哨兵的配置
一个哨兵可以监控多个master-slave的主从架构
相同的一套哨兵集群,可以监控不同的多个redis主从集群。
配置文件: sentinel.conf (路径:redis根目录[/usr/local/redis/redis-5.0.8])
(1) sentinel monitor <master-group-name> <master-ip> <master-port> <quorum># <master-group-name> 指定监控的master名称# <master-ip> 监控master的ip地址# <master-port> 监控master的端口号# <quorum> 至少要有quorum个数量的哨兵认为master sdown,才会认为是odown,然后进行选举,故障转移# 如果发生了故障转移,或者新的哨兵进程加入哨兵集群,那么哨兵会自动更新自己的配置文件(master-name, quorum等)(2) sentinel down-after-milliseconds <master-group-name> <millseconds># <master-group-name> 指定监控的master名称# <millseconds> 哨兵如果在指定毫秒数没有与master通信,就人为master节点实例已经宕机(3) sentinel failover-timeout <master-group-name> <milliseconds>#<milliseconds> 故障转移超过指定毫秒数就认为本次故障转移失败(4) sentinel parallel-syncs <master-group-name> <num-slaves># <num-slaves> 指定在主备切换成功后,可以同时有多少个slave节点与新master节点同步数据值越小,则整体的同步时间越长(5) sentinel auth-pass <master-group-name> <password># <password> redis-master节点设置了requirepass的值(6) bind <sentinel-ip># <sentinel-ip> 哨兵的ip地址(不要填127.0.0.1)(7) port <sentinel-port># <sentinel-port> 哨兵的端口号(8) dir <working-directory># dir /var/sentinal/5000# <working-directory> 哨兵的工作目录(9) daemonize yes# 设置sentinel以后台守护进程启动(10) logfile <logfile-path># logfile /var/log/sentinel/5000# sentinel运行日志信息
启动哨兵
启动命令
redis-sentinel <sentinel.conf 路径>或redis-server <sentinel.conf 路径> --sentinel
启动的日志信息示例
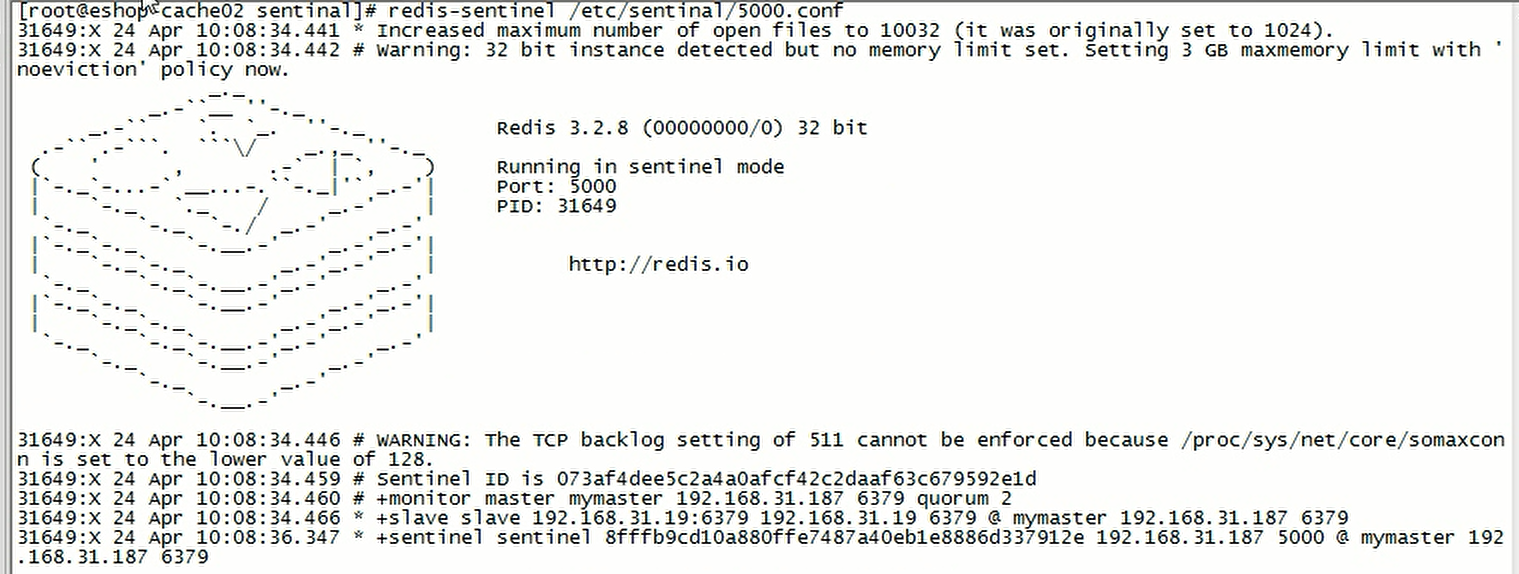
检查哨兵状态
