Xarray 进阶
一些xarray专业名词
- DataArray -数据阵列
带有标记维度或命名维度的多维数组。DataArray 对象将维度名称、坐标和属性(在下面
定义)等元数据添加到基础的“未标记”数据结构。
- Dataset - 数据集
具有对齐维度的类似 dict 的 DataArray 对象集合。因此,可以对单个 DataArray 维执行的大多数操作都可以在数据集上执行。
- Variable - 变量
一个类似 netcdf 的变量,由描述单个数组的维、数据和属性组成。变量数组与 numpy 数组的主要功能区别在于变量数值操作实现了维名数组广播。每个 DataArray 都有一个可以通过 arr.variable 访问的基础变量。
- Dimension 维度
维度,我们经常称之为shape,不过在这里都是有名字的,比如dimension=(time,lat,lon)
使用场景:下载到每天的全球海温数据,每天一个nc文件,存在一个文件夹里,数据量大约有20G。
初级阶段:利用os罗列一个目录下所有nc文件,而我之前都是os循环读取,中间还需要对文件进行排序,还有可能需要重命名,而且耗时巨长!最后弄出来是array,时间维度,经纬度还需要重新读。
高级阶段:见下图,从六分钟,缩短到不到一秒!当然这个依赖于Dask,并没有将大型数据真正读入内存,需要后面进行compute()操作,具体可查Dask官方文档。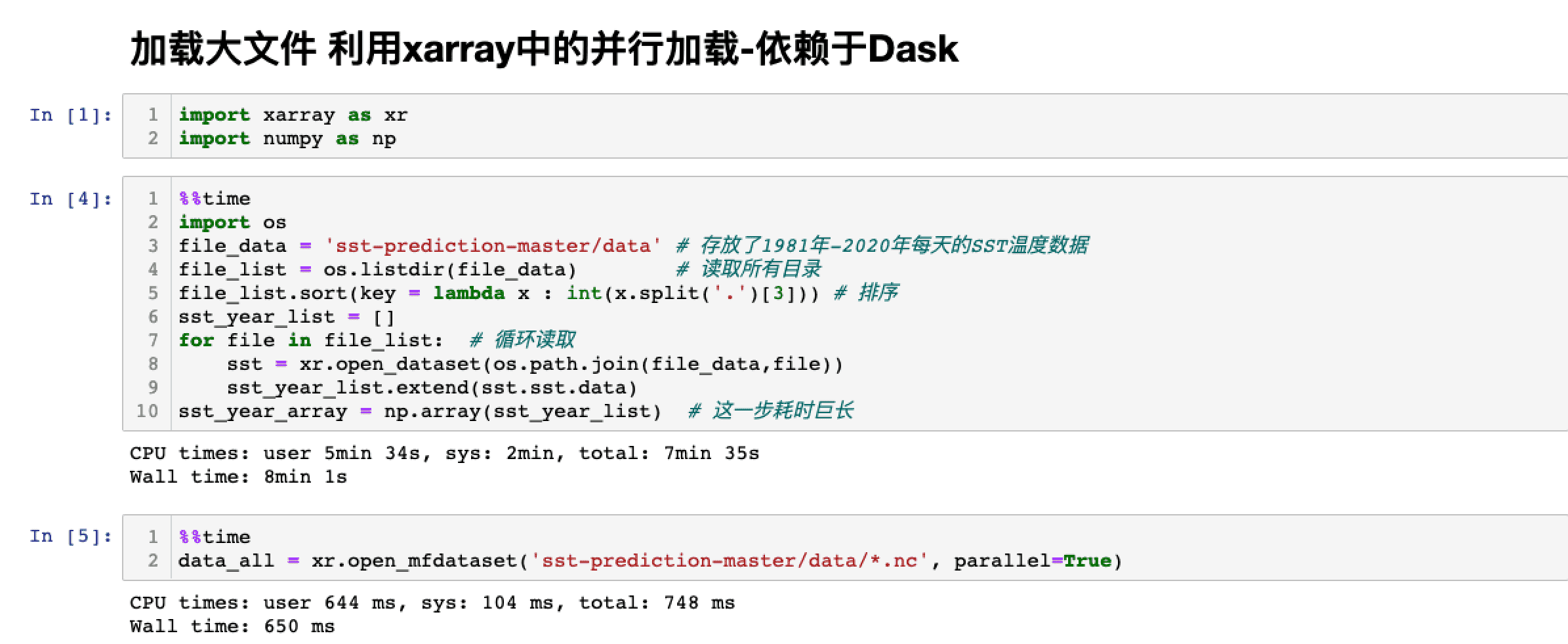
索引和选择数据
使用场景: 下载到全球数据集,需要分割某一块具体研究海域
