DataFrame切分最大连续数组
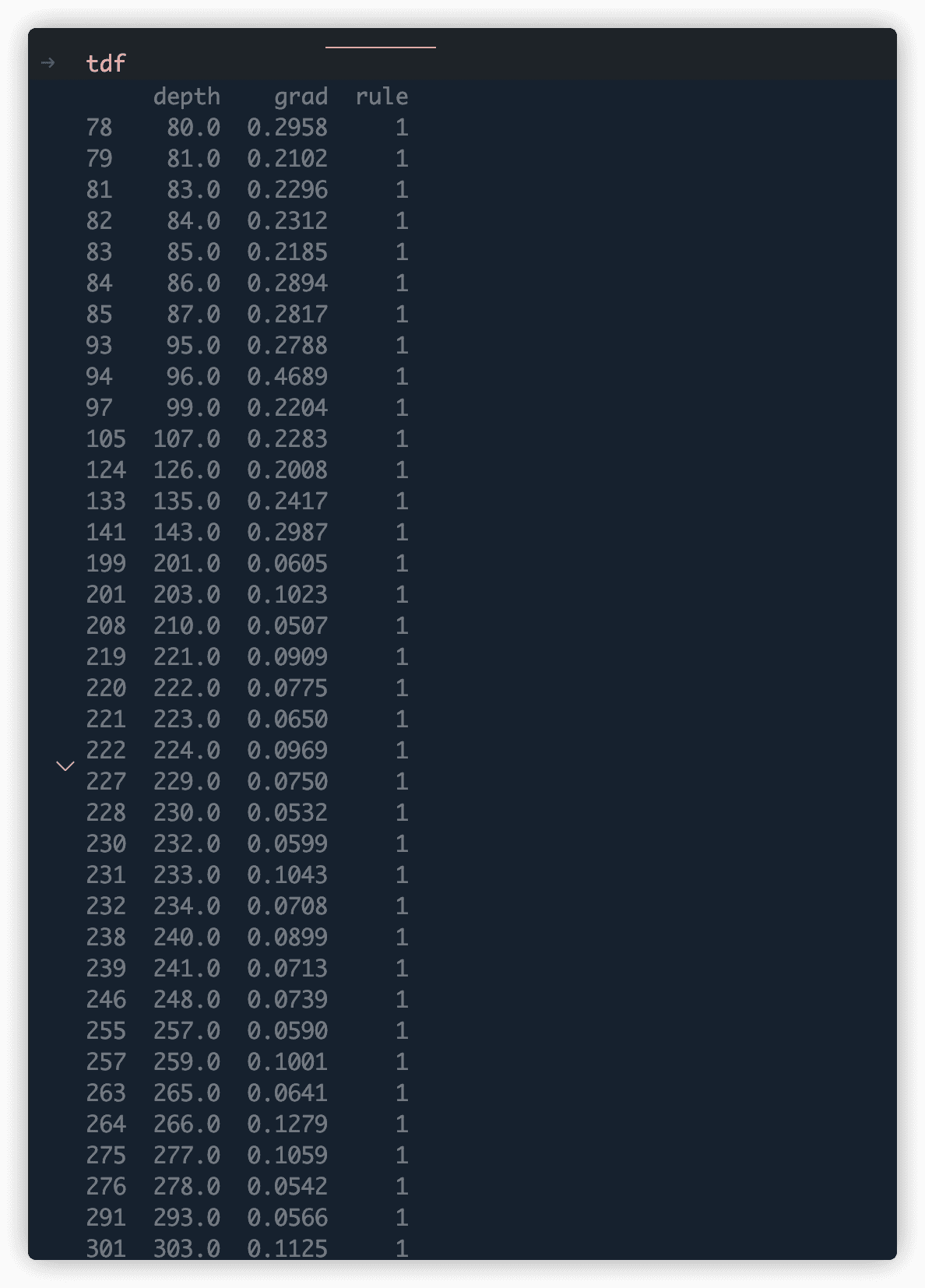 有这样一个dataframe,记录了深度和梯度,现在需要将深度递增的切分出来(<3m),并且获取最长的连续递增dataframe。
有这样一个dataframe,记录了深度和梯度,现在需要将深度递增的切分出来(<3m),并且获取最长的连续递增dataframe。
tdf['rule2'] = tdf['depth'].diff().gt(3.0).cumsum()sizes=tdf.groupby('rule2')['depth'].transform('size')tdf = tdf[sizes == sizes.max()]
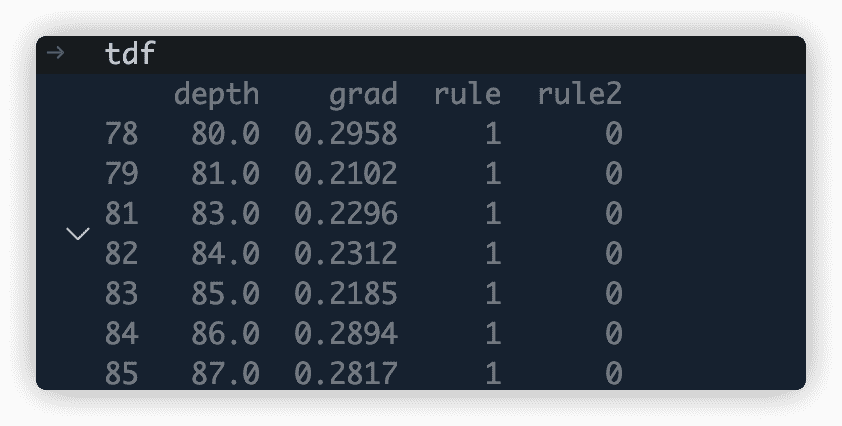 这个方法真的非常妙,没有想到,特此记录。
这个方法真的非常妙,没有想到,特此记录。
记录几个重要的pandas操作,平常没有用到,但这里使用非常方便。
- diff()
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据;相当于df-df.shift(1)
函数原型:
DataFrame.diff(periods=1, axis=0)
参数:
- periods:移动的幅度,int类型,默认值为1。
- axis:移动的方向,{0 or ‘index’, 1 or ‘columns’},如果为0或者’index’,则上下移动,如果为1或者’columns’,则左右移动。
返回值
- diffed:DataFrame类型
- DataFrame.gt() 列出大于某个值的布尔数组
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.gt.html
- DataFrame.cumsum() 累加和
这儿用这个函数非常巧妙,这样就能保证连续为True/False的对应位置都为同一个数值。
- DataFrame.transform()
>>df = pd.DataFrame({"Date": ["2015-05-08", "2015-05-07", "2015-05-06", "2015-05-05","2015-05-08", "2015-05-07", "2015-05-06", "2015-05-05"],"Data": [5, 8, 6, 1, 50, 100, 60, 120],})>>dfDate Data0 2015-05-08 51 2015-05-07 82 2015-05-06 63 2015-05-05 14 2015-05-08 505 2015-05-07 1006 2015-05-06 607 2015-05-05 120>>df.groupby('Date')['Data'].transform('sum')0 551 1082 663 1214 555 1086 667 121Name: Data, dtype: int64
有点类似apply()。

若有收获,就点个赞吧
0 人点赞
