- VOC数据集
- 数据集构建
- -- encoding: utf-8 --
- -- encoding: utf-8 --
- here put the import lib
- 根据label结合colormap得到原始颜色数据 用于最后转换
- voc数据集class对应的color 官方所给颜色
- 得到混淆矩阵
- 计算图像分割衡量系数
- -- encoding: utf-8 --
- here put the import lib
- ————————- 超参数设定 ———————————
- —————————— 生成csv —————————
- ——————————————————————-
- net = FCN8x(NUM_CLASSES)
- 构建网络
- 训练验证
VOC数据集
详细数据集介绍请点击. 官网
数据集下载快速链接请点击 数据镜像 (建议配合迅雷)
数据集构建
目标:构建Pytorch 可直接使用的数据集
- 读取图片文件夹的图片名称,结合路径写入csv,提出太小的图片,分割训练集,验证集,测试集
- 对原图进行裁切,标准化等操作
- label 要根据数据集标签的颜色转换为21类标记像素图片,和原图裁切为同样大小(重难点)
```./utils/data_txt.py-- encoding: utf-8 --
‘’’ @File : data_txt.py @Time : 2020/08/01 10:36:19 @Author : AngYi @Contact : angyi_jq@163.com @Department : QDKD shuli @description: 把图片数据从文件夹整理成csv文件,每一行代表其路径 ‘’’ import numpy as np import pandas as pd import os import PIL from PIL import Image
class image2csv(object):
# 分割训练集 验证集 测试集# 做成对应的csvdef __init__(self,data_root,image_dir,label_dir,slice_data,width_input,height_input):self.data_root = data_rootself.image_dir = image_dirself.label_dir = label_dirself.slice_train = slice_data[0]self.slice_val = slice_data[1]self.width = width_inputself.height = height_inputdef read_path(self):images = []labels = []for i,im in enumerate(os.listdir(self.image_dir)):label_name = im.split('.')[0] + '.png' # 读取图片的名字,去label里面找,确保两个文件夹都有这个名字的图if os.path.exists(os.path.join(self.label_dir,label_name)):size_w,size_h = Image.open(os.path.join(self.image_dir,im)).sizesize_lw,size_lh = Image.open(os.path.join(self.label_dir,label_name)).sizeif min(size_w,size_lw) > self.width and min(size_h,size_lh)> self.height:images.append(os.path.join(self.image_dir,im))labels.append(os.path.join(self.label_dir,label_name))else:continueassert(len(images)==len(labels)) #确保长度相等self.data_length = len(images) # 真正两个文件夹都有的图片的长度data_path = {'image':images,'label':labels,}return data_pathdef generate_csv(self):data_path = self.read_path() # 存放了路径data_path_pd = pd.DataFrame(data_path)train_slice_point = int(self.slice_train*self.data_length) # 0.7*lenvalidation_slice_point = int((self.slice_train+self.slice_val)*self.data_length) # 0.8*lentrain_csv = data_path_pd.iloc[:train_slice_point,:]validation_csv = data_path_pd.iloc[train_slice_point:validation_slice_point,:]test_csv = data_path_pd.iloc[validation_slice_point:,:]train_csv.to_csv(os.path.join(self.data_root,'train.csv'),header=None,index=None)validation_csv.to_csv(os.path.join(self.data_root,'val.csv'),header = None,index = None)test_csv.to_csv(os.path.join(self.data_root,'test.csv'),header=False,index = False)
if name == “main“: DATA_ROOT = ‘./data/‘ image = os.path.join(DATA_ROOT,’JPEGImages’) label = os.path.join(DATA_ROOT,’SegmentationClass’) slice_data = [0.7,0.1,0.2] # 训练 验证 测试所占百分比 WIDTH = 256 HEIGHT = 256 tocsv = image2csv(DATA_ROOT,image,label,slice_data,WIDTH,HEIGHT) tocsv.generate_csv()
### `./utils/DataLoade.py`**这部分有很多细节部分要注意,比如不能直接resize 标签,因为resize会将0,1,2,3这些类别数字变成小数,没法达到标签的作用,**
-- encoding: utf-8 --
‘’’ @File : DataLoade.py @Time : 2020/08/01 10:58:51 @Author : AngYi @Contact : angyi_jq@163.com @Department : QDKD shuli @description : 创建Dataset类,处理图片,弄成Pythorch可以直接用的trainloader validloader testloader ‘’’
here put the import lib
import pandas as pd import numpy as np import os from torch.utils.data import Dataset, DataLoader import torchvision import torchvision.transforms as transforms from PIL import Image import random import torch random.seed(78)
class CustomDataset(Dataset): def init(self,datarootcsv,inputwidth,inputheight,test=False): super(CustomDataset, self).__init() # 在子类进行初始化时,也想继承父类的__init()就通过super()实现 self.data_root_csv = data_root_csv self.data_all = pd.read_csv(self.data_root_csv) self.image_list = list(self.data_all.iloc[:,0]) self.label_list = list(self.data_all.iloc[:,1]) self.width = input_width self.height = input_height
