传统创建线程的弊端
创建线程这个过程是会占用系统的内存资源的,系统的内存资源是有限的,在生产环境上,不可能每一个请求就创建一个线程。如果无限制地去创建线程,总会在线程积累到一定的量后,系统因为内存耗尽报OOM错误。
创建线程的公式
可创建的线程数=(进程的最大内存 - JVM分配的内存-操作系统保留的内存)/线程栈大小。
通过显示调用-Xss或-XX:ThreadStackSize参数可以设置虚拟机栈的大小,即可分配的线程的内存大小。默认为1024K的大小。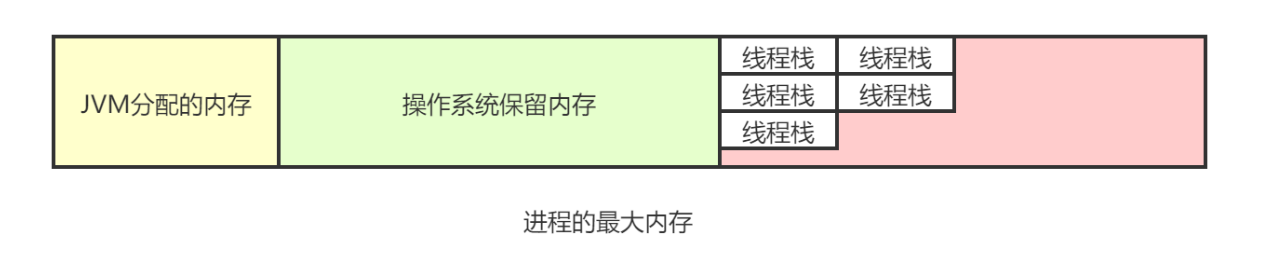
在Java语言中,每创建一个线程时,Java虚拟机就会在JVM内存中创建一个Thread对象,与此同时会创建一个操作系统的线程,最终在系统底层映射的是操作系统的本地线程(Native Thread)。
在Linux系统中,多个Java线程映射多个操作系统线程,两者之间不完全对等。
操作系统的线程使用的内存并不是JVM分配的内存,而是系统中剩余的内存(即:进程的最大内存-JVM分配的内存-操作系统保留的内存)。如果JVM分配的内存越多,那能创建的线程就越少,就越容易发生OutOfMemoryError:unable to create new native thread的异常。
基于线程池创建线程
线程池会在创建的时候,初始化创建一些核心的线程,线程数量为corePoolSize,这类线程在处理完任务不会立即销毁,而是保留在线程池里,等到有新的任务进来之后,继续使用这些线程进行处理。实现了线程的可持续复用,让这些固定的线程去执行不断产生的请求任务。
线程池的原理图
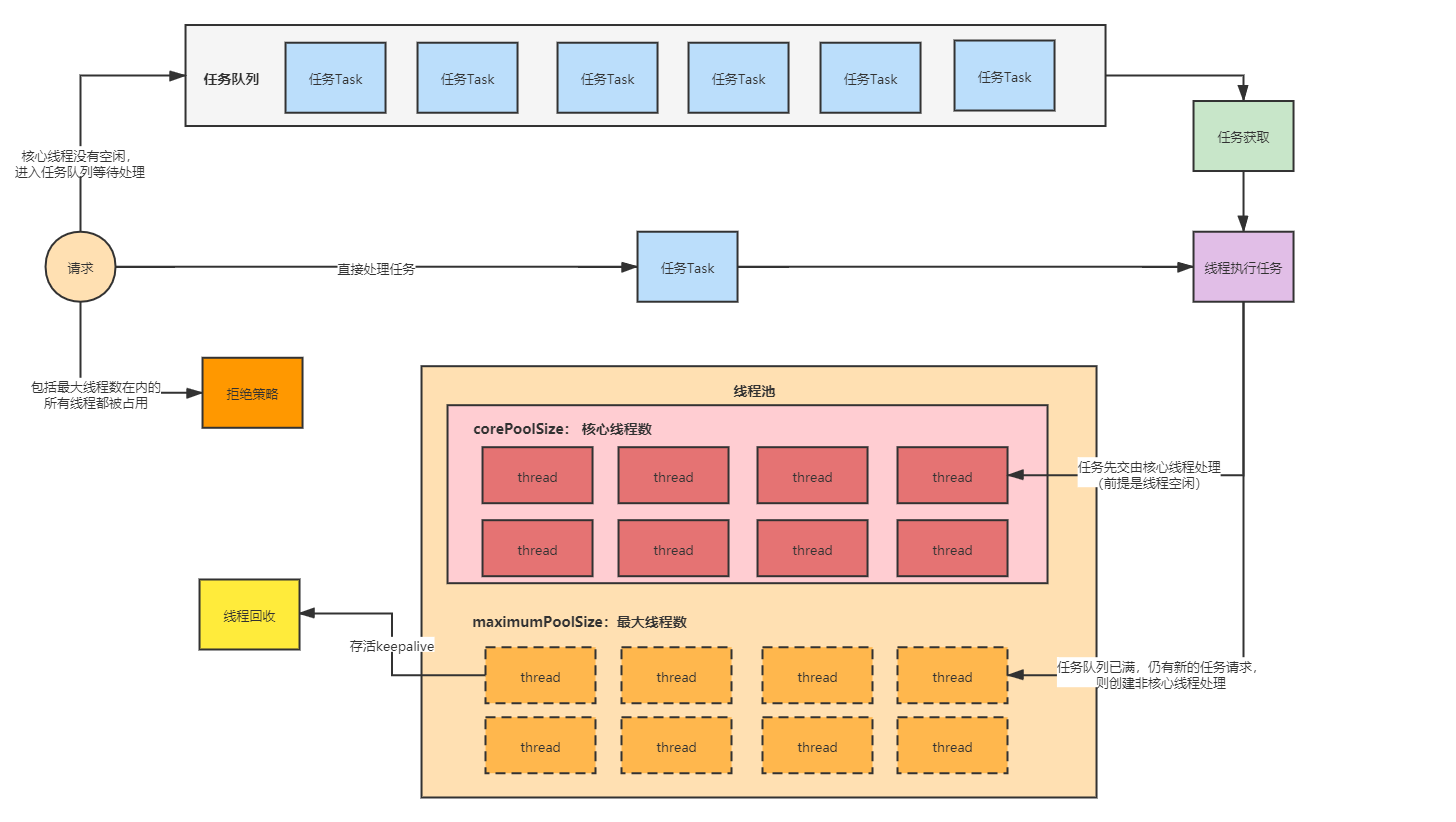
应用程序不断地往线程池中提交任务,有的任务会立即被工作线程直接执行,如果工作线程处于繁忙的执行状态,那么应用程序就会先把任务提交到任务队列里缓存起来,等到工作线程空闲之后,工作线程再从队列中取出任务进行处理。
系统创建线程池的方式
系统已有的线程池
/** 只有一个线程的线程池*/private static final ExecutorService SINGLE_THREAD_EXECUTOR= Executors.newSingleThreadExecutor();/** 线程数可变的线程池,理论上最大线程数为Integer.MAX_VALUE */private static final ExecutorService