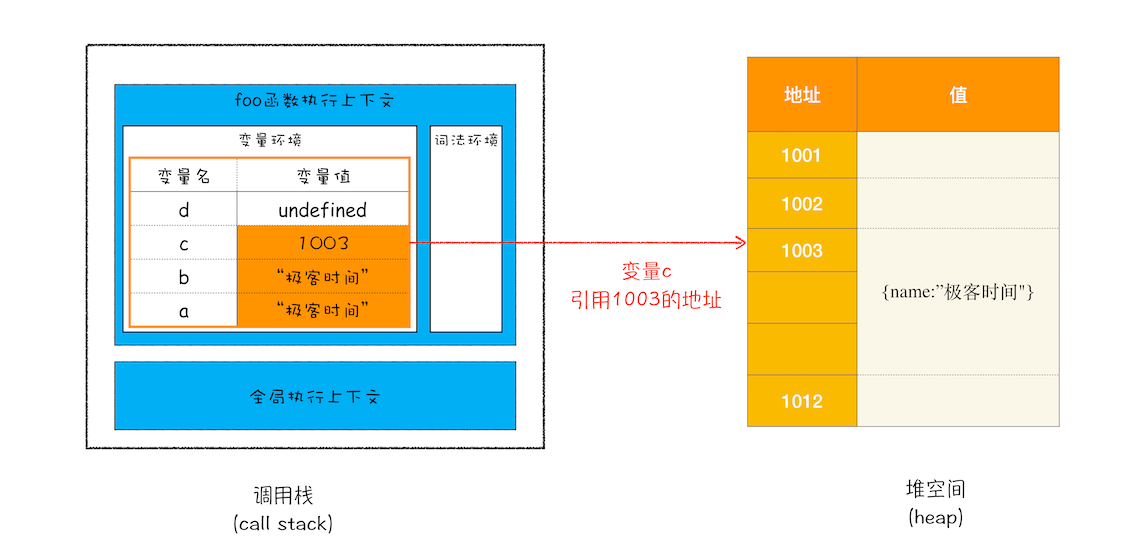
- 执行到第五行,赋值(原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址)
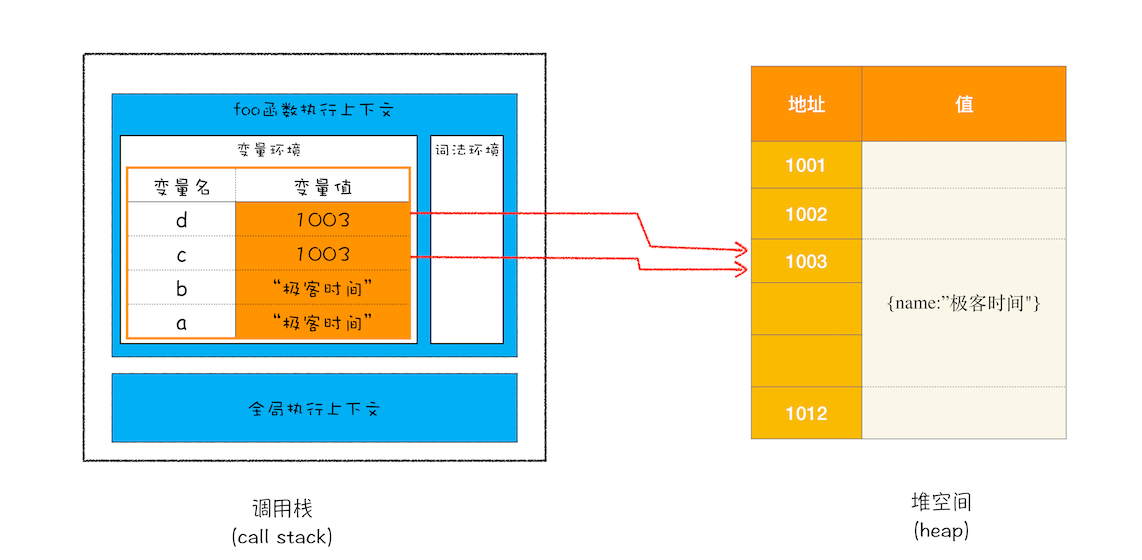
为何区分栈空间和堆空间?