def __len__(self):return len(self.image_list)def __getitem__(self,index):img = Image.open(self.image_list[index]).convert('RGB')label = Image.open(self.label_list[index]).convert('RGB')img,label = self.train_transform(img,label,crop_size=(self.width,self.height))# assert(img.size == label.size)sreturn img,labeldef train_transform(self,image,label,crop_size=(256,256)):''':param image: PIL image:param label: PIL image:param crop_size: tuple'''image,label=RandomCrop(crop_size)(image,label) # 第一个括号是实例话对象,第二个是__call__方法tfs=transforms.Compose([transforms.ToTensor(),transforms.Normalize([.485, .456, .406], [.229, .224, .225])])image=tfs(image)label=image2label()(label)label=torch.from_numpy(label).long()return image,label
class RandomCrop(object): “”” Crop the given PIL Image at a random location. 自定义实现图像与label随机裁剪相同的位置 没办法直接使用transform.resize() 因为是像素级别的标注,而resize会将这些标注变成小数 “”” def init(self, size): self.size = size
@staticmethoddef get_params(img, output_size):w, h = img.sizeth, tw = output_sizeif w == tw and h == th:return 0, 0, h, wi = random.randint(0, h - th)j = random.randint(0, w - tw)return i, j, th, twdef __call__(self, img, label):i, j, h, w = self.get_params(img, self.size)return img.crop((j,i,j+w,i+h)),label.crop((j,i,j+w,i+h))
class image2label(): ‘’’ 现在的标签是每张图都是黑色背景,白色边框标记物体,那么要怎么区分飞机和鸟等21类物体,我们需要将标签 改为背景是[0,0,0],飞机是[1,1,1],自行车是[2,2,2]… voc classes = [‘background’,’aeroplane’,’bicycle’,’bird’,’boat’, ‘bottle’,’bus’,’car’,’cat’,’chair’,’cow’,’diningtable’, ‘dog’,’horse’,’motorbike’,’person’,’potted plant’, ‘sheep’,’sofa’,’train’,’tv/monitor’] ‘’’ def init(self,num_classes=21): classes = [‘background’,’aeroplane’,’bicycle’,’bird’,’boat’, ‘bottle’,’bus’,’car’,’cat’,’chair’,’cow’,’diningtable’, ‘dog’,’horse’,’motorbike’,’person’,’potted plant’, ‘sheep’,’sofa’,’train’,’tv/monitor’]
# 给每一类都来一种颜色colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],[64,128,0],[192,128,0],[64,0,128],[192,0,128],[64,128,128],[192,128,128],[0,64,0],[128,64,0],[0,192,0],[128,192,0],[0,64,128]]self.colormap=colormap[:num_classes]cm2lb=np.zeros(256**3) # 创建256^3 次方空数组,颜色的所有组合for i,cm in enumerate(self.colormap):cm2lb[(cm[0]*256+cm[1])*256+cm[2]]=i# 符合这种组合的标记这一类# 相当于创建了一个类别的颜色条,这里比较难理解self.cm2lb=cm2lbdef __call__(self, image):''':param image: PIL image:return:'''image=np.array(image,dtype=np.int64)idx=(image[:,:,0]*256+image[:,:,1])*256+image[:,:,2]label=np.array(self.cm2lb[idx],dtype=np.int64) # 根据颜色条找到这个label的标号return label
根据label结合colormap得到原始颜色数据 用于最后转换
class label2image(): def init(self, num_classes=21): self.colormap = colormap(256)[:num_classes].astype(‘uint8’)
def __call__(self, label_pred,label_true):''':param label_pred: numpy:param label_true: numpy:return:'''pred=self.colormap[label_pred]true=self.colormap[label_true]return pred,true
voc数据集class对应的color 官方所给颜色
def colormap(n): cmap=np.zeros([n, 3]).astype(np.uint8)
for i in np.arange(n):r, g, b = np.zeros(3)for j in np.arange(8):r = r + (1<<(7-j))*((i&(1<<(3*j))) >> (3*j))g = g + (1<<(7-j))*((i&(1<<(3*j+1))) >> (3*j+1))b = b + (1<<(7-j))*((i&(1<<(3*j+2))) >> (3*j+2))cmap[i,:] = np.array([r, g, b])return cmap
if name == “main“: pass
# DATA_ROOT = './data/'# traindata = CustomTrainDataset(DATA_ROOT,256,256)# traindataset = DataLoader(traindata,batch_size=2,shuffle=True,num_workers=0)# for i,batch in enumerate(traindataset):# img,label = batch# print(img,label)# l1 = Image.open('data/SegmentationClass/2007_000032.png').convert('RGB')# label = image2label()(l1)# print(label[150:160, 240:250])
### `./utils/eval_tool.py`
import numpy as np
得到混淆矩阵
def _fast_hist(label_true, label_pred, n_class): mask = (label_true >= 0) & (label_true < n_class) hist = np.bincount( n_class label_true[mask].astype(int) + label_pred[mask], minlength=n_class * 2).reshape(n_class, n_class) return hist
计算图像分割衡量系数
def label_accuracy_score(label_trues, label_preds, n_class): “”” :param label_preds: numpy data, shape:[batch,h,w] :param label_trues:同上 :param n_class:类别数 Returns accuracy score evaluation result.