CACHED_THREAD_POOL= Executors.newCachedThreadPool();/** 固定数量线程池 */private static final ExecutorService FIXED_THREAD_POOL= Executors.newFixedThreadPool(3);/** 线程池大小为1的可定时调度任务线程池 */private static final ScheduledExecutorService SINGLE_THREAD_SCHEDULED_EXECUTOR= Executors.newSingleThreadScheduledExecutor();/** 可指定核心线程数的可定时调度任务线程池 */private static final ScheduledExecutorService SCHEDULED_EXECUTOR_SERVICE= Executors.newScheduledThreadPool(3);
newSingleThreadExecutor()方法:返回的线程池实例只有一个工作线程,如果提交超过一个任务到线程池,那么任务就会被保存在队列中。等工作线程空闲后就从队列中取出其他任务进行执行。任务队列无无界阻塞队列LinkedBlockingQueue,获取任务遵循队列的先进先出原则。public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
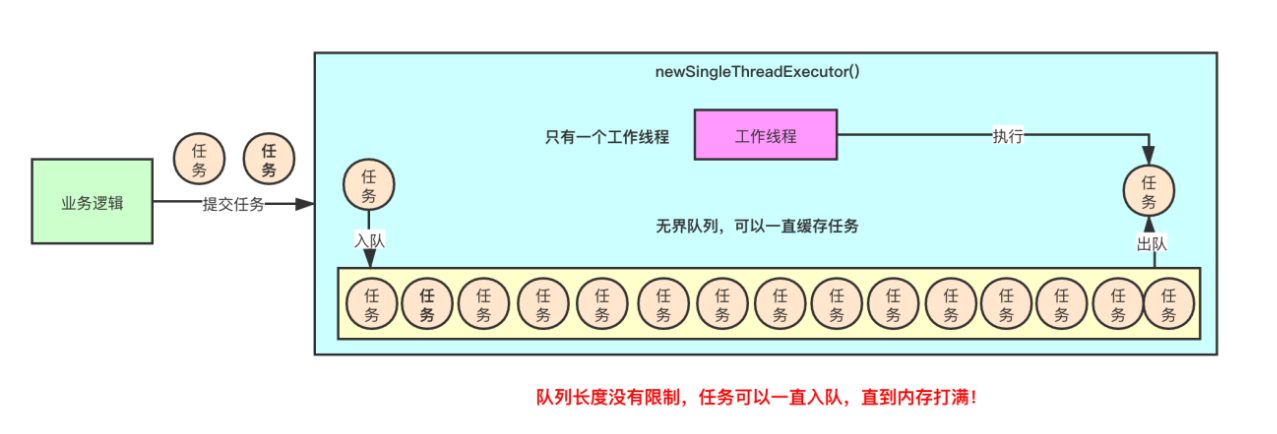
newCachedThreadPool()方法:返回的线程池实例的线程数量是可变的,理论上可以创建Integer.MAX_VALUE个线程。如果有空闲的线程能够得到复用,优先使用可被复用的线程。当目前所有的线程都处于工作状态,但是还有新的任务被提交,就会创建新的线程来调度新任务。SynchronousQueue是缓存值为1的阻塞队列,其实根本没有缓冲任务的能力。public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
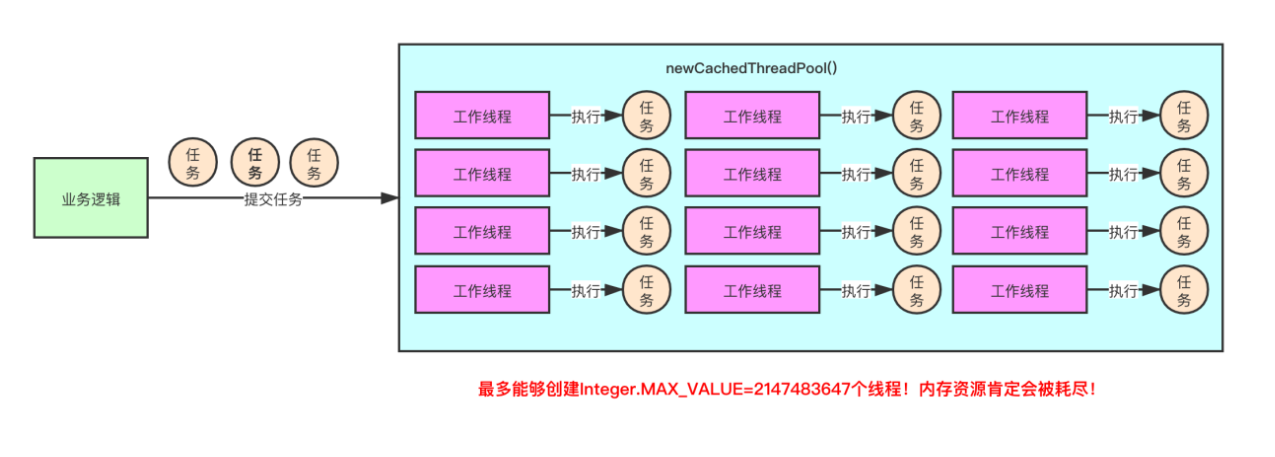