通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间
JS引擎需要只用栈类维护程序执行期间的上下文状态,如果栈空间大了的话,所有的数据都存放到栈空间,会影响到上下文的切换效率,进而影响整个程序的执行效率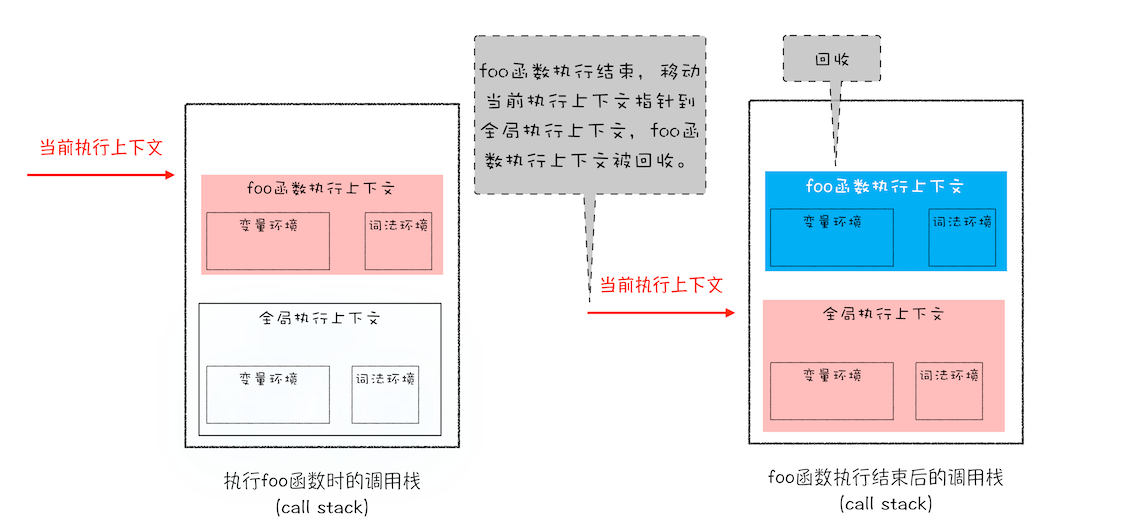
比如文中的 foo 函数执行结束了,JavaScript 引擎需要离开当前的执行上下文,只需要将指针下移到上个执行上下文的地址就可以了,foo 函数执行上下文栈区空间全部回收
再谈闭包
function foo() {var myName = "极客时间"let test1 = 1const test2 = 2var innerBar = {setName:function(newName){myName = newName},getName:function(){console.log(test1)return myName}}return innerBar}var bar = foo()bar.setName("极客邦")bar.getName()console.log(bar.getName())
执行流程
- 当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文。
- 在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建换一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量。
- 接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了。
- 由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。
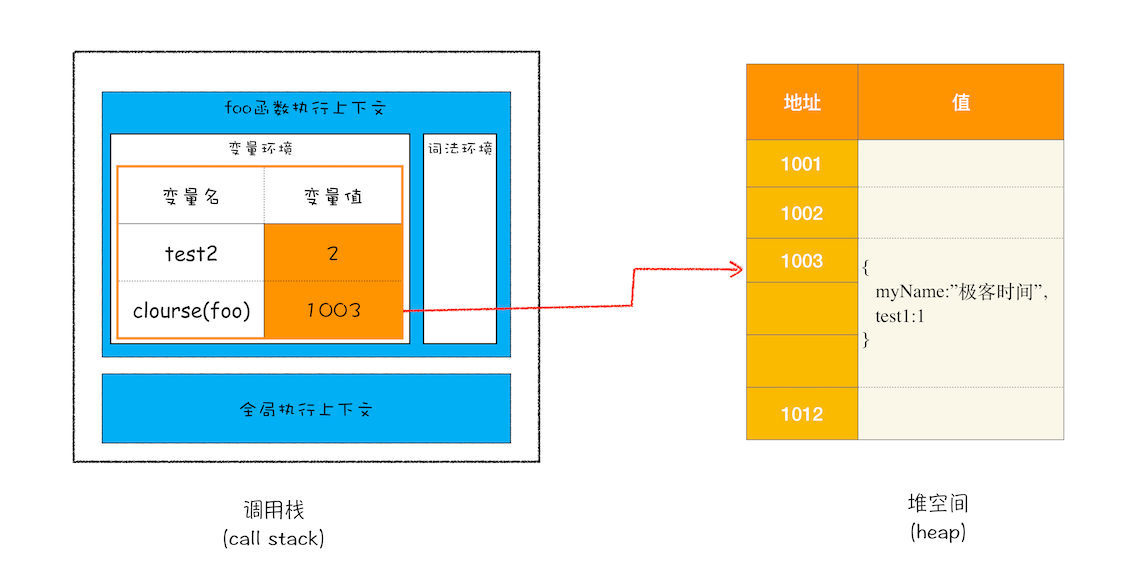
产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。
对应的深拷贝
let jack = {name : "jack.ma",age:40,like:{dog:{color:'black',age:3,},cat:{color:'white',age:2}}}function copy(src){let dest//实现拷贝代码,将src的值完整地拷贝给dest//在这里实现return dest}let jack2 = copy(jack)//比如修改jack2中的内容,不会影响到jack中的值jack2.like.dog.color = 'green'console.log(jack.like.dog.color) //打印出来的应该是 "black"
- JSON.parse(JSON.stringify(obj)) : 无法拷贝函数
- Object.assign({}, source) : 只能拷贝一层
- 递归遍历对象
function copy(src){//实现拷贝代码,将src的值完整地拷贝给destif(typeof src === 'object'){if(!src) return src;var obj = src.constructor();for(var key in src){obj[key] = copy(src[key])}return objl}else{return src;}}
13 | 垃圾回收:垃圾数据是如何自动回收的?
