重要配置
cluster-enabled <yes/no>cluster-config-file <filename># 指定一个文件,供cluster模式下redis实例存放集群状态,包括集群中其他机器信息,# 比如节点的上下线,故障转移等cluster-node-timeout <milliseconds># 节点存活时长,超过一定时长,认为节点宕机,master宕机会触发主备切换,slave宕机就不会提供服务
配置文件路径
存放redis配置文件: /etc/redis
存放redis持久化文件:/var/redis/6379
存放redis运行日志文件: /var/log/redis
存放redis-cluster集群状态文件: /etc/redis-cluster/
基本配置信息
port <port>cluster-enabled yescluster-config-file /etc/redis-cluster/node-<port>.confcluster-node-timeout 15000daemonize yespidfile /var/run/redis_<port>.piddir /var/redis/7001logfile /var/log/redis/7001.logbind <ip>appendonly yes
配置及启动流程
实例配置及启动
(1)将上面的配置文件,在/etc/redis下存放6个,分别是 7001.conf、7002.conf、7003.conf、7004.conf、7005.conf、7006.conf;
(2)准备启动脚本/etc/init.d,修改启动脚本对应的端口号;
PIDFILE=/var/run/redis_7001.pidCONF="/etc/redis/7001.conf"REDISