工作原理
三个角色:生产者,任务队列,消费者。
生产者提供任务到任务队列,消费者从任务队列中获取任务消费。
一般会存在多个生产者和多个消费者,任务队列为一个数据结构,用来存放任务数据。
通常情况下,生产者的生产任务的速率与消费者消费任务的速率不同,所以才需要中间的任务队列来存储任务。
模式优点
(1)解耦
由于中间任务队列的存在,生产线程只负责生产任务,并将任务添加到任务队列中,并不关心任务后续的消费情况。消费线程只负责从任务队列中获取任务,并对任务进行处理,并不关心任务是由谁产生的。
所以,生产者与消费者之间没有直接的依赖关系,从架构设计角度看,就是解耦。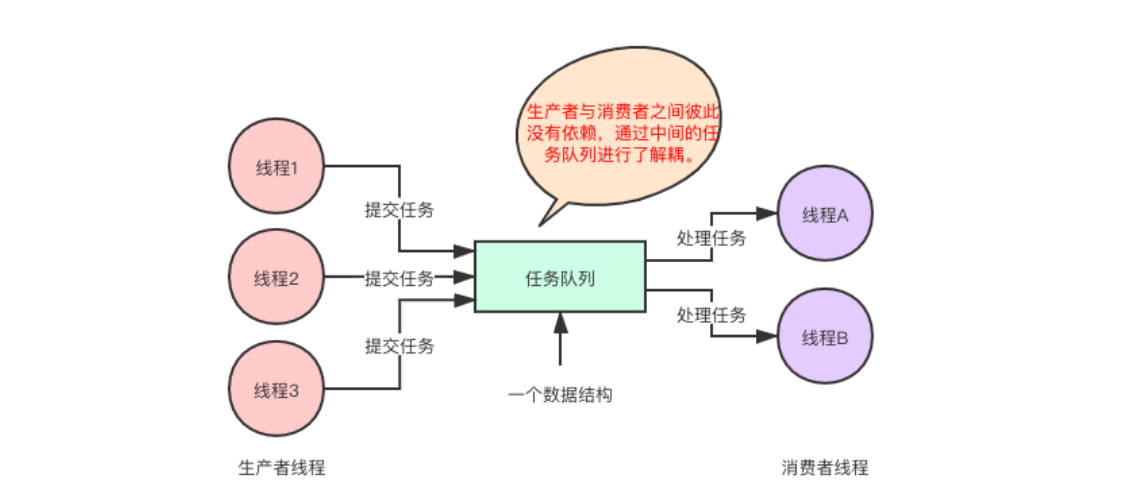
(2)支持异步处理
如果是传统方法之间的调用,调用链路的总耗时等于所有方法的执行时间总和。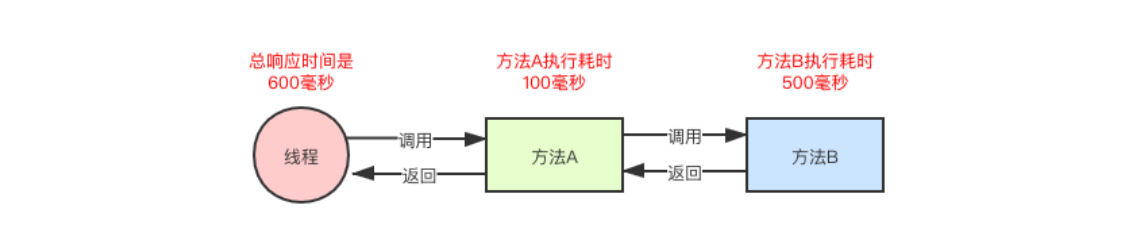
如果是基于生产者与消费者模式下,可以将较为耗时的非核心调用链路进行异步处理,只有核心的调用链路需要直接进行同步调用的操作,那整个调用链路的总耗时就能够有相应的减少。
例如,方法A的业务逻辑执行并不会依赖方法B的执行结果,就可以将方法B的调用调整为异步调用。
(3)可以消除生产和消费之间的速度差异
如果有一种情况,生产者线程每1分钟可以生产一个任务,消费者线程每1分钟可以消费五个任务。就可以通过任务队列去消除两者之间的处理任务的速度差异。
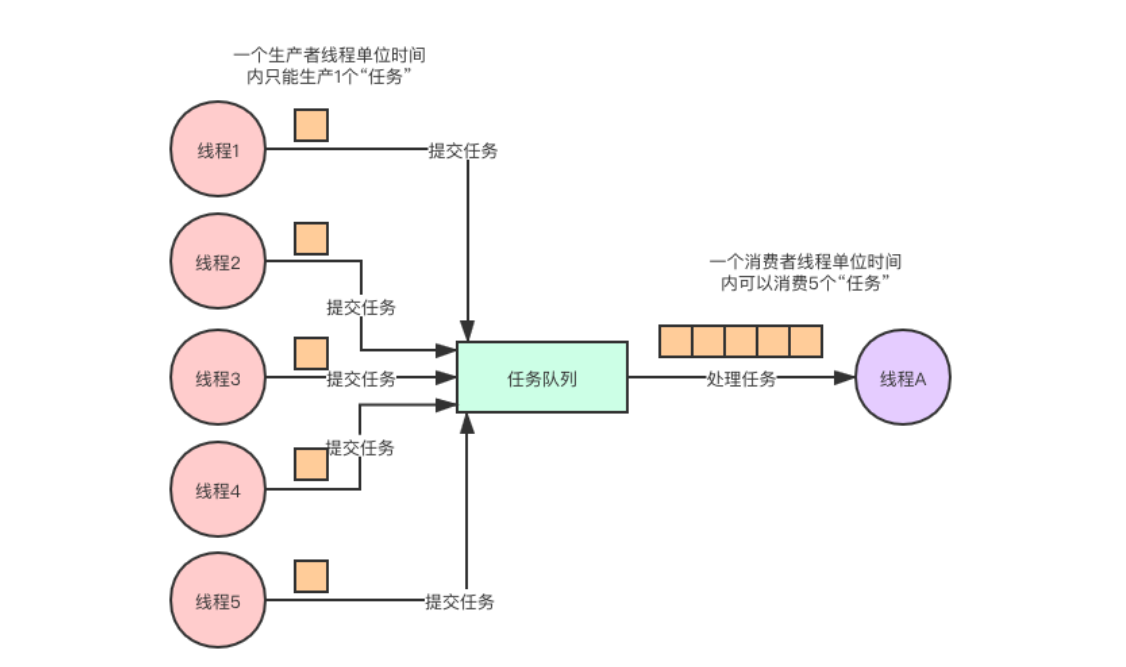
如果是生产者的生产任务的速率大于消费者处理任务的速率,中间的任务队列就可以很好的形成缓冲的作用。保证生产消费过程中,消费者处理任务的速度并不会受生产者生产任务速度的影响。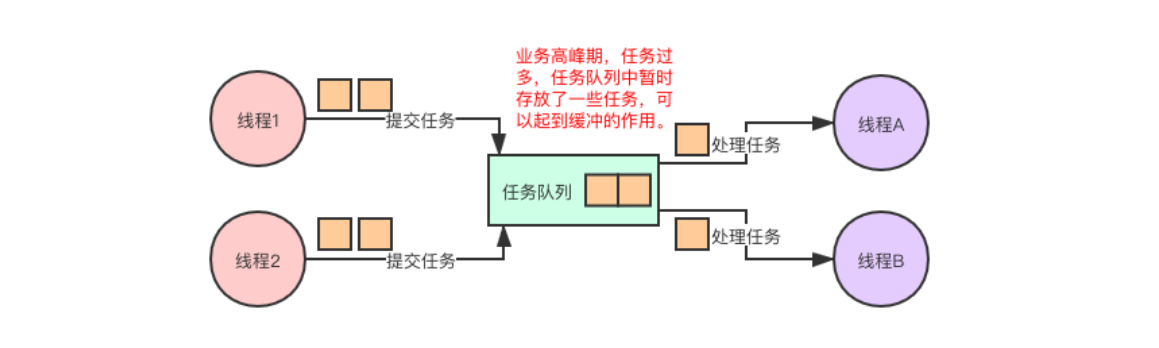
业务场景
场景描述
互联网房产交易合同管理平台。用户需要在互联网平台进行房产交易,通过交易凭证签署一份电子合同,签署完毕后会将电子合同上传到系统中,平台会将电子合同存储到文件服务器上。
对于用户来说,只是简单地上传一下电子合同,但是平台后续是需要根据一些条件查找这些合同,可能根据合同内的某些关键内容进行全文检索。所以在保存电子合同文件的同时,需要对合同的内容进行分析,然后创建相应的索引文件,以供平台需要对这些电子合同附件进行全文检索时使用。
完整的业务流程
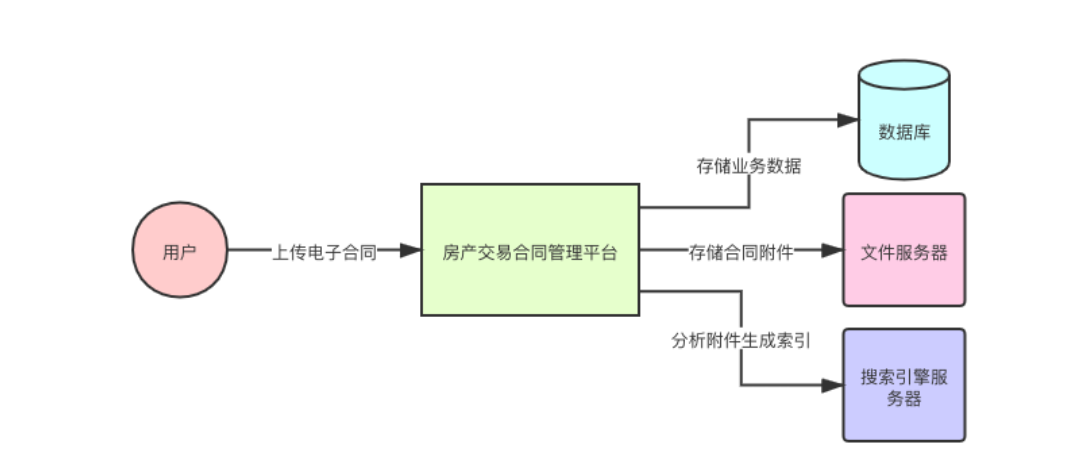