newFixedThreadPool()方法:返回的线程池实例的线程数量是固定的。核心线程数量与最大线程数量是一样的,线程池中的线程数量从线程池一开始创建就固定不变。如果提交一个任务到这个线程池里,线程池中恰好有空闲的线程,那么就会立即执行任务;否则,没有空闲的工作线程,新提交的任务就只能被暂存到一个任务队列里,等空闲线程去处理任务队列中的任务。任务队列为无界阻塞队列LinkedBlockingQueue。public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
newSingleThreadScheduledExecutor()方法:返回的是ScheduledExecutorService对象实例,继承了接口ExecutorService,并扩展了周期性调度任务的能力。 ```java public static ScheduledExecutorService newSingleThreadScheduledExecutor() {return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
- `newScheduledThreadPool()`方法:和`newSingleThreadScheduledExecutor()`类似,返回一个`ScheduledExecutorService`对象实例,同时可以指定工作线程的数量。```javapublic ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());}
基于不同业务场景使用不同类型的线程池
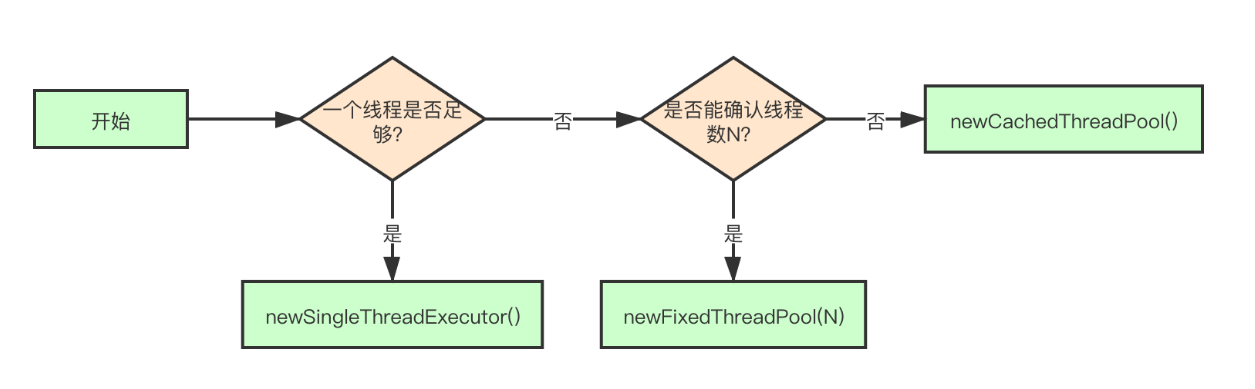
(1)如果业务场景中使用一个线程就足够,就直接选择拥有一个核心工作线程的newSingleThreadExecutor();
(2)如果在业务场景中使用一个线程不够,但是能够判断线程的数量是有限的,那么只需要指定工作线程的数量N,通过newFixedThreadPool(N)去设置线程池;
(3)如果需通过创建线程来应对一定的突发流量,保证任务处理的即时性,可以使用newCachedThreadPool();
newSingleThreadExecutor()和newFixedThreadPool(N)的线程池,使用的都是LinkedBlockingQueue无界队列。如果业务场景不适合使用无界队列,比如:任务携带的数据多,且任务的并发量大,那么可能会导致过多的任务无限制地存储到无界队列中,造成OutOfMemoryError异常。