不同语言的垃圾回收策略
手动回收:C/C++
自动回收: JavaScript、Java、Python, 产生的垃圾由垃圾回收器释放
调用栈中的数据是如何回收的
function foo(){var a = 1var b = {name:"极客邦"}function showName(){var c = 2var d = {name:"极客时间"}}showName()}foo()
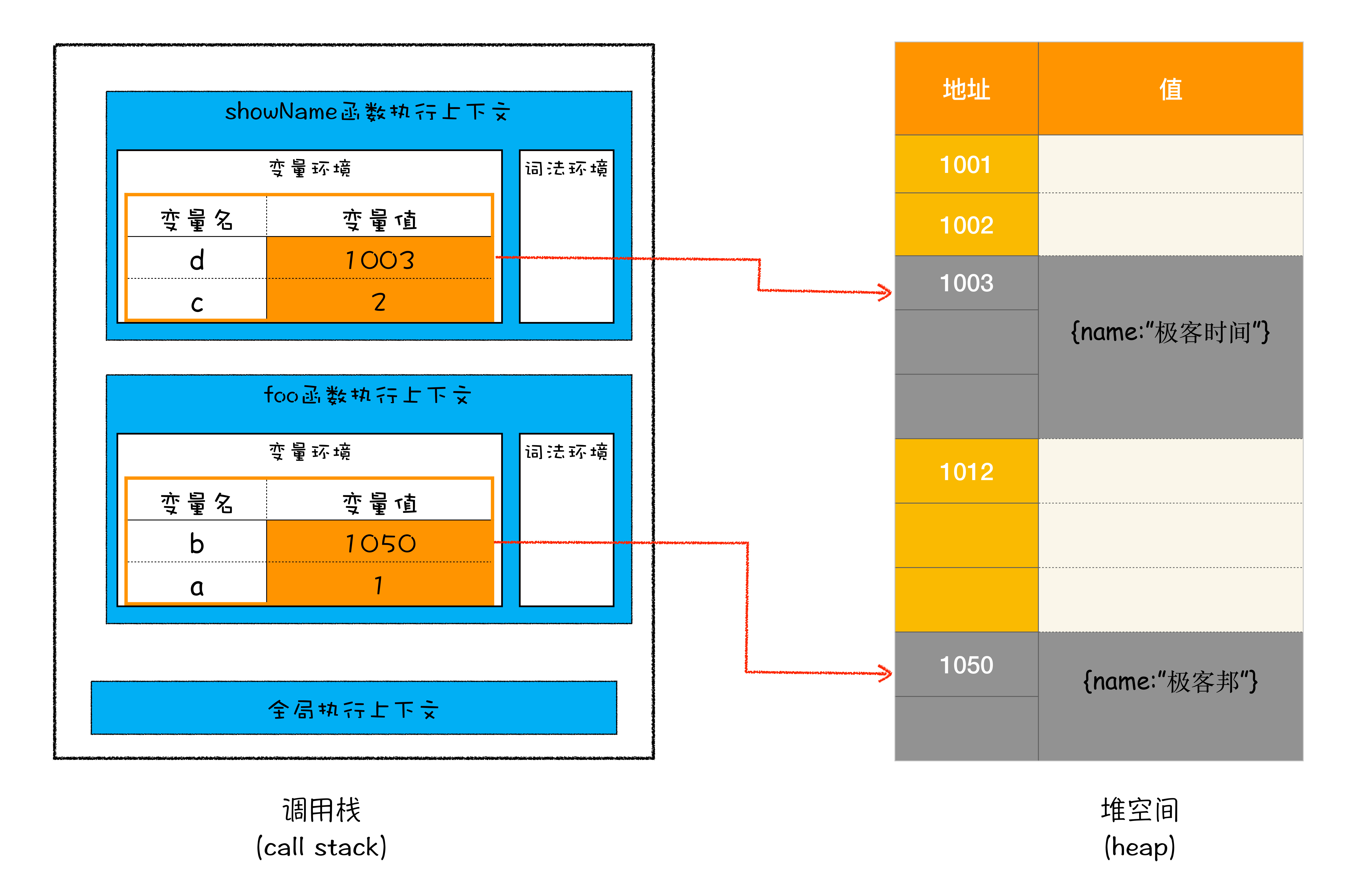
JS引擎会通过下移ESP(记录当前执行状态的指针(称为 ESP extended stack pointer))指针来销毁该函数保存在栈中的执行上下文
堆中的数据是如何回收的
当showName函数和foo函数执行完毕后,ESP指针指向全局执行上下文,栈中的内存已经清理完,但堆中内存占用依然存在,需要使用垃圾回收器处理
代际假说和分代收集
代际假说(The Generational Hypothesis)
- 第一个是大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问;
-
分代收集
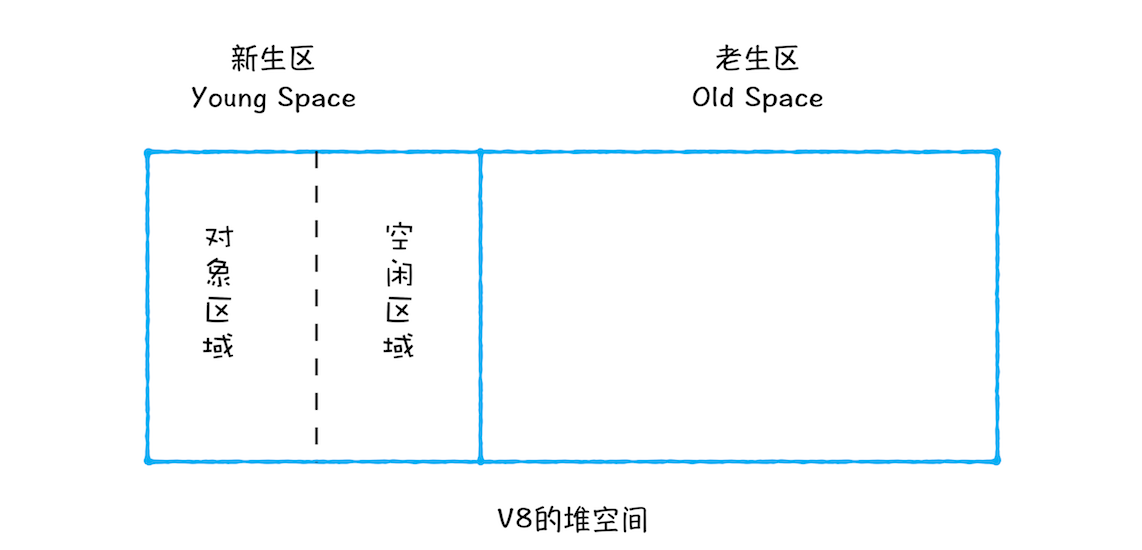
V8中会把堆分为新生代和老生代两个区域
新生代:生存时间短的对象,1-8M的容量 ===> 副垃圾回收器
- 老生代:生存时间久的对象 ===> 主垃圾回收器
垃圾回收器的工作流程
- 标记:标记空间中活动的对象和非活动的对象
- 清除:回收非活动对象所占据的内存空间
- 内存整理:垃圾回收后会导致不连续的内存空间(内存碎片),整理内存碎片以便更大内存分配需求
副垃圾回收器
- 主要负责新生区的垃圾回收,新生区存放小对象,区域不大,但是垃圾回收比较频繁
- 采用 Scavenge算法
- 1、将新生区划分为对象区域和空闲区域两部分
- 2、新加入的对象存放到对象区域,当对象区域被写满后,要执行一次垃圾清理操作
- 3、垃圾回收过程中,会标记存活对象,当标记完成之后,就会进入垃圾清理的阶段,副垃圾回收器会把这些存活的对象复制到空闲区域,同时将这些对象有序的排列起来(相当于内存整理,复制后空闲区域没有内存碎片了)
