Master选举概念和作用
Master概念
Master选举是一个分布式系统中非常常见的应用场景。分布式最核心的特性就是能够将具有独立计算能力的系统单元部署到不同的机器上,构成一个完成的分布式系统。与此同时,实际场景中需要在这些分布在不同机器上的独立系统单元中选出一个所谓的老大,在计算机中,称之为Master。
Master作用
在分布式系统中,Master往往用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权。
例如在一些读写分离的应用场景中,客户端的写请求往往是由Master来处理的。或者是在另一些场景中,Master用于负责处理复杂的逻辑,并将处理结果同步给集群中的其他系统单元。
场景示例
场景描述
集群中的所有系统单元需要对前端业务提供数据,比如一个商品ID,或者是是一个网站轮播广告的广告ID等。
而这些商品ID或是广告ID往往需要从一系列的海量数据处理中计算得到,通常这个计算过程非常耗费IO和CPU资源。鉴于计算过程的复杂性,如果让集群中的所有机器都执行这个计算逻辑的话,那么将耗费非常多的资源。
处理方案
一种比较好的方法就是只让集群中的部分,甚至是只让一台机器去处理数据计算,一旦计算出数据结果,就可以共享给整个集群中的其他所有客户端机器,这样就可以减少重复劳动,提升性能。
实现Master选举
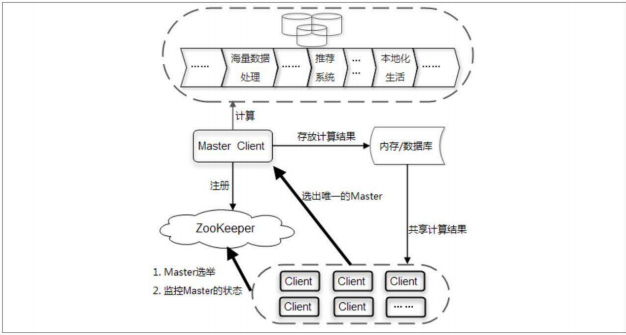
系统结构
客户端集群、 分布式缓存系统、 海量数据处理总线 和 Zookeeper 四个部分。
系统的运行机制
客户端集群每天定时会通过Zookeeper来实现Master选举。
选举产生的Master客户端之后,这个客户端会负责进行一系列的海量数据处理,最终计算得到一个数据结果,并将结果防止在一个内存/数据库中。
同时,Master还需要通知集群中其他所有的客户端从这个内存/数据库中共享计算结果。
数据库实现Master选举方案
关系型数据库的主键特性可以实现Master选举。
集群中的所有机器都向数据库中插入一条相同主键的ID记录,数据库就会自动进行主键冲突检查。也就是说,所有进行插入操作的客户端机器,只有一台机器能够成功。 —— 那么,就可以认为向数据库中成功插入数据的客户端成为Master。
该方案的弊端
如果当前选举的Master机器故障宕机了,关系型数据库无法通知该事件。就无法保证进行下一轮的Master选举。
Zookeeper实现Master选举方案
Zookeeper的两个特性:
(1)Zookeeper具有强一致性,能够保证在分布式高并发的情况下节点的创建一定是全局唯一。也就是Zookeeper将保证客户端无法重复创建一个已经存在的数据节点,即如果同时有多个客户端请求创建同一个节点,那么最终一定只有一个客户端请求能够创建成功。
(2)Zookeeper创建的临时节点,如果对应的客户端宕机了,那客户端的Session将结束,临时节点就会被清除。此时,如果Zookeeper注册了一个子节点变更的Watcher,就能够监控到当前的Master机器是否存活,一旦发现了当前的Master挂了,那么就会通知给其余客户端,其余客户端就会重新进行Master选举。(该特性保证能够快速进行集群Master动态选举。)
代码实现

若有收获,就点个赞吧
0 人点赞