- overall accuracy- mean accuracy- mean IU- fwavacc"""hist = np.zeros((n_class, n_class))for lt, lp in zip(label_trues,label_preds):hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)acc = np.diag(hist).sum() / hist.sum()acc_cls = np.diag(hist) / hist.sum(axis=1)acc_cls = np.nanmean(acc_cls)iu = np.diag(hist) / ( hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist) )mean_iu = np.nanmean(iu)freq = hist.sum(axis=1) / hist.sum()fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()return acc, acc_cls, mean_iu, fwavacc
## `train.py`
-- encoding: utf-8 --
‘’’ @File : train.py @Time : 2020/08/02 10:09:54 @Author : AngYi @Contact : angyi_jq@163.com @Department : QDKD shuli @description : ‘’’
here put the import lib
import pandas as pd
import numpy as np
from utils.data_txt import image2csv #从./utils/data_txt.py中调用 image2csv
from utils.DataLoade import CustomDataset #从./utils/DataLoade.py中调用 CustomDataset
from torch.utils.data import DataLoader
from utils.model import FCN32s,FCN8x # 调用模型
from utils.Unet import UNet # 调用模型
import torch
import os
from torch import nn,optim
from torch.nn import functional as F
from utils.eval_tool import label_accuracy_score # 模型评判的几个标准计算
————————- 超参数设定 ———————————
GPU_ID = 1 INPUT_WIDTH = 320 INPUT_HEIGHT = 320 BATCH_SIZE = 32 NUM_CLASSES = 21 LEARNING_RATE = 1e-3 epoch = 60
—————————— 生成csv —————————
DATA_ROOT = ‘./data/‘ image = os.path.join(DATA_ROOT,’JPEGImages’) label = os.path.join(DATA_ROOT,’SegmentationClass’) slice_data = [0.7,0.1,0.2] # 训练 验证 测试所占百分比 tocsv = image2csv(DATA_ROOT,image,label,slice_data,INPUT_WIDTH,INPUT_HEIGHT) tocsv.generate_csv()
——————————————————————-
model_path=’./model/best_model.mdl’ result_path=’./result.txt’ if os.path.exists(result_path): os.remove(result_path)