- 4、复制完成之后,对象区域和空闲区域进行角色转换,这样就完成了垃圾回收的操作
- 5、由于每次垃圾清理的过程都涉及到对象区域复制存活对象到空闲区域的过程,所以为了执行效率,一般新生区的空间会被设置的比较小
- 6、对象晋升策略:因为新生区空间较小,所以很容易被对象装满,所以经过两次垃圾回收依然存活的对象会被移动到老生区
主垃圾回收器
- 负责老生区的垃圾回收(老生区对象占用空间大,对象存活时间长)
- 采用标记-清除(Mark-Sweep)算法
- 1、标记过程:从一组根元素开始,遍历这组根元素,能够到达的称为活动对象,不能到达的可以判断为垃圾数据
- 2、清理过程:清除上一步标记为垃圾数据的过程
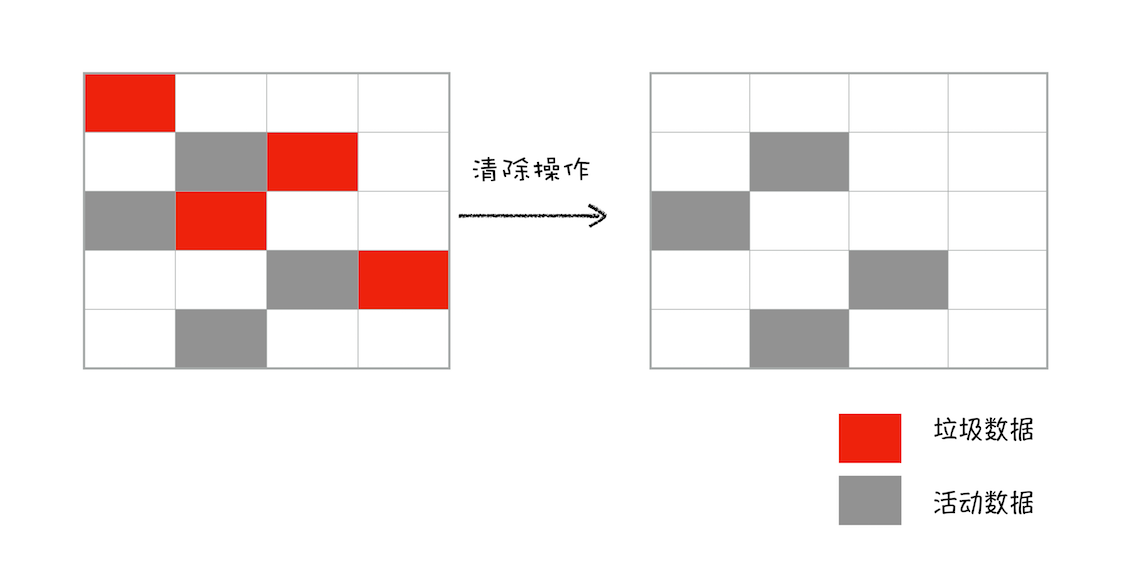
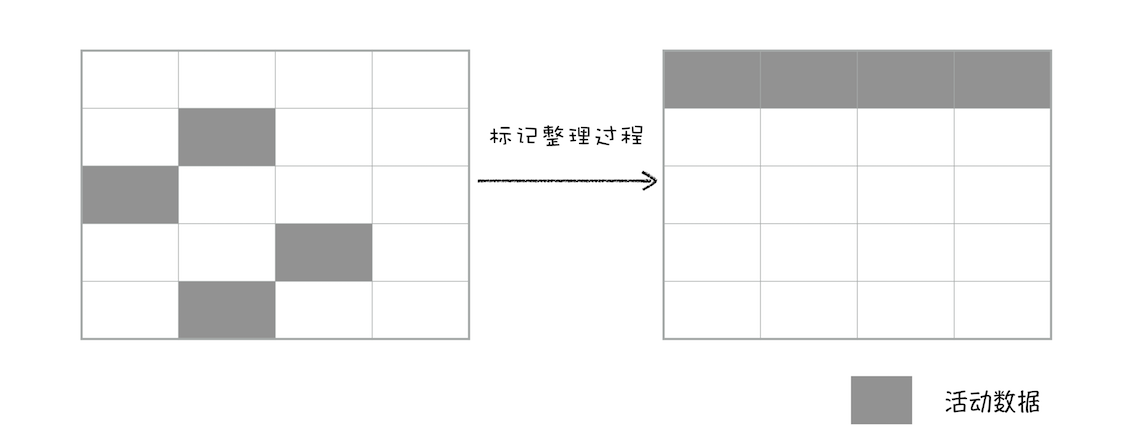
- 3、标记-整理(Mark-Compact)法:对标记清除法造成的垃圾碎片进行整理,将所有的存活对象都向一端移动,然后直接清理掉边界以外的内存
全停顿