对电子合同内容生产索引文件的过程包括文件IO和一些计算,过程会耗费不少时间,如果直接使用同步调用的方式进行处理,会在用户进行了上传电子合同的操作后,系统一直等待结果响应,直接造成页面卡死。
同步调用的伪代码
public class HouseAttachmentSyncProcessor {public HouseAttachmentSyncProcessor() {}public void uploadHouseAttachment(HouseContractFile houseContractFile) {// 存储业务数据saveBizData(houseContractFile);// 存储电子合同附件saveAttachmentFile(houseContractFile);// 分析附件并生成索引createFileIndex(houseContractFile);return;}private void saveAttachmentFile(HouseContractFile houseContractFile) {System.out.println("=====存储电子合同附件完成=====");}private void saveBizData(HouseContractFile houseContractFile) {System.out.println("=====存储业务数据完成=====");}private void createFileIndex(HouseContractFile houseContractFile) {try {Thread.sleep(20000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("=====分析附件并生成索引完成=====");}public static void main(String[] args) {long startTime = System.currentTimeMillis();System.out.println("业务处理开始时间:" + startTime);HouseAttachmentSyncProcessor processor = new HouseAttachmentSyncProcessor();HouseContractFile houseContractFile = new HouseContractFile();processor.uploadHouseAttachment(houseContractFile);long endTime = System.currentTimeMillis();System.out.println("业务处理完成时间:" + endTime);System.out.println("总耗时时间:" + (endTime - startTime));}}###### 执行结果 ######业务处理开始时间:1627129615946=====存储业务数据完成==========存储电子合同附件完成==========分析附件并生成索引完成=====业务处理完成时间:1627129635960总耗时时间:20014
基于生产者消费者模式实现的异步调用
分析业务流程可以知道,流程当中的【分析附件文件索引】 的任务会极大耗费时间,同时这个任务也并不是用户需要关注的地方,所以可以基于生产者与消费者模式实现该任务的异步调用。
如果单单只是创建一个子线程来异步处理【分析附件文件索引】的任务的话,在高并发场景下,可能就会导致创建大量的子线程处理任务,直接耗费系统大量的资源。所以不能直接让每一个用户请求都去创建一个子进程异步处理【分析附件文件索引】的任务。
此时需要一个任务队列,负责去暂存用户请求下增加的【分析附件文件索引】任务,起到缓冲的作用。然后再启动一定量的线程(消费者线程)去负责将任务队列中的任务提取处理。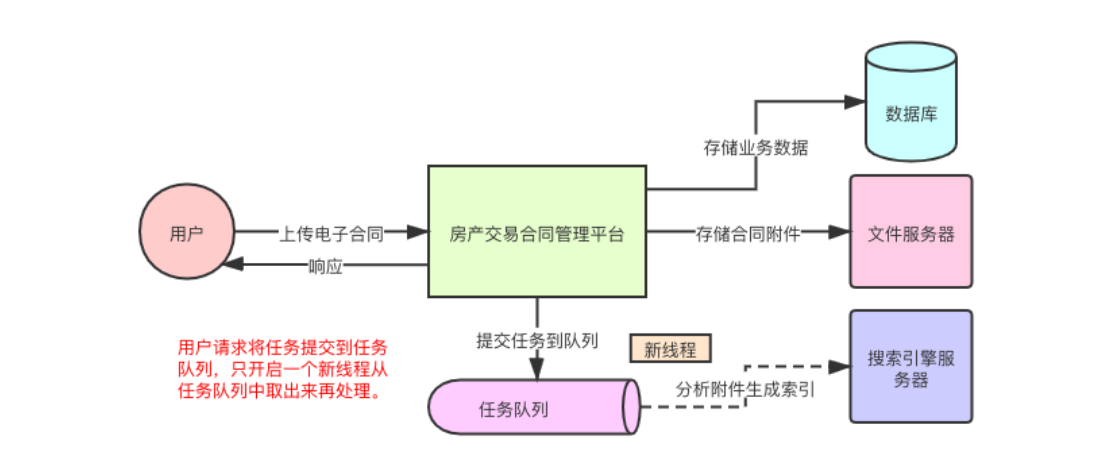
基于这种方式,也就是生产者与消费者方式,就同时实现了业务中的解耦,异步调用,以及控制速率。
异步调用的伪代码
import java.util.concurrent.ArrayBlockingQueue;public class HouseAttachmentAsyncProcessor {private ArrayBlockingQueue<HouseContractFile> blockingQueue;private IndexingThread indexingThread;public HouseAttachmentAsyncProcessor() {blockingQueue = new ArrayBlockingQueue<>(200);indexingThread = new IndexingThread(blockingQueue);indexingThread.start();}public void uploadHouseAttachment(HouseContractFile houseContractFile) {// 存储业务数据saveBizData(houseContractFile);// 存储电子合同附件saveAttachmentFile(houseContractFile);// 提交任务到任务队列putTask(houseContractFile);return;}private void putTask(HouseContractFile houseContractFile) {try {blockingQueue.put(houseContractFile);} catch (Exception e) {e.printStackTrace();}}private void saveAttachmentFile(HouseContractFile houseContractFile) {System.out.println("=====存储电子合同附件完成=====");}private void saveBizData(HouseContractFile houseContractFile) {System.out.println("=====存储业务数据完成=====");}public static void main(String[] args) {long startTime = System.currentTimeMillis();System.out.println("业务处理开始时间:" + startTime);HouseAttachmentAsyncProcessor processor = new HouseAttachmentAsyncProcessor();HouseContractFile houseContractFile = new HouseContractFile();processor.uploadHouseAttachment(houseContractFile);long endTime = System.currentTimeMillis();System.out.println("业务处理完成时间:" + endTime);System.out.println("总耗时时间:" + (endTime - startTime));}}public class IndexingThread extends Thread{private BlockingQueue<HouseContractFile> blockingQueue;public IndexingThread(BlockingQueue<HouseContractFile> blockingQueue) {this.blockingQueue = blockingQueue;}@Overridepublic void run() {try {while (true) {HouseContractFile houseContractFile = blockingQueue.take();// 分析附件并生成索引createIndex(houseContractFile);}} catch (Exception e) {e.printStackTrace();}}private void createIndex(HouseContractFile houseContractFile) {try {Thread.sleep(20000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("=====分析附件并生成索引完成=====");}}###### 执行结果 ######业务处理开始时间:1627133562096=====存储业务数据完成==========存储电子合同附件完成=====业务处理完成时间:1627133562099总耗时时间:3
生产者与消费者模式下的过饱问题
过饱问题
生产者生产任务的速率大于消费者消费任务的速率,在一段时间下,阻塞队列的空间就会被待处理任务所占满。
阻塞队列不能为无界队列,如果无限制的存储任务到队列当中,会造成OOM问题。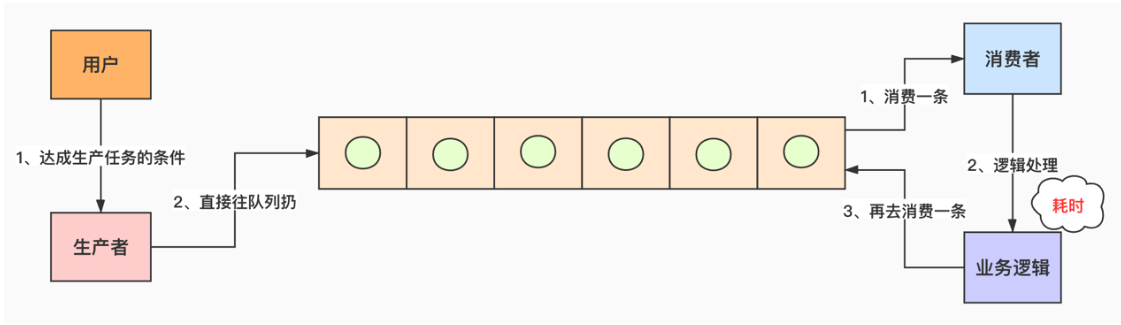
过饱问题解决方案
(1)如果无法对生产者进行限流的话,就只能是增加消费者的消费线程或者增加消费者机器。
(2)如果消费者在完整时间段(比如00:00-23:59)下处理任务的数量是大于生产者在完整时间段生产的任务数量的,那么就可以合理去增大任务队列的大小,保证在生产高峰时不会把队列塞满就行,起到削峰填谷的作用。
(3)如果消费者在完整时间段的消费能力高于生产者在完整时间段的生产能力,但是由于条件限制无法设置较大的任务队列,此时就只能对生产者进行限流,让高峰期塞满队列的速度慢一些。

若有收获,就点个赞吧
0 人点赞