train_csv_dir = ‘data/train.csv’ val_csv_dir = ‘data/val.csv’ train_data = CustomDataset(train_csv_dir,INPUT_WIDTH,INPUT_HEIGHT) train_dataloader = DataLoader(train_data,batch_size = BATCH_SIZE,shuffle = True,num_workers = 2)
val_data = CustomDataset(val_csv_dir,INPUT_WIDTH,INPUT_HEIGHT) val_dataloader = DataLoader(val_data,batch_size = BATCH_SIZE,shuffle = True,num_workers = 2)
net = FCN8x(NUM_CLASSES)
net = UNet(3,NUM_CLASSES) use_gpu=torch.cuda.is_available()
构建网络
optimizer=optim.Adam(net.parameters(),lr=LEARNING_RATE,weight_decay=1e-4) criterion=nn.NLLLoss() if use_gpu: torch.cuda.set_device(GPU_ID) net.cuda() criterion=criterion.cuda()
训练验证
def train(): best_score=0.0 for e in range(epoch): net.train() train_loss=0.0 label_true=torch.LongTensor() label_pred=torch.LongTensor() for i,(batchdata,batchlabel) in enumerate(train_dataloader): ‘’’ batchdata:[b,3,h,w] c=3 batchlabel:[b,h,w] c=1 直接去掉了 ‘’’ if use_gpu: batchdata,batchlabel=batchdata.cuda(),batchlabel.cuda()
output=net(batchdata) # 输出大小(batch,num_class,width,height)output=F.log_softmax(output,dim=1) # 计算21类的可能性大小loss=criterion(output,batchlabel)pred=output.argmax(dim=1).squeeze().data.cpu() # 输出可能性最大的那一类的索引,就是类别real=batchlabel.data.cpu()optimizer.zero_grad()loss.backward()optimizer.step()train_loss+=loss.cpu().item()*batchlabel.size(0)label_true=torch.cat((label_true,real),dim=0)label_pred=torch.cat((label_pred,pred),dim=0)train_loss/=len(train_data)acc, acc_cls, mean_iu, fwavacc=label_accuracy_score(label_true.numpy(),label_pred.numpy(),NUM_CLASSES)print('\nepoch:{}, train_loss:{:.4f}, acc:{:.4f}, acc_cls:{:.4f}, mean_iu:{:.4f}, fwavacc:{:.4f}'.format(e+1,train_loss,acc, acc_cls, mean_iu, fwavacc))with