语义分割以及其初期代表网络
背景
CNN的发展为图像领域提供了重要的网络利器,其对图像分类任务尤其擅长。
但是语义分割任务不同于图像分割,这是一个空间密集型的任务,需要对每个像素进行分类。
FCN (2015 CVPR)
论文地址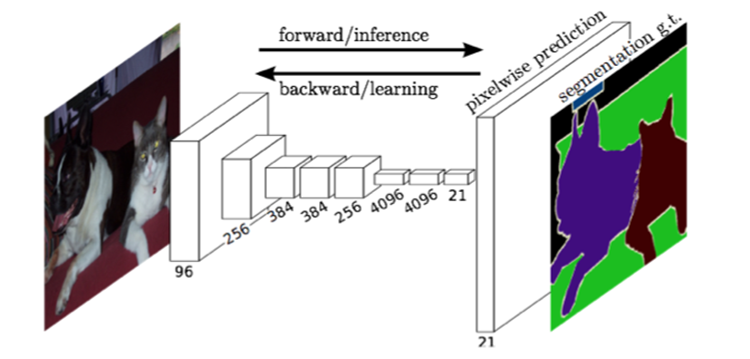
全卷积网络(FCN)是语义分割的开山之作,实现了从图像到图像的像素级别分类,为语义分割任务的发展打开了局面。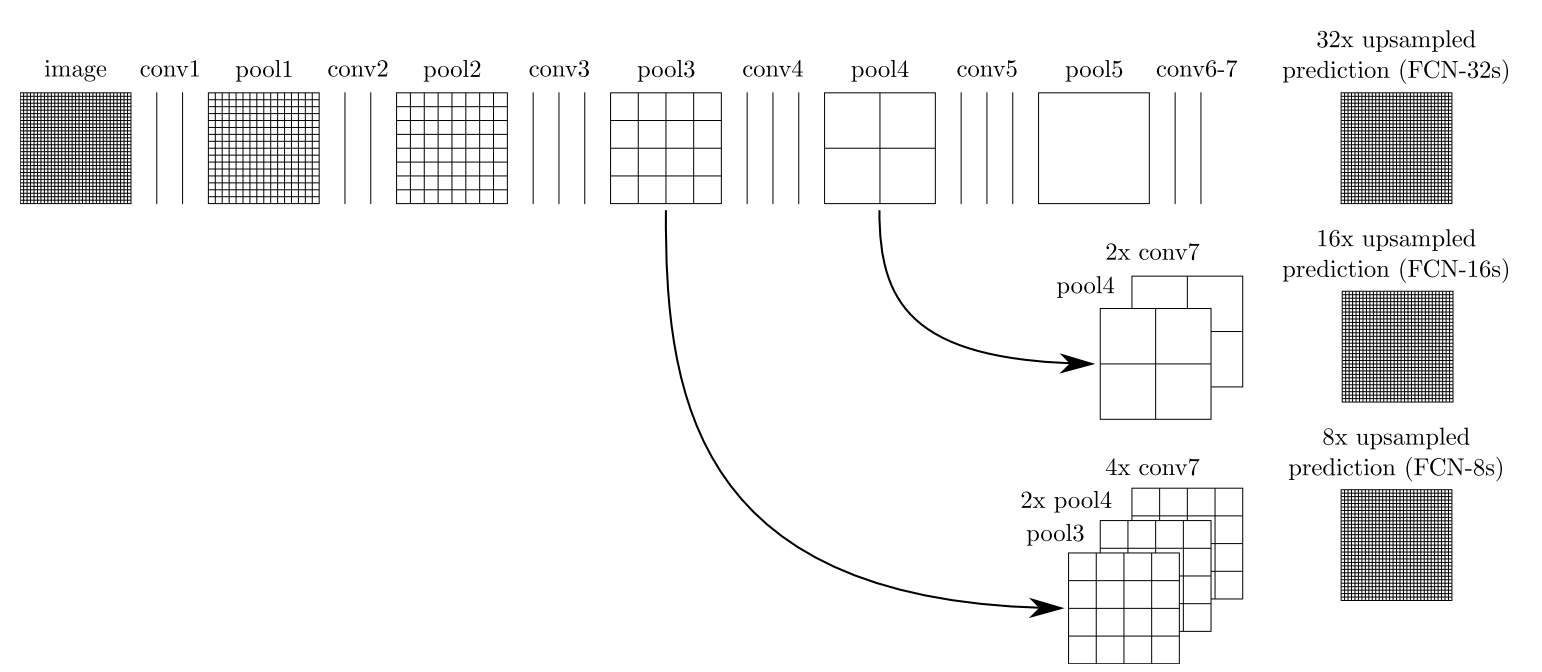
重要可学习特点
优点:
- 没有全连接层(FC)的全卷积网络,可以适应任意尺寸输入。
- 不同尺度的融合操作,以及最后的反卷积上采样操作。
缺点:
- 得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
细节学习
这里疑问比较大的操作就是最后的上采样,是怎么讲融合后的特征图直接上采样到原图大小的?