JS是执行在主线程之上的,一旦开始垃圾回收算法,都需要将正在执行的JS脚本暂停下来,待垃圾回收完毕后再恢复脚本执行,我们把这种行为成为全停顿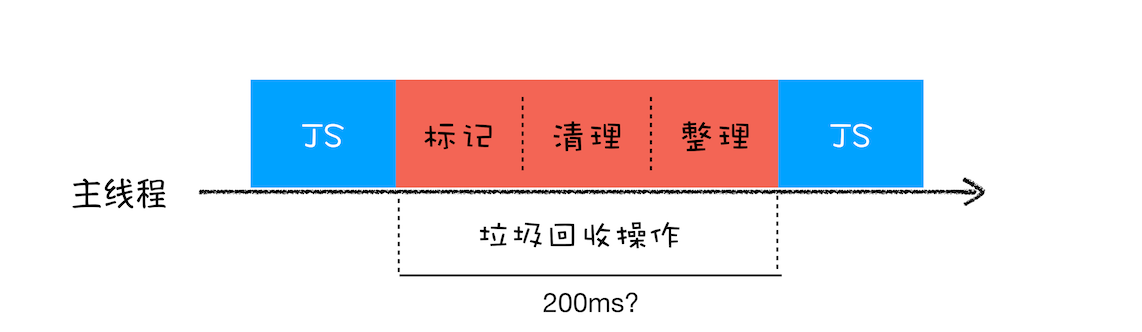
增量标记(Incremental Marking)算法
把一个完整的垃圾回收拆分为很多小的任务,这些小的任务执行时间较短,可以穿插在其他的JS任务中间执行,同时让垃圾回收和JS逻辑交替进行,就不会因为垃圾回收导致页面的卡顿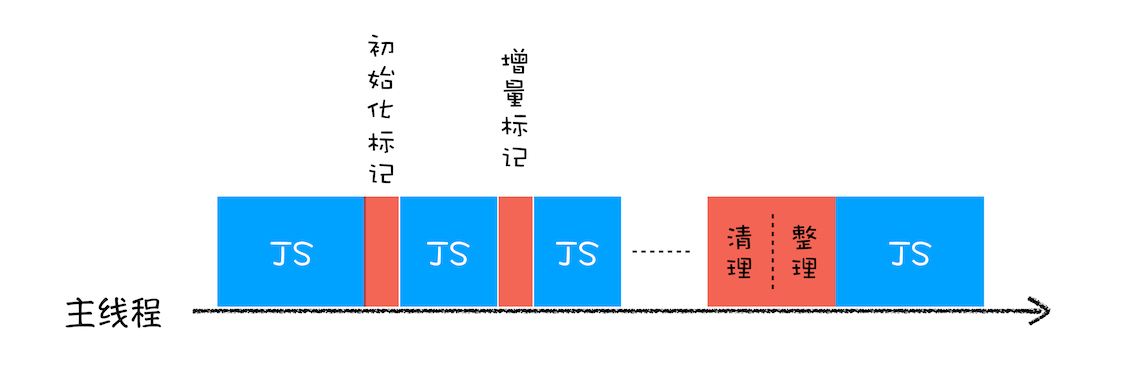
思考时间
如何判断 JavaScript 中内存泄漏?
https://segmentfault.com/a/1190000038816646
概念:
代码执行时需要内存中的一块存储空间,执行之后已经不再需要这段数据了,但是又没有销毁数据占用的内存,将这种行为称为内存泄漏
如何观察内存泄漏:
- Chrome Performance
- 感官页面卡顿
如何避免:
- 不使用的变量重置为null
- 少使用闭包,用的话用局部函数闭包
14 | 编译器和解释器:V8是如何执行一段JavaScript代码的?
