NameServer集群化部署,保证高可用性
首先第一步,要让NameServer集群化部署,建议部署在三台机器上,这样可以充分保证NameServer作为路由中心的可用性,哪怕挂掉两台机器,只要有一个NameServer还在运行,就能保证MQ系统的稳定性。
NameServer的设计是采用Peer-to-Peer的模式来做的,也就是可以集群化部署,但是里面任何一台机器都是独立运行的,跟其他的机器没有任何通信。
每台NameServer实际上都会有完整的集群路由信息,包括所有的Broker节点信息,我们的数据信息等等,所以只要任何一台NameServer存活下来,就可以保证MQ系统的正常运行,不会出现故障。
基于Dledger的Broker主从架构部署
在RocketMQ4.5以前,使用的是Master-Slave架构来部署,能在一定程度上保证数据不丢失,也能保证一定的可用性。但是这种方式的缺陷也明显,最大的问题就是当Master Broker挂了之后,没办法让Slave Broker自动切换为新的Master Broker,需要手动做一些运维操作,修改配置以及重启机器才行,这个非常麻烦。在手工运维的期间,可能会导致系统的不可用。
在RocketMQ4.5以后,已经有基于Dledger技术实现了可以自动让Slave切换为Master的功能,那么我们肯定是选择基于Dledger的主备自动切换的功能来进行生产架构的部署。
Dledger技术是要求至少得是一个Master带有两个Slave,这样有三个Broker组成一个Group,也就是作为一个分组来运行。一旦Master宕机,就可以从剩余的两个Slave中选举出来一个新的Master对外提供服务。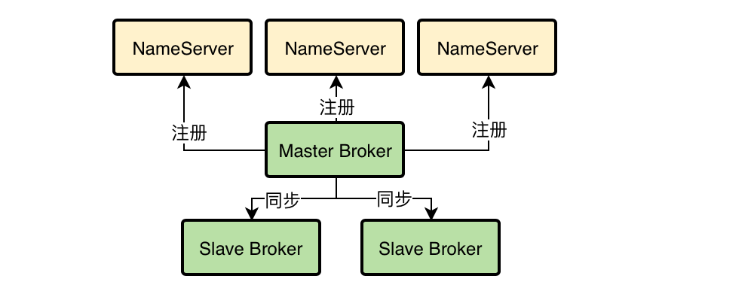
每个Broker(不论是Master和Slave)都会把自己注册到所有的NameServer上去。
然后Master Broker会把数据同步给两个Slave Broker,保证一份数据在不同机器上有多份副本。
Broker是如何跟NameServer进行通信的?
Broker会每隔30秒发送心跳到所有的NameServer上去,然后每个NameServer都会每隔10s检查一次有没有哪个Broker超过120s没有发送心跳。如果有,就认为那个Broker已经宕机了,从路由信息里摘除这个Broker。
Broker跟NameServer之间是通过TCP长连接进行通信的。
也就是,Broker会跟每个NameServer都建立一个TCP长连接,然后定时通过TCP长连接发送心跳请求过去。
所以,各个NameServer就是通过跟Broker建立好的长连接不断收到心跳包,然后定时检查Broker有没有120s都没有发送心跳包,来判断鸡群里各个Broker到底挂掉了没有。
通信的细节图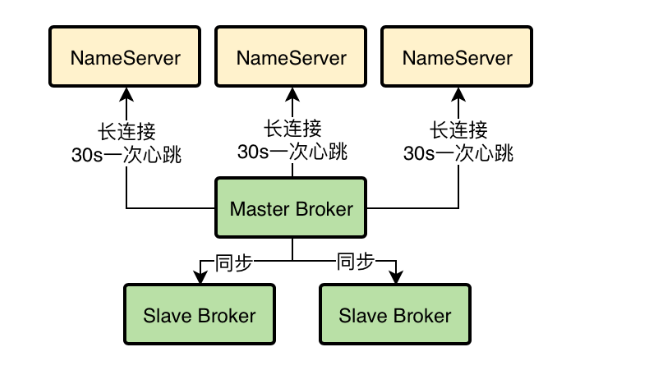
使用MQ的系统都要多机器集群部署
生产者系统:向MQ发送消息的系统。
消费者系统:从MQ获取消息的系统。
无论作为生产者还是消费者的系统,都应该是多机器集群化部署,保证系统本身的高可用性。
因为如果一个系统如果就部署在一台机器上,然后作为生产者向MQ发送消息,那么一旦那天机器上的生产者系统挂了,整个业务流程就断开了,不能保证高可用性。
但是如果在多台机器上部署生产者系统,任何一台机器上的生产者挂了,其他机器上的生产者系统都可以继续运行。
同理,消费者系统也是需要集群化部署的,如果一台机器上的消费者系统挂了,其他机器上的消费者系统应该是可以继续运行的。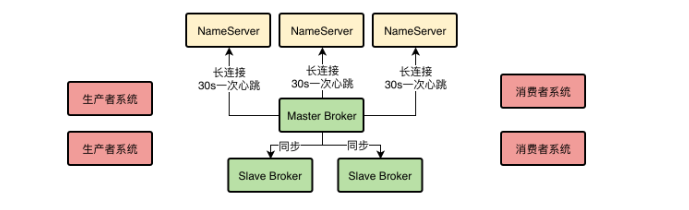
MQ的核心数据模型:Topic
Topic:数据集合。
举个例子,如果订单系统需要王MQ里发送订单消息,那么此时就应该建一个Topic,名字可以叫做 topic_order_info ,也就是一个包含了订单信息的数据集合。