open(result_path, 'a') as f:f.write('\n epoch:{}, train_loss:{:.4f}, acc:{:.4f}, acc_cls:{:.4f}, mean_iu:{:.4f}, fwavacc:{:.4f}'.format(e+1,train_loss,acc, acc_cls, mean_iu, fwavacc))net.eval() # 验证集val_loss=0.0val_label_true = torch.LongTensor()val_label_pred = torch.LongTensor()with torch.no_grad():for i,(batchdata,batchlabel) in enumerate(val_dataloader):if use_gpu:batchdata,batchlabel=batchdata.cuda(),batchlabel.cuda()output=net(batchdata)output=F.log_softmax(output,dim=1)loss=criterion(output,batchlabel)pred = output.argmax(dim=1).squeeze().data.cpu()real = batchlabel.data.cpu()val_loss+=loss.cpu().item()*batchlabel.size(0)val_label_true = torch.cat((val_label_true, real), dim=0)val_label_pred = torch.cat((val_label_pred, pred), dim=0)val_loss/=len(val_data)val_acc, val_acc_cls, val_mean_iu, val_fwavacc=label_accuracy_score(val_label_true.numpy(),val_label_pred.numpy(),NUM_CLASSES)print('epoch:{}, val_loss:{:.4f}, acc:{:.4f}, acc_cls:{:.4f}, mean_iu:{:.4f}, fwavacc:{:.4f}'.format(e+1,val_loss,val_acc, val_acc_cls, val_mean_iu, val_fwavacc))with open(result_path, 'a') as f:f.write('\n epoch:{}, val_loss:{:.4f}, acc:{:.4f}, acc_cls:{:.4f}, mean_iu:{:.4f}, fwavacc:{:.4f}'.format(e+1,val_loss,val_acc, val_acc_cls, val_mean_iu, val_fwavacc))score=(val_acc_cls+val_mean_iu)/2if score>best_score:best_score=scoretorch.save(net.state_dict(),model_path) # 保存模型
if name == “main“: train()
```
文件流程展示
这里不展示结果,把每一步的文件输出放出,方便对应代码: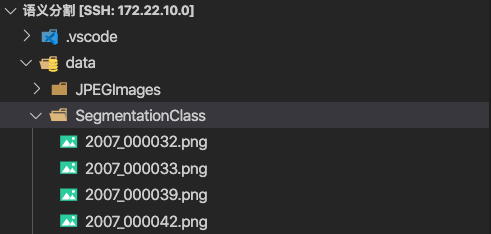
VOC 的语义分割图片数据集,包括两个文件夹如果所示,第一个是原图,格式是.jpg 第二个是label标签图片,格式是 .png
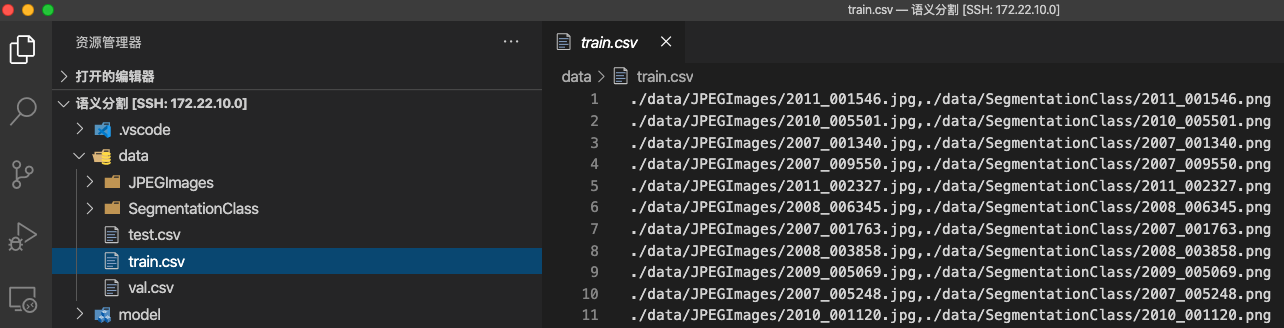
写成的csv类似上图这样,csv里有两列,一列是原图路径,一列是标签路径
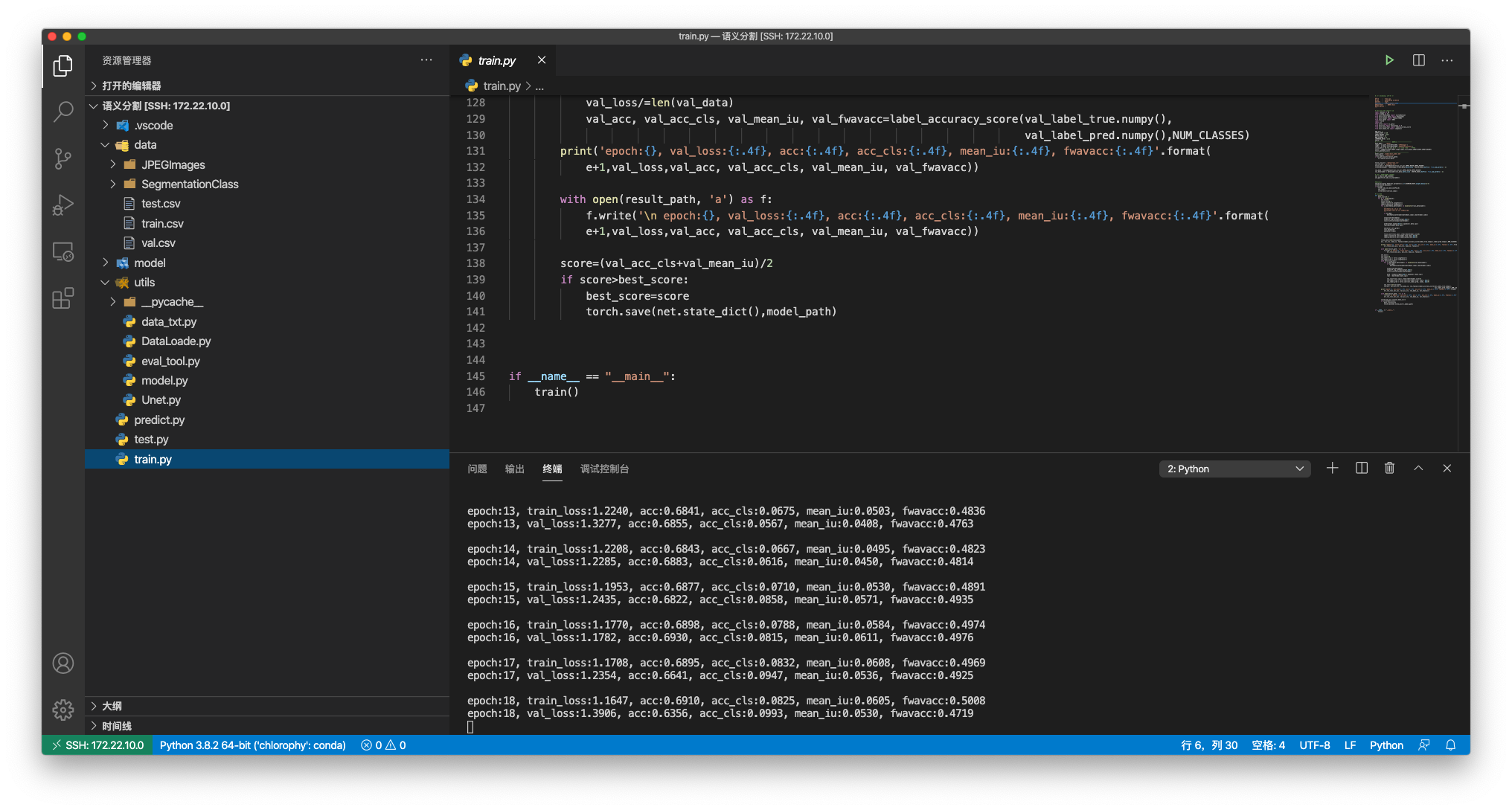
总的文件目录以及训练输出如图中所示。

若有收获,就点个赞吧
0 人点赞