编译器和解释器
编译型语言:
在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了,C/C++、GO 等都是编译型语言
解释型语言:
解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 Python、JavaScript 等都属于解释型语言
编译器和解释器是如何“翻译”代码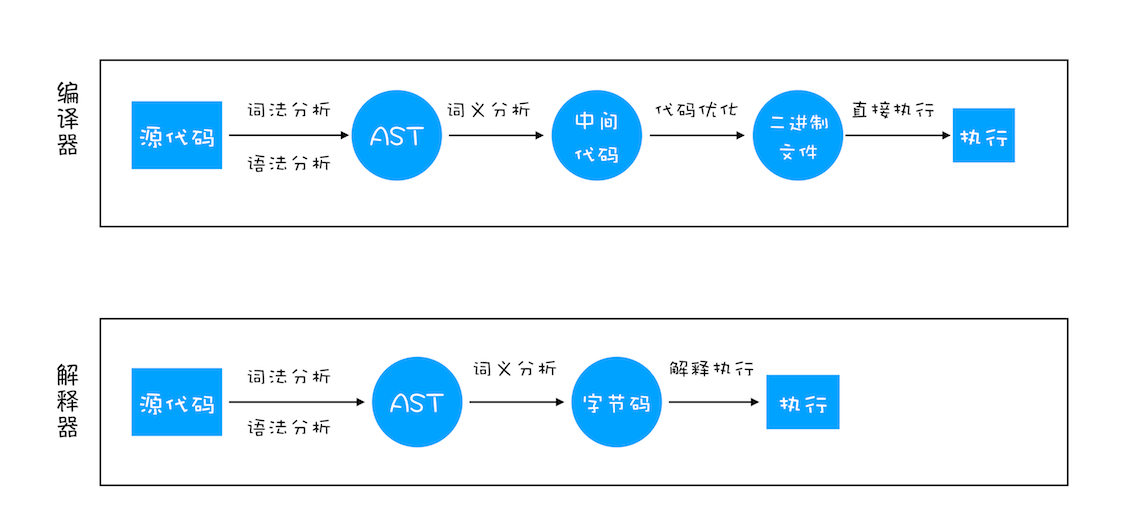
1、在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后是优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功。
2、在解释型语言的解释过程中,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果。
V8 是如何执行一段 JavaScript 代码的
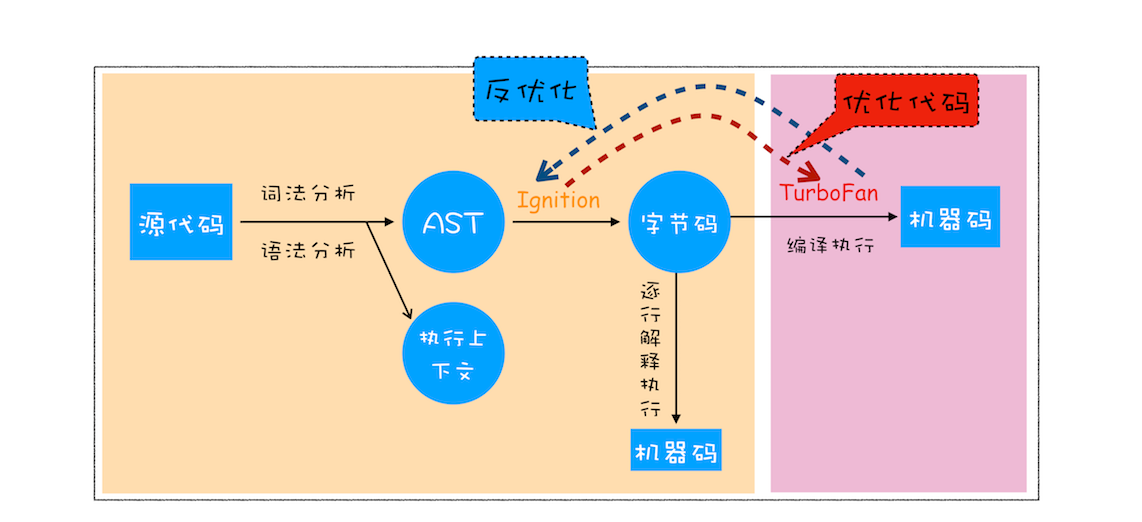
- 生成抽象语法树(AST)和执行上下文
- AST:抽象语法树,代码的结构化表示
- babel: 被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码
ES6 源代码 —> ES6 AST —> ES5 AST —> JS 源代码(ES5源代码) - ESLint: ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。
- babel: 被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码
- AST生成阶段:
- 分词tokenize(词法分析)将源代码拆分为不可再拆的一个个token(不可再拆分的单个字符或者字符串)
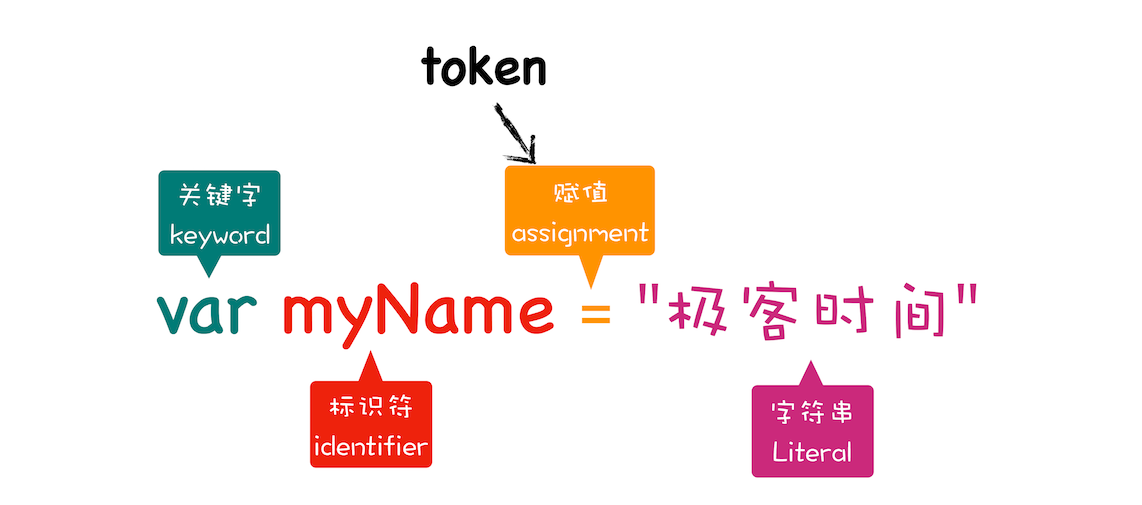
- 解析(语法分析)将上一步拆分的token,根据语法规则,生成AST
- 分词tokenize(词法分析)将源代码拆分为不可再拆的一个个token(不可再拆分的单个字符或者字符串)
- AST:抽象语法树,代码的结构化表示
- 生成字节码
- 有了AST 和执行上下文后,解释器(Ignition)根据AST生成字节码,并解释执行字节码
- 之前Chrome的架构下没有字节码,直接用编译器根据AST生成机器码,但机器码占用内存过大,所以引入了”字节码“
- 字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行
- 字节码占用的空间远远低于机器码,所以字节码可以减少系统内存占用

- 执行代码
- 如果有一段字节码第一次执行,会被解释器(Ignition)逐条解释执行
- 如果解释器在解释字节码的过程中,发现一段代码被重复多次执行(热点代码),后台的编译器(TurboFan)就会把热点代码编译为高效的机器码
- 当再次执行这段被优化的代码时,只需要执行被编译的机器码即可,将极大的提升执行效率
即时编译(JIT Just In Time)
指解释器 Ignition 在解释执行字节码的同时,收集代码信息,当它发现某一部分代码变热了之后,TurboFan 编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用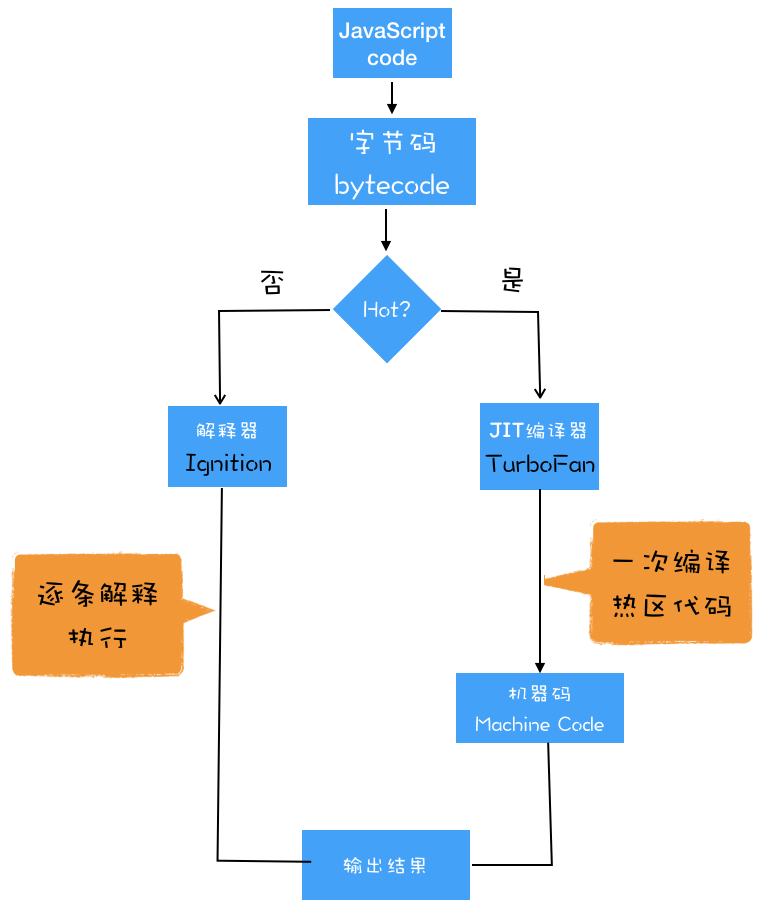
JavaScript 的性能优化
1、提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,这样可以使得页面快速响应交互;2、避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;
3、减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存。

若有收获,就点个赞吧
0 人点赞