然后你的订单系统投递的订单信息都是进入到这个 topic_order_info 里面去的,如果你的仓储系统要获取订单消息,那么可以指定从 topic_order_info 这里面去获取消息,获取出来的都是他想要的订单消息了。
Topic其实就是一个数据集合的意思,不同类型的数据得放到不同的Topic里去。
所以,如果你的系统要往MQ里写入消息或者获取消息,首先得创建一些Topic,作为数据集合存放不同类型的消息,比如订单Topic,商品Topic等等。
Topic作为一个数据集合是怎么在Broker集群里存储的
分布式存储。
对于一个订单的Topic,可能订单系统每天都会往里面投递几百万条数据,然后这些数据在MQ集群上还得保留很多天,那么最终可能会有几千万的数据量。
对于多个Topic,可能都会有大量的数据,如果针对海量数据本身只存放在一台机器上是不现实的。
所以此时就可以使用分布式存储。针对一个Topic里面的数据,将它们分散存储在多台Broker机器上,比如一个Topic里面有1000万条数据,此时有2台Broker,那么就可以让每台Broker上都放500万条数据。
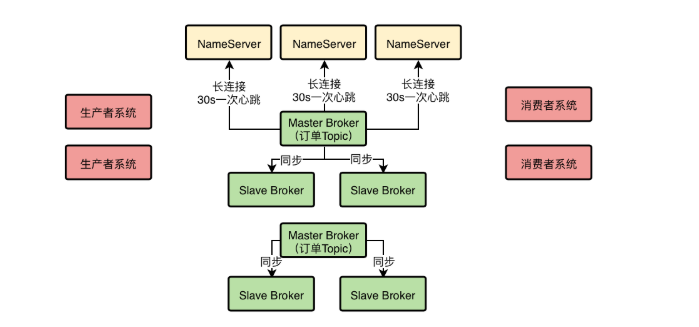
每个Broker在进行定时心跳回包给NameServer的时候,都会告诉NameServer自己当前的数据情况,比如有哪些Topic的哪些数据在自己这里,这些信息都是属于路由信息的一部分。(Broker的心跳,会回包NameServer自己的数据情况,这样每个NameServer都知道集群里有哪些Broker,每个Broker存放了哪些Topic的数据)。
生产者系统是如何将消息发送给Broker的?
(1)首先,在发送消息之前,得先有一个Topic,然后发送消息的时候得指定要发送到哪个Topic里面去。
(2)接着,既然知道要发送的Topic,那么就可以跟NameServer建立一个TCP长连接,然后定时从NameServer那里拉取到最新的路由信息,包括集群里有哪些Broker,集群里有哪些Topic,每个Topic都存储在哪些Broker。
(3)然后,生产者系统自然就可以通过路由信息找到自己要投递消息的Topic分布在哪几台Broker上,此时就根据负载均衡算法,从里面选择一台Broker机器出来,比如round robine轮询算法,或者hash算法等等。最后,选择一台Broker之后,就可以跟那个Broker也建立一个TCP长连接,然后通过长连接向Broker发送消息即可。
(4)Broker收到消息之后就会存储在自己本地磁盘里去。(生产者一定是投递消息到Master Broker,然后Master Broker会同步数据给它的Slave Broker,实现一份数据多份副本,保证Master故障的时候数据不丢失,而且可以自动把Slave切换为Master提供服务。)。
消费者如何从Broker上拉取消息?
(1)首先跟NameServer建立长连接,然后拉取路由信息,知道所要消费的Topic存储在哪些Broker中。
(2)接着就与拥有需要Topic的Broker建立长连接,从里面拉取消息。(消费者拉取消息可能从Master Broker中拉取,也可能从Slave Broker中拉取)。
整体架构:高可用、高并发、海量消息、可伸缩
高可用:NameServer集群部署,Broker基于Dledger算法多集群部署,生产者和消费者系统的多集群部署
高并发:高可用的设计同样可以满足高并发。集群的部署,可以将QPS分散到多台机器上面。比如,订单系统对订单Topic要发起10万QPS的写入,那么只要订单Topic分散在5台Broker上,实际上每个Broker会承载2万QPS写入。
海量消息:数据可以分布式存储在多台Master Broker机器上面。
可伸缩:架构具备伸缩性,如果要抗下更高的并发,存储更多的数据,完全可以在集群里加入更多的Broker机器,这样就可以线性扩展集群了。

若有收获,就点个赞吧
0 人点赞