使用newCachedThreadPool()可以无限制地创建线程,最多可以创建Integer.MAX_VALUE个线程,如果突发流量过多,会导致频繁创建新的线程,可能会出现OutOfMemoryError异常。
自定义线程池规则
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
(1)指定线程数量
线程数量主要依赖机器的CPU个数以及JVM虚拟机栈的大小,一般情况下,CPU个数时更加主要的影响因素。
根据任务关注点不同,将任务分为:CPU密集型(计算密集型)、IO密集型、混合类型密集型三大类。
CPU密集型
由于CPU计算速度很快,任务在短时间内就能够CPU超强的计算能力执行完成。所以可以设置核心线程数corePoolSIze为 N(CPU个数)+1;
设置为N+1的原因:主要为了防止某些情况下出现等待情况导致没有线程可用,比如发生缺页中断,就会出现等待情况。因此设置一个额外的线程,可以保证继续使用CPU时间片。
IO密集型
IO密集型任务在执行过程中由于等待IO结果花费的时间明显要大于CPU计算所花费的时间,而且处于IO等待状态的线程并不会消耗CPU资源,所以可以多设置一些线程,常见设置为 corePoolSize=N(CPU个数)*2;
(2)获取JVM所在机器的CPU个数
可以通过Runtime.getRuntime().availableProcessors()获取到JVM所在机器的CPU个数。
(3)设置线程池大小的公式

(4)选择合适的工作队列
有界队列
有界队列可以限制线程池中工作队列的长度,从而达到限制资源消耗的目的。
比如:ArrayBlockingQueue, 指定大小的LinkedBlockingQueue。
一般需要显示指定有界队列大小的最大值,而不是简单使用默认的Integer.MAX_VALUE,否则效果与直接用无界队列没有区别。
无界队列
无界队列是对工作队列的大小没有限制,所以队列承载能力取决于提交的任务数量以及任务占用资源(比如内存大小)的情况。
比如:不指定大小的LinkedBlockingQueue。
在高并发场景下慎重使用无界队列,地并发、少量任务提交场景下可以适当使用无界队列。
同步队列
本质上是没有工作队列的缓存空间,默认情况下,如果在offer提交任务时,线程池中没有空闲的线程从队列中取出任务,这次的提交任务就会失败。线程池会新建一个新的线程去处理这个提交失败的任务。
比如:SynchronousQueue