在Pytorch中使用的是 torch.nn.ConvTranspose2d()这一函数,详细计算公式可以看这里.
总结起来就是,先对输入的特征图进行一定操作,比如padding或者interpolation,然后设置新的卷积核,用新的卷积核在变换后的特征图上进行正常卷积。
Unet (2015 MICCAI)
论文地址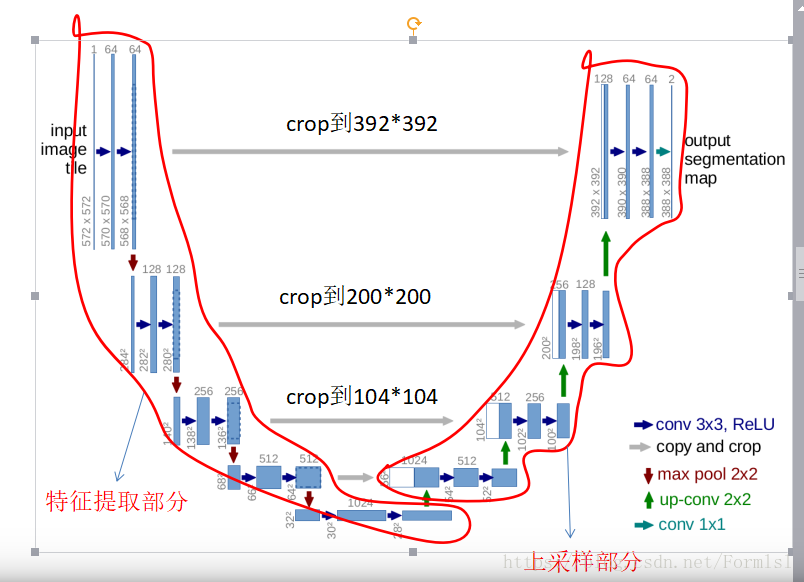
Unet是在FCN的基础上进行的改进,采用编码解码的结构,因为结构图类似字母U,因此取名U-net。
重要可学习特点
优点:
- FCN 的融合操作是点对点相加,而U-net的融合操作是在通道维度上进行堆叠。
- 上采样的步数与下采样完全一致,而且中间进行了所有尺度的融合操作,实现了对图像特征的多尺度特征识别。
这样的结果就是,能够很好的获取先验信息,对细节提取会好点。
推荐阅读
DeepLab
v1

DeeplabV1是在VGG16的基础上做了修改:
- VGG16的全连接层转为卷积;
- 最后两个池化层去掉,后续使用空洞卷积。
V2

DeeplabV2是在DeeplabV1基础上做了修改:
- 使用多尺度获得更好的分割效果(使用ASPP)
- 基础层由VGG16转为ResNet
V3
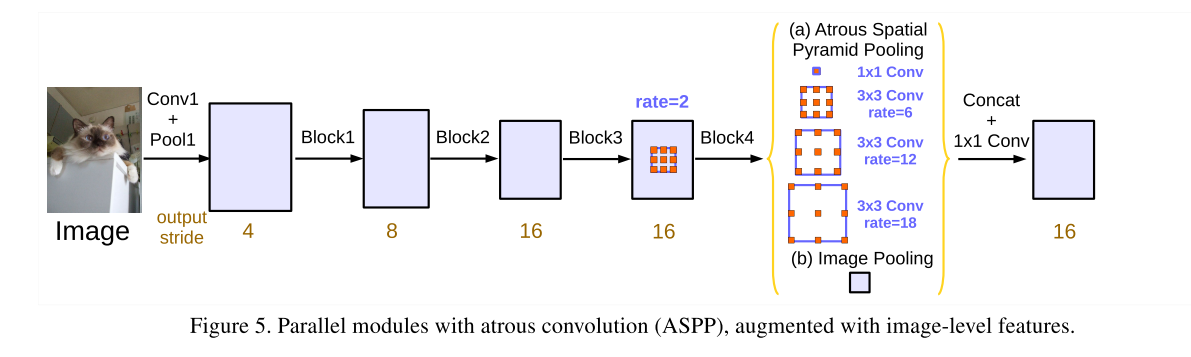
重要可学习特点
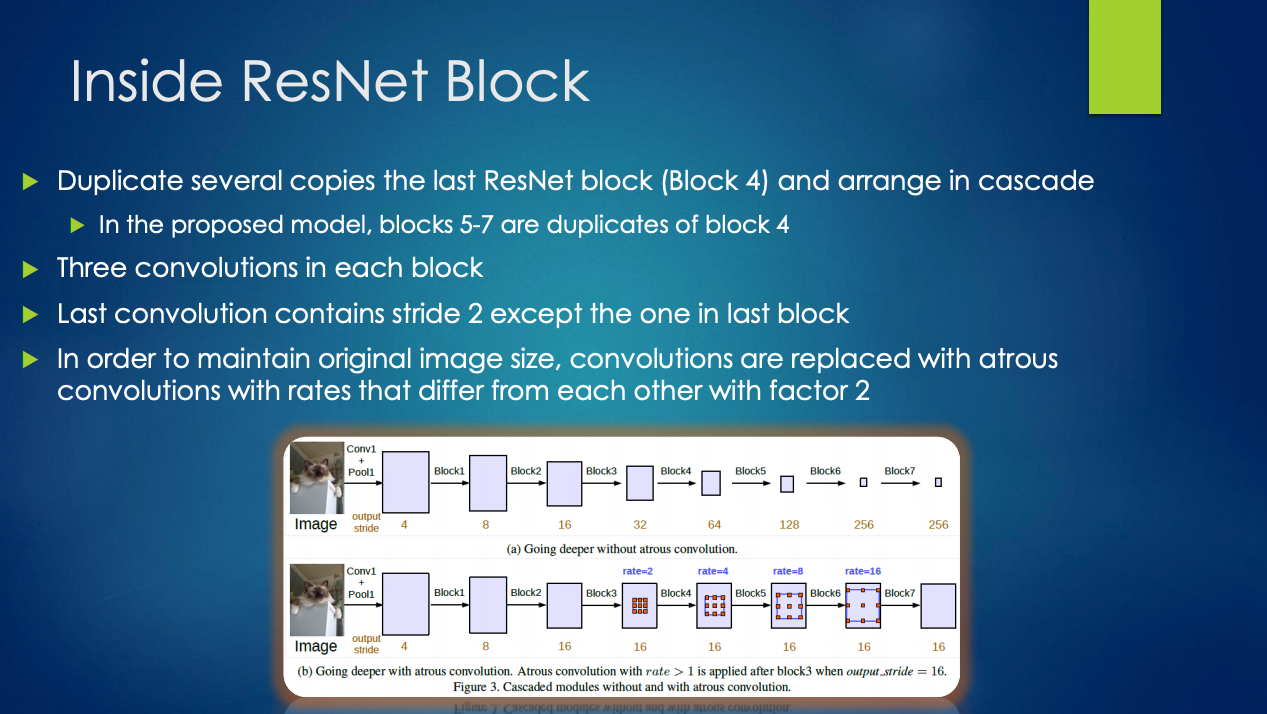
v3的主要创新点就是改进了ASPP模块,一个11的卷积和3个33的空洞卷积,每个卷积核有256个且都有BN层,包含图像及特征(全局平均池化)。
- 提出了更通用的框架,适用于任何网络;
- 复制了resnet最后的block,并级联起来
- 在ASPP中使用BN层
- 没有随机向量场
推荐阅读
网络基本实现及实验结果
在VOC2012数据集上粗略完成了三种网络的语义分割任务,这里不详细对比其精度,粗略地来说,Deeplab精度要高点,Fcn第二,unet第三,由于没有进行完整的调参过程,这个结果仅代表实验结果。主要目的是学习网络结构,练习编码能力。


最后这里续上篇代码,这里附predict.py
