两种数据丢失的情况
异步复制导致的数据丢失
因为master复制数据至slave节点的过程是异步的,所以在这个复制的过程中,如果master出现宕机,可能就会导致部分在master的数据并未同步到slave节点时,就清空丢失了。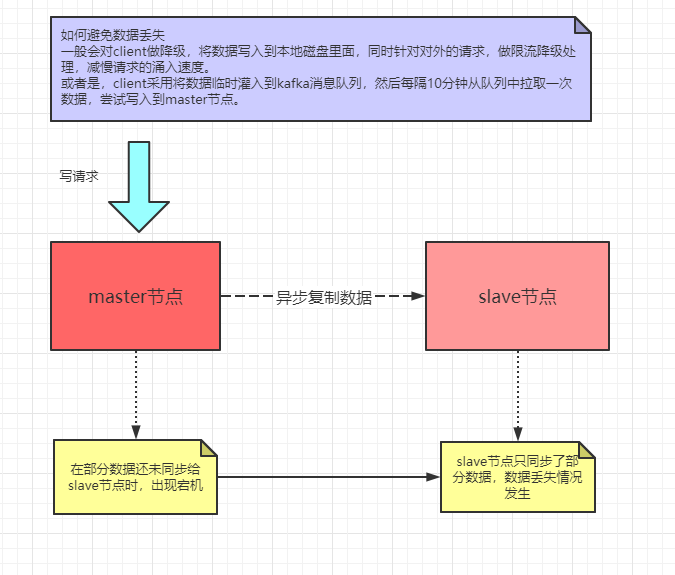
脑裂导致的数据丢失
脑裂现象
master节点与slave节点间的通信,由于网络故障原因,导致salve节点和哨兵集群无法感知master节点的存在,此时就会误判为master节点宕机。重新通过哨兵选举一个新的master节点。此时就有两个master节点,这种现象就是脑裂现象。
如何造成丢失
但是,客户端的写请求却继续写入到旧的master当中。后面,当网络恢复后,旧的master节点会被切换为新的slave节点加入到主备的集群节点当中,在切换的过程当中,会把自己内存的数据全部清空。这就会导致,新写入的数据,也一并清空丢失了。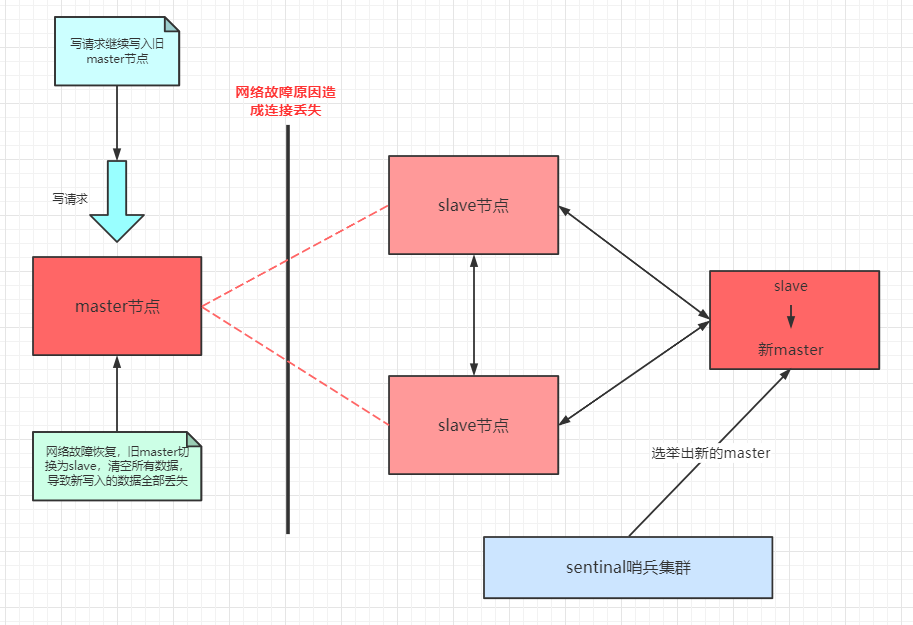
如何解决数据丢失问题
配置两个参数
# 至少保证有3个slave节点,数据复制和同步的延迟不超过10秒# 如果一旦所有的slave,数据复制的延迟超过了10秒钟的情况,master节点就会拒绝所有的写请求# 这两个配置可以减少异步复制和脑裂现象导致的数据丢失min-replicas-to-write 3 # 至少保证3个slave节点同步min-replicas-max-lag 10 # 数据延迟不超过10秒
减少异步复制的数据丢失
有了min-replicas-max-lag这个配置,可以确保,一旦slave复制的数据ack延时太长,就会认为可能master宕机导致数据损失过多,那么就会拒绝写请求。
这样配置,就会可以把控由于master节点宕机导致部分数据未同步后数据丢失的问题。
减少脑裂的数据丢失
min-replicas-to-write和min-replicas-max-lags这两个配置,可以保证,如果master不能继续给指定数据的slave节点同步复制数据,而且slave超过10秒没有给master节点返回ack消息,那么,master节点就会拒绝客户端的写请求。
master拒绝写请求,就能够保证,在脑裂现象发生时,旧的master不会接受任何客户端的新数据,这也就避免了数据丢失。如果master跟任何一个slave丢了连接,在10秒的后发现没有slave给自己返回ack消息,就会拒绝写请求。
因此,在脑裂场景下,最多丢失10秒的数据。

若有收获,就点个赞吧
0 人点赞