对同步队列的线程池的线程最大数量进行限制,而不是简单使用Integer.MAX_VALUE,否则会导致工作线程数量一直增加,直到抛出异常。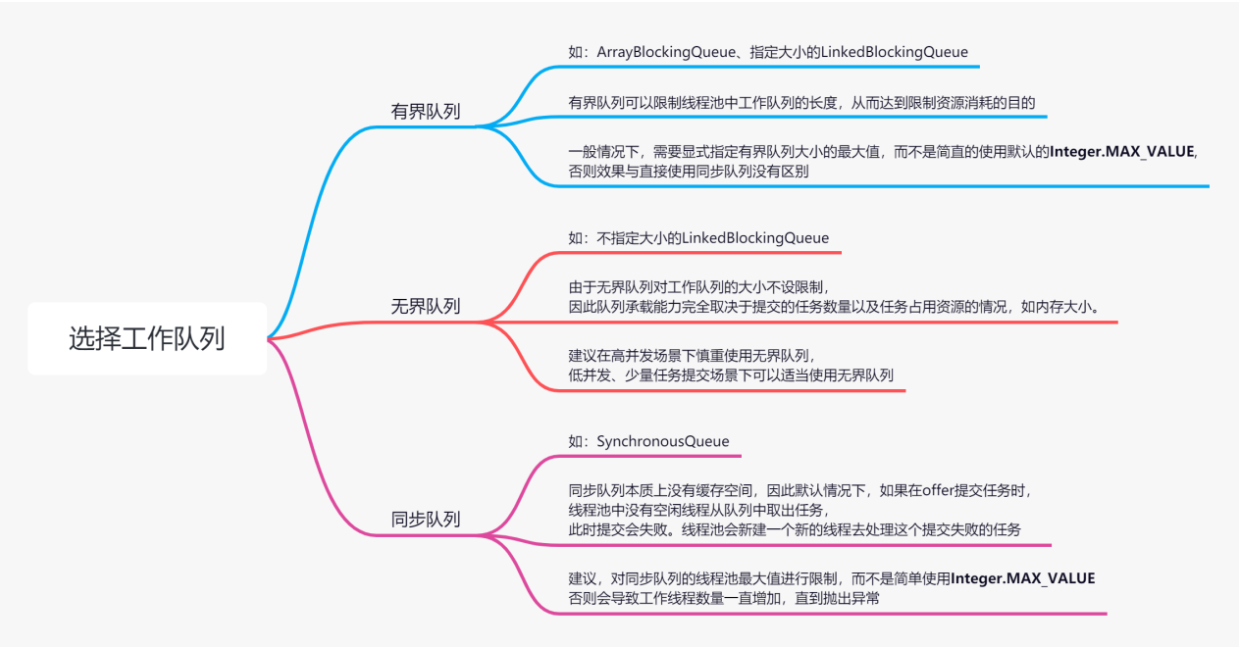
(5)自定义线程工厂
需要实现ThreadFactory接口。
new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, "custom-name-thread-pool");thread.setDaemon(true);return thread;}}
(6)选择拒绝策略
AbortPolicy拒绝策略
该策略会直接抛出RejectedExecutionException异常,从而阻止任务执行;
DiscardPolicy拒绝策略
该策略会默默丢弃无法处理的任务,对任务不做任何处理,如果当前业务允许丢失任务,就可以使用这个策略;
DiscardOldestPolicy拒绝策略
该策略会优先将阻塞队列中最老的任务丢弃,也就是目前队列头部即将被调度的那个任务,然后舱室提交当前的最新的任务到队列中;
CallerRunsPolicy拒绝策略
只要线程还没关闭,那么这个策略就会直接在提交任务的用户线程中执行当前任务。可以保证任务不会被丢弃,但是可能会阻塞用户线程上的其他任务,造成业务性能下降。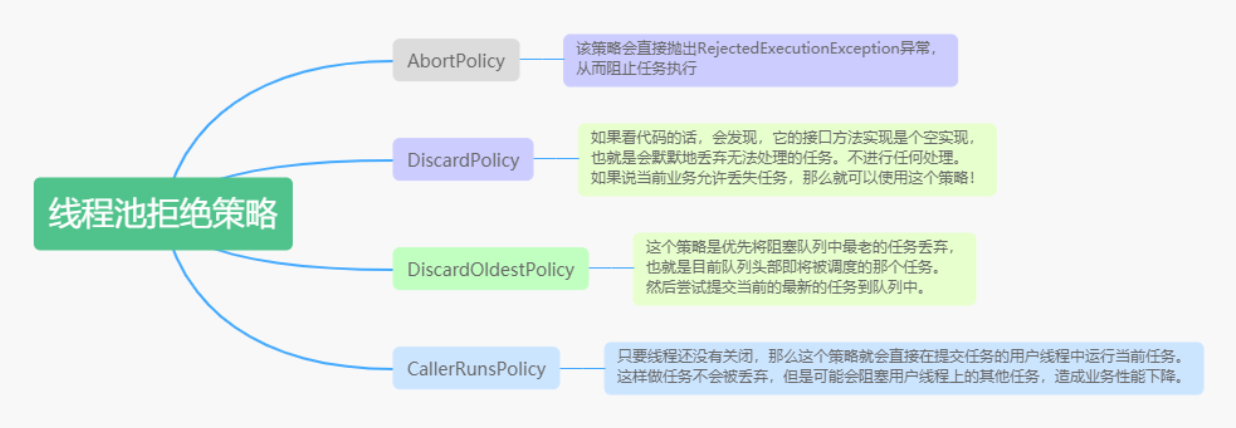
自定义线程池案例
定义一个静态成员变量ThreadPool
public class CustomThreadPoolExecutor {public static final ExecutorService CUSTOM_THREAD_POOL = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors() + 1,Runtime.getRuntime().availableProcessors() * 2,60,TimeUnit.SECONDS,new LinkedBlockingDeque<>(200),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, "custom-name-thread-pool");thread.setDaemon(true);return thread;}},new ThreadPoolExecutor.CallerRunsPolicy());}