import pandas as pdimport numpy as npfrom utils.DataLoade import CustomDataset# from torch.utils.data import DataLoaderfrom model.FCN import FCN32s,FCN8xfrom model.Unet import UNetimport torchimport osfrom model.DeepLab import DeepLabV3# from torch import nn,optim# from torch.nn import functional as Ffrom utils.eval_tool import label_accuracy_scoremodel = 'UNet'GPU_ID = 1INPUT_WIDTH = 320INPUT_HEIGHT = 320BATCH_SIZE = 32NUM_CLASSES = 21LEARNING_RATE = 1e-3model_path='./model_result/best_model_{}.mdl'.format(model)torch.cuda.set_device(GPU_ID)# net = FCN8x(NUM_CLASSES)# net = net.cuda()# net = DeepLabV3(NUM_CLASSES)net = UNet(3,NUM_CLASSES)#加载网络进行测试def evaluate(model):import randomfrom utils.DataLoade import label2image,RandomCropimport matplotlib.pyplot as pltfrom torch.utils.data import DataLoaderfrom PIL import Imagetest_csv_dir = './data/test.csv'testset = CustomDataset(test_csv_dir,INPUT_WIDTH,INPUT_HEIGHT)test_dataloader = DataLoader(testset,batch_size = 15,shuffle=False)net.load_state_dict(torch.load(model_path,map_location='cuda:1'))# index = random.randint(0, len(testset) - 1)# index = [5,6]for (val_image,val_label) in test_dataloader:# val_image, val_label = test_dataloader[1]net.cuda()out = net(val_image.cuda()) #[10, 21, 320, 320]pred = out.argmax(dim=1).squeeze().data.cpu().numpy() # [10,320,320]label = val_label.data.numpy() # [10,320,320]val_pred, val_label = label2image(NUM_CLASSES)(pred, label)for i in range(15):val_imag = val_image[i]val_pre = val_pred[i]val_labe = val_label[i]# 反归一化mean = [.485, .456, .406]std = [.229, .224, .225]x = val_imagfor j in range(3):x[j]=x[j].mul(std[j])+mean[j]img = x.mul(255).byte()img = img.numpy().transpose((1, 2, 0)) # 原图fig, ax = plt.subplots(1, 3,figsize=(30,30))ax[0].imshow(img)ax[1].imshow(val_labe)ax[2].imshow(val_pre)# plt.show()plt.savefig('./pic_results/pic_{}_{}.png'.format(model,i))break # 只显示一个batchif __name__ == "__main__":evaluate(model)
完整实验代码

若有收获,就点个赞吧
0 人点赞