redis-cli -h <redis-ip> -p <redis-sentinel-port>> sentinel master <master-group-name># 查看当前master 主从集群下的master信息> sentinel slaves <master-group-name># 查看当前master 主从集群下的slave信息> sentinel sentinels <master-group-name># 查看当前master 的哨兵集群> sentinel get-master-addr-by-name <master-group-name># 查看当前的master 的ip和port信息
哨兵节点的增加和删除
增加哨兵节点
(1)配置sentincel.conf(2)redis-sentinel <sentinel.conf 路径>
删除哨兵节点
(1) 停止sentinel进程 kill -9 <sentinel-pid>(2) 在其他节点sentinel使用 SENTINEL RESET * 命令清理master状态(3) 在其他节点sentinel使用 SENTINEL master <master-name> 查看所有sentinel对数量是否达成一致
基于哨兵集群架构下的安全认证
(1) master上启用安全认证 requirepass -- 6379.conf(2) slave节点连接master口令 masterauth -- 6379.conf(3) 哨兵连接master需要口令 sentinel auth-pass <master-group-name> <pass>
容灾演练
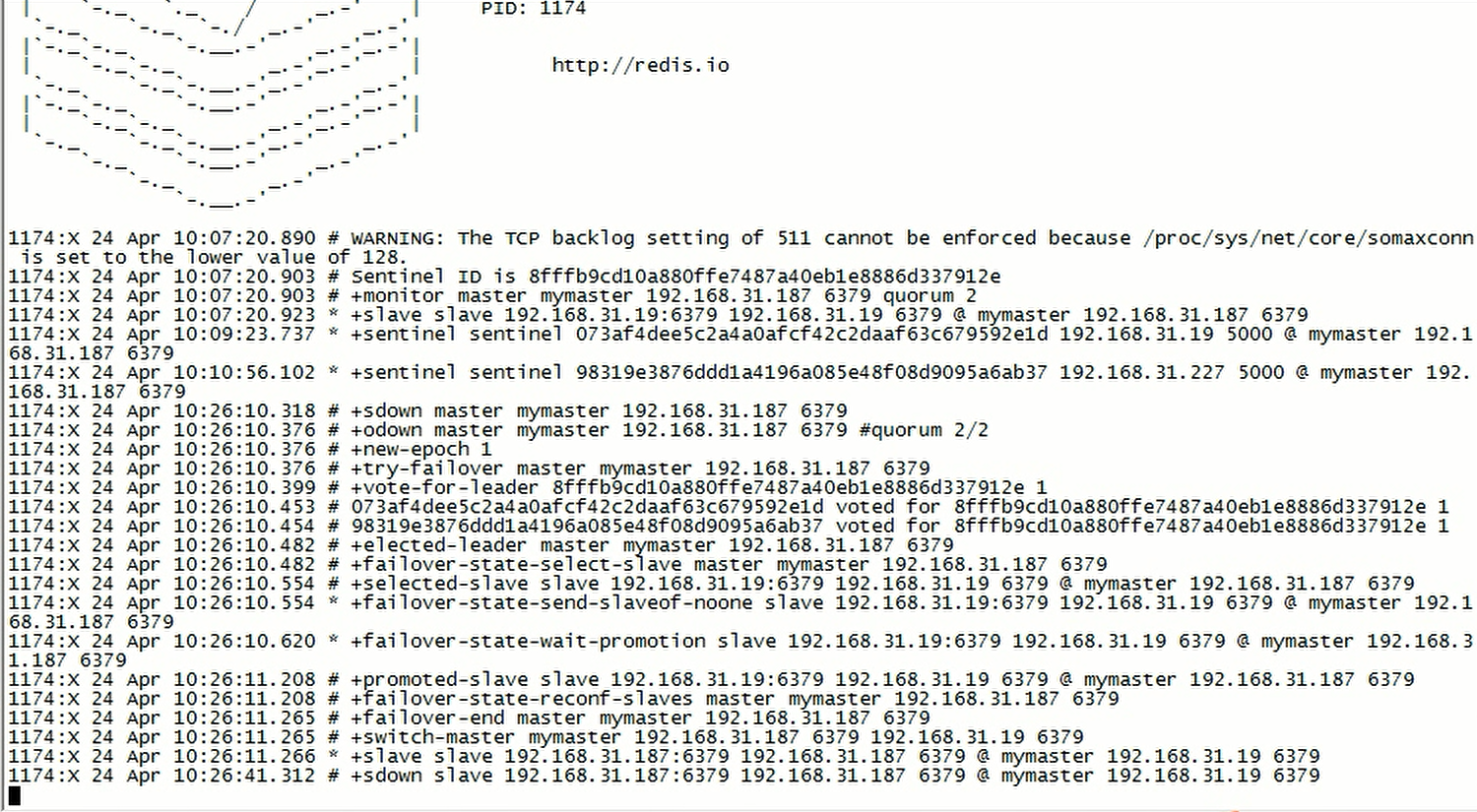
(1) 通过哨兵查看一下当前的master SENTINEL get-master-addr-by-name <master-group-name>(2) 把master节点kill -9掉,redis_6379.pid文件也删除掉(3) 查看sentinel日志,是否出现`+sdown`字样,识别出master的宕机问题如果出现了`+odown`字样,就是制定的quorum数量的哨兵,都认为master宕机- 哨兵都认为master是sdown- 超过quorum数量的哨兵进程都认为sdown,就变为odown- 选举一个哨兵(哨兵1)作为后续执行主备切换- 哨兵1去新master(将切换为master的slave节点)中获取一个新的configuration epoch(version号)- 尝试执行failover (故障转移)- 投票选举出一个slave切换为master,每个哨兵都会执行一次投票(断开时长,priority,offset,runid)- 让选举出来的slave设置为slaveof noone(不让它去做任何节点的slave),把slave切换为新master,旧master认为不再是master- 旧master角色已经切换为slave(4) 所有哨兵选举一个哨兵来执行主备切换。如果有majority数量的哨兵存在,就会执行主备切换操作(5) 再次通过哨兵查看一下当前的master SENTINEL get-master-addr-by-name <master-group-name>信息已经改变(6) 尝试连接一下新的master,通过info replication查看主从信息(7) 故障恢复,将旧master重新启动,查看是否被哨兵自动切换为slave节点
故障转移(主备切换)日志信息示例

若有收获,就点个赞吧
0 人点赞
