缓存雪崩现象
缓存雪崩的过程
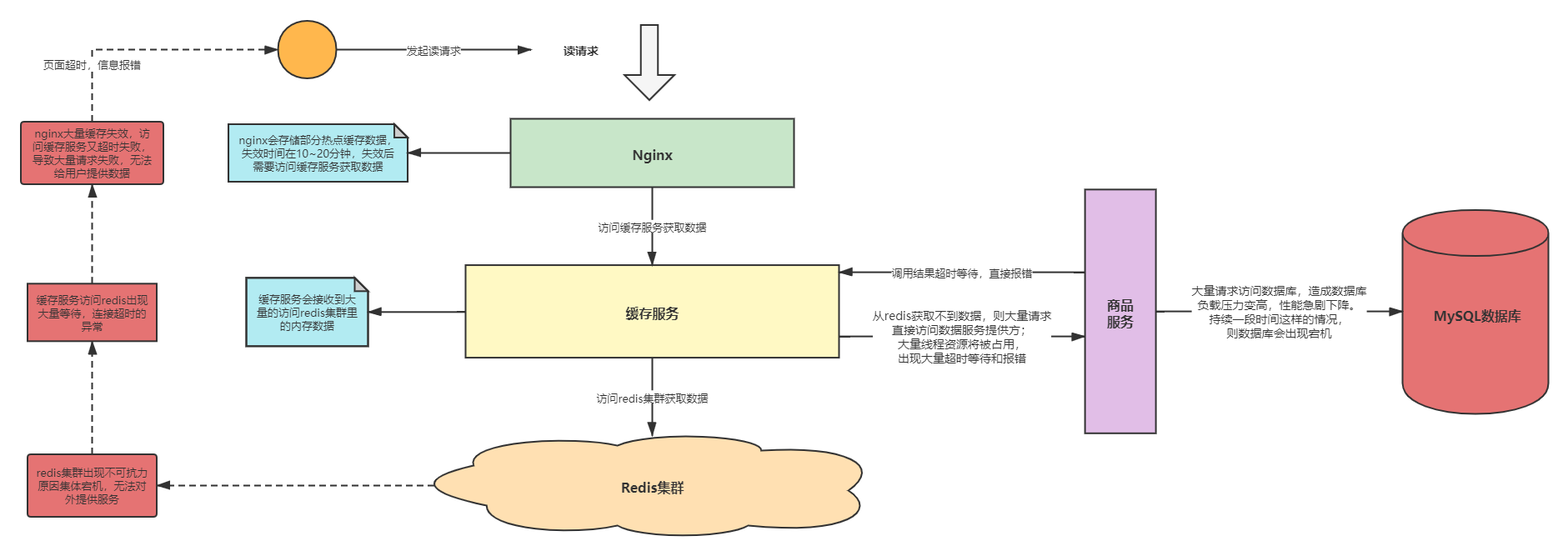
具体现象
(1)Redis集群节点全部出现宕机(比如机房集体断电);
(2)缓存服务对redis集群的大量请求由于上面的原因导致阻塞等待,占用了服务的线程资源;
(3)无法从redis集群获取数据,缓存服务需要从源头服务中去查询数据库,大量的请求涌入数据库,导致数据库负载压力过大,数据库直接宕机;
(4)源头服务因为数据库宕机也一起崩溃,对源头服务的请求也会阻塞等待,占用源头服务的线程资源;
(5)缓存服务大量的资源全部耗费在访问redis服务和源头服务上面,但却无法得到结果,最后导致自己服务也被拖死崩溃,无法提供服务;
(6)Nginx也无法去访问缓存服务和源头服务,只能基于本地缓存去提供服务,但是本地缓存存在失效时间,等到缓存过期后,就无法提供数据。
(7)最后给用户直观的感受就是页面加载超时过慢,同时伴随一些报错信息。
缓存雪崩的解决方案
事前解决方案
(1)Redis多实例集群部署,同时设置好每个Redis Master节点的主备切换,部署冗余的Slave节点,保证在Master节点出现宕机的情况下, 可以将冗余的Slave节点自动切换为Master节点。
(2)双机房部署Redis实例,一套Redis Cluster下的实例,一部分部署在一个机房,另一部分部署在另一个机房。保证在一旦单个机房出现故障,至少还有另外一个机房下的部分Redis实例可以提供服务。
事中解决方案
(1)在Redis集群已经彻底崩溃,大量请求已经无法访问到Redis的情况下。
(2)在每一台机器部署的缓存服务实例的内存中,设置一套ehcache缓存。应对redis中数据被清除的预防策略;
(3)对访问Redis做资源隔离(Hystrix舱壁模式),避免大量访问Redis的请求占用资源,导致缓存服务崩溃;
(4)对源头服务访问做限流和资源隔离(Hystrix熔断),避免大量请求涌入数据库,造成数据库崩溃,导致最后的服务雪崩问题。
事后解决方案
(1)Redis重启后,基于持久化文件的数据快速恢复;
(2)如果持久化备份文件丢失,或者数据过旧,则需要快速进行缓存预热,然后再重启Redis;
(3)缓存服务访问Redis的逻辑增加有关熔断机制的策略,half-open(半开状态),间隔一段时间,一部分请求尝试访问Redis,成功自动恢复。

若有收获,就点个赞吧
0 人点赞