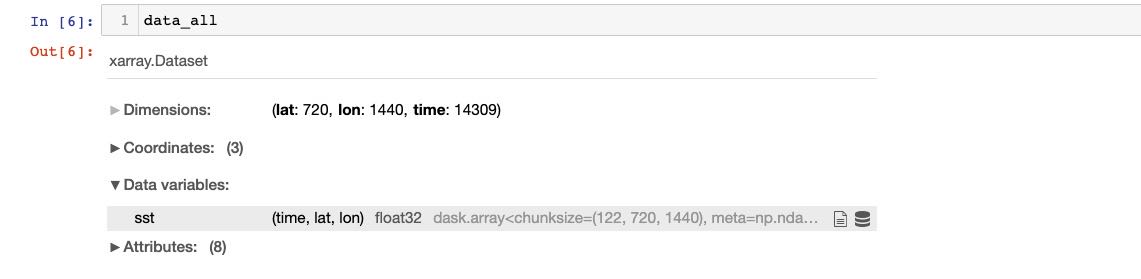
初级阶段,我们往往使用的方法是找到切割范围最大最小精度的索引值ij,然后利用序号索引将其切割出来,索引出来的维度还没有名称,需要自己记忆。
其实Xarray提供了非常便捷的切片索引方式——使用维度名称进行索引
!
dask 并行计算
以上这种array并没有完全载入内存,如果继续往后计算会记录你的计算图,知道需要输出或者你需要真正的值得时候dask才会真正的将数据载入内存进行计算。
在 jupyter lab 中安装 dask 插件,能够实时看到dask的工作流,非常的炫酷也非常的高效。
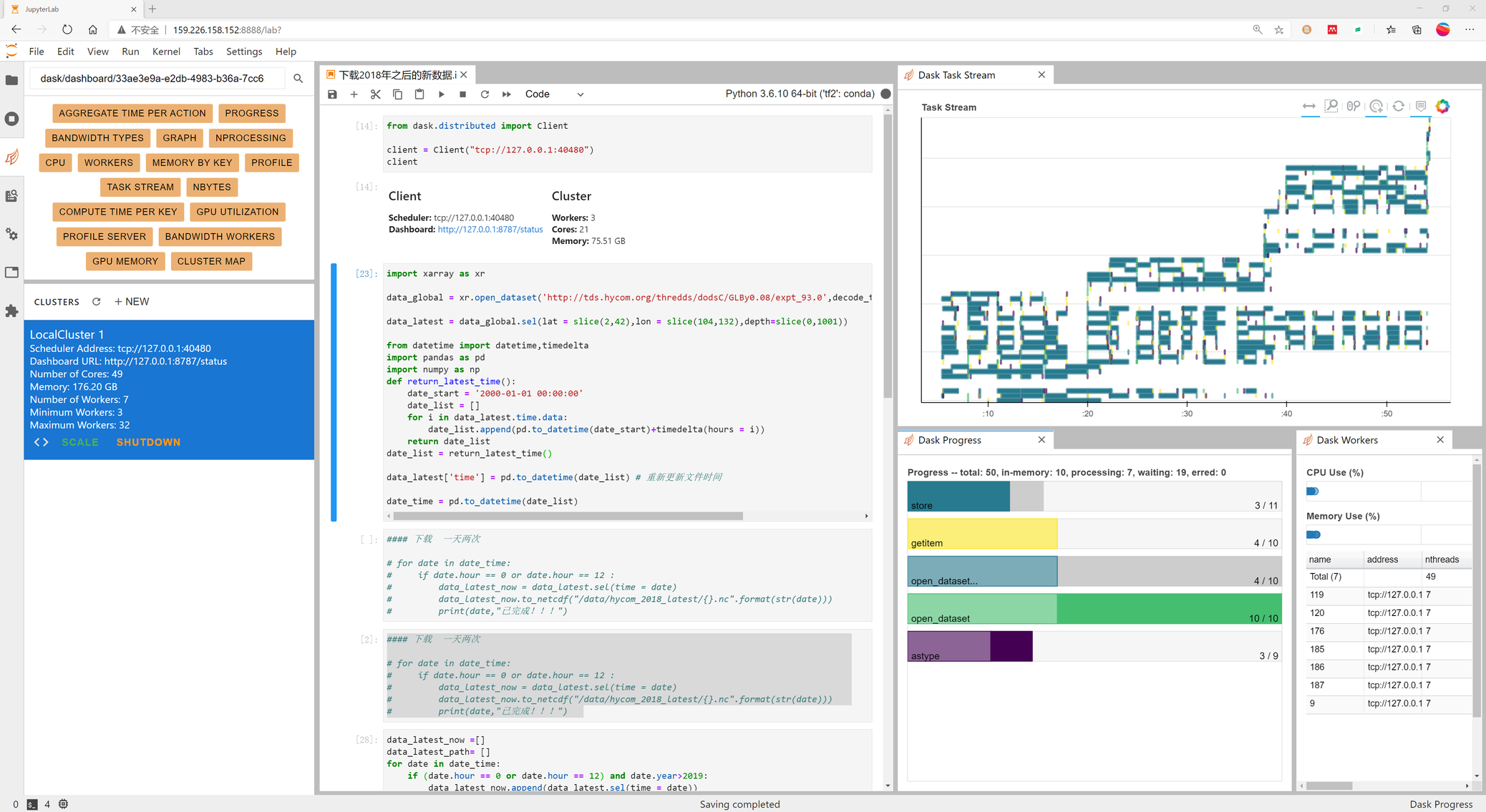
使用场景:
从 Hycom 的在线数据服务器上并行下载数据,由于其实时更新数据较为频繁,时间分辨率为3H,在这里选择每天下载两个时间点的数据。记录代码:
import xarray as xr# 利用chunks参数,将文件用dask打开data_global = xr.open_dataset('http://tds.hycom.org/thredds/dodsC/GLBy0.08/expt_93.0',decode_times=False,chunks={"time":100})#索引需要的海域范围和深度范围data_latest = data_global.sel(lat = slice(2,42),lon = slice(104,132),depth=slice(0,1001))# 更新源数据文件的时间from datetime import datetime,timedeltaimport pandas as pdimport numpy as npdef return_latest_time():date_start = '2000-01-01 00:00:00'date_list = []for i in data_latest.time.data:date_list.append(pd.to_datetime(date_start)+timedelta(hours = i))return date_listdate_list = return_latest_time()data_latest['time'] = pd.to_datetime(date_list) # 重新更新文件时间date_time = pd.to_datetime(date_list)# 构建用于mfdataset保存的数据列表和文件列表data_latest_now =[]data_latest_path= []for date in date_time:if (date.hour == 0 or date.hour == 12) and date.year>2019:data_latest_now.append(data_latest.sel(time = date))data_latest_path.append("/data/hycom_2020_latest/{}.nc".format(str(date)))xr.save_mfdataset(data_latest_now,data_latest_path)
将数据存为标准的nc文件格式
推荐的存储 xarray 数据结构的方法是 netCDF ,它是一种二进制文件格式,常见于描述地球科学的数据集。NetCDF 几乎在所有平台上都得到支持,并且绝大多数科学编程语言都支持解析器。 netCDF 的最新版本基于更广泛使用的 HDF5 文件格式。
单看官方文档可能会比较迷糊,实际操作一下,在看一下标准数据集,就能够很快的了解 xarray 的工作方式:一般格式为
ds = xr.Dataset({'prec': (('xy', 'time'), np.random.rand(4, 5))},coords={'lat': ('xy', [15, 25, 35, 45]),'lon': ('xy', [15, 25, 35, 45]),'time': pd.date_range('2000-01-01', periods=5),})# Dataset函数里面传入字典,value值那块,先表明纬度,再传入值,都是tuple格式
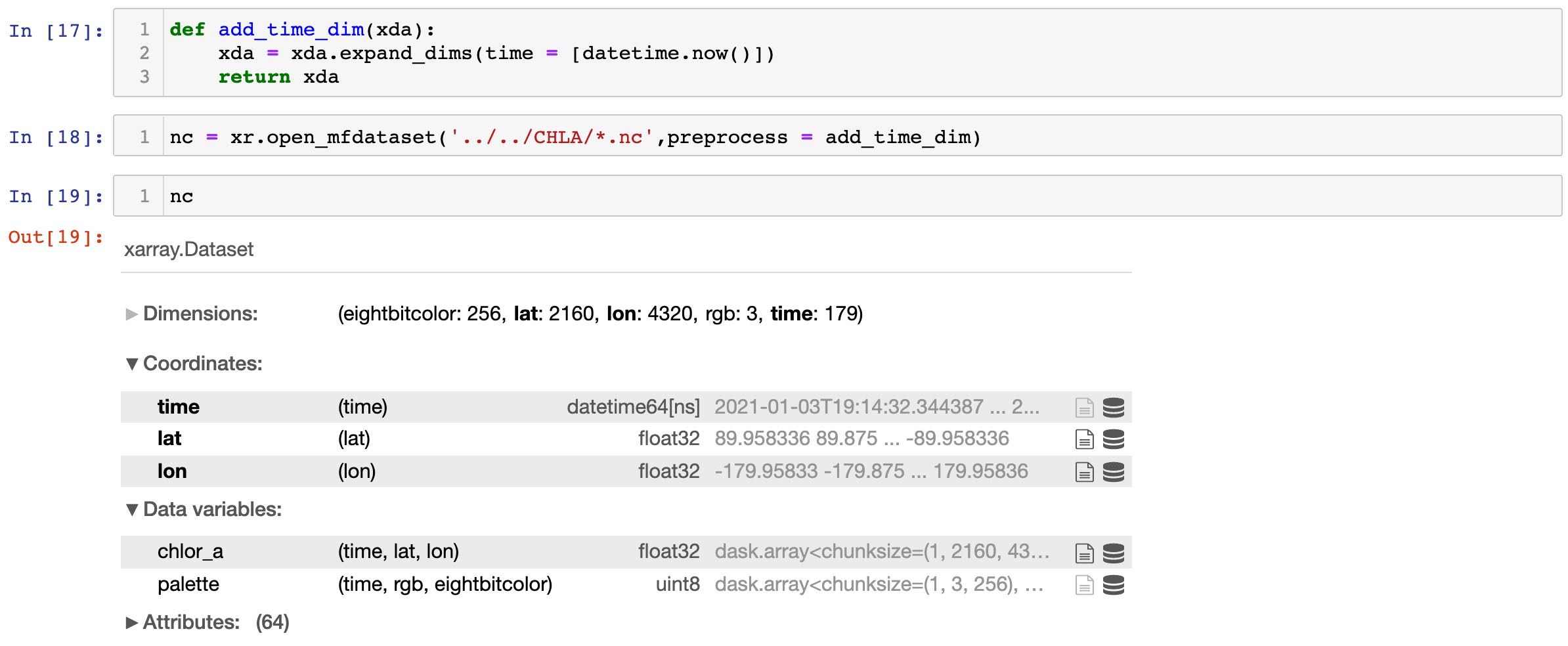
open_mfdataset()合并纬度问题
有时候如果遇到某些数据没有时间纬度,而我却想利用mfdataset()一次性导入,通常会这样报错,显示无法找到一个合适的纬度进行合并数据。
我的解决思路就是两种,要么循环单个文件,给每个nc文件增加时间维度。要么就是利用open_mfdataset一些额外的参数,直接通过函数进行读取。
按照便捷程度肯定选择第二种,经过多方查找,在openstack找到了一个比较不错的解决方案,如下图。

若有收获,就点个赞吧
0 人点赞