定义一个ThreadPool的Bean实例
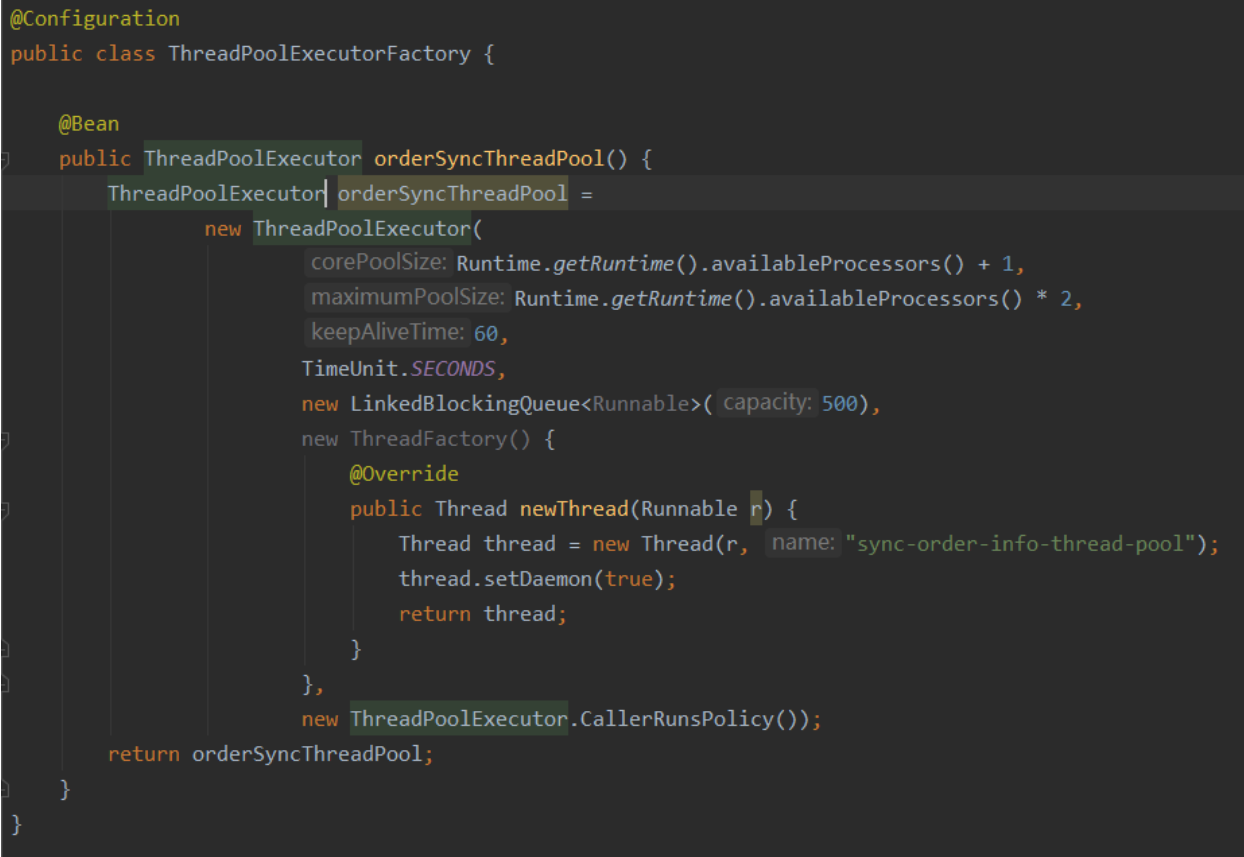
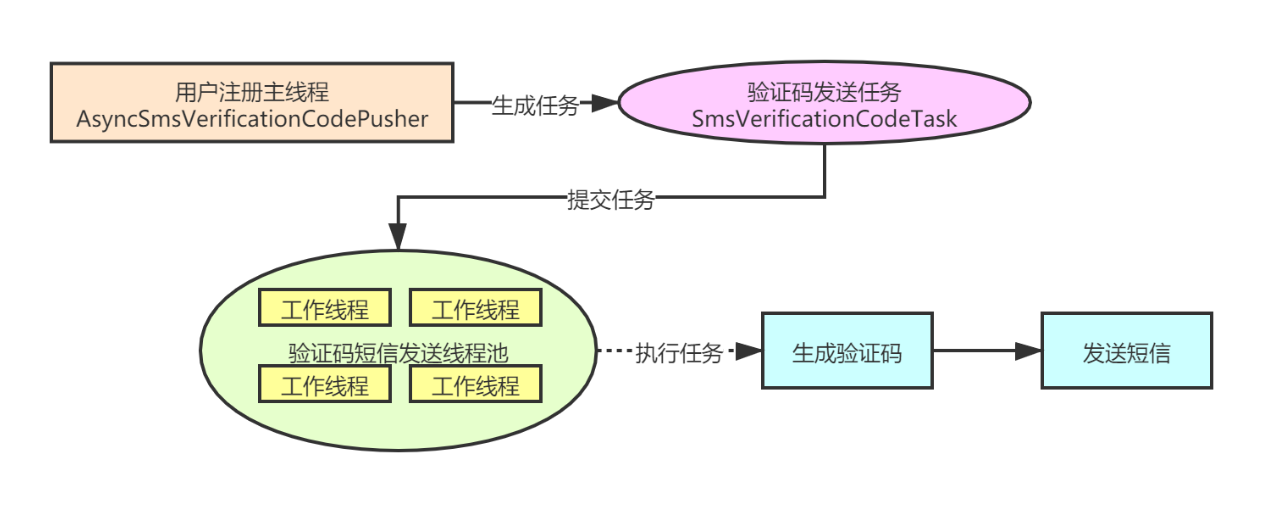
基于线程池开发验证码场景示例
基本调用过程
伪代码示例
import java.util.concurrent.*;public class SmsVerifyThreadPoolExecutor {public static final ExecutorService CUSTOM_THREAD_POOL = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors() + 1,Runtime.getRuntime().availableProcessors() * 2,60,TimeUnit.SECONDS,new LinkedBlockingDeque<>(200),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, "sms-verify-thread-pool");thread.setDaemon(true);return thread;}},new ThreadPoolExecutor.CallerRunsPolicy());public void sendSmsVerifyCode(Runnable runnable) {CUSTOM_THREAD_POOL.submit(runnable);}public static void main(String[] args) {CustomThreadPoolExecutor executor = new CustomThreadPoolExecutor();SmsVerifyCodeTask task1 = new SmsVerifyCodeTask(18850042263L);SmsVerifyCodeTask task2 = new SmsVerifyCodeTask(13076766390L);SmsVerifyCodeTask task3 = new SmsVerifyCodeTask(18759920748L);executor.sendSmsVerifyCode(task1);executor.sendSmsVerifyCode(task2);executor.sendSmsVerifyCode(task3);try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}}
import org.assertj.core.util.Preconditions;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.text.DecimalFormat;import java.util.concurrent.ThreadLocalRandom;public class SmsVerifyCodeTask implements Runnable {private static final Logger log = LoggerFactory.getLogger(SmsVerifyCodeTask.class);private long phoneNumber;public SmsVerifyCodeTask(long phoneNumber) {Preconditions.checkArgument(String.valueOf(phoneNumber).length() == 11, "phomeNumber length must be 11!");this.phoneNumber = phoneNumber;}@Overridepublic void run() {// 生成验证码int verifyCode = ThreadLocalRandom.current().nextInt(9999);DecimalFormat df = new DecimalFormat("0000");String txtVerifyCode = df.format(verifyCode);sendMessage(phoneNumber, verifyCode);}private void sendMessage(long phoneNumber, int verifyCode) {log.info("发送短信开始:phoneNumber->{}, verifyCode->{}, threadName->{}", phoneNumber, verifyCode, Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}log.info("发送短信结束:phoneNumber->{}, verifyCode->{}, threadName->{}", phoneNumber, verifyCode, Thread.currentThread().getName());}}
日志打印结果
2021-07-25 21:40:37 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信开始:phoneNumber->18850042263, verifyCode->7530, threadName->sms-verify-thread-pool2021-07-25 21:40:37 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信开始:phoneNumber->13076766390, verifyCode->2486, threadName->sms-verify-thread-pool2021-07-25 21:40:37 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信开始:phoneNumber->18759920748, verifyCode->6939, threadName->sms-verify-thread-pool2021-07-25 21:40:38 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信结束:phoneNumber->18759920748, verifyCode->6939, threadName->sms-verify-thread-pool2021-07-25 21:40:38 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信结束:phoneNumber->18850042263, verifyCode->7530, threadName->sms-verify-thread-pool2021-07-25 21:40:38 [sms-verify-thread-pool] INFO - com.ly.ybg.thread.SmsVerifyCodeTask - 发送短信结束:phoneNumber->13076766390, verifyCode->2486, threadName->sms-verify-thread-pool

若有收获,就点个赞吧
0 人点赞
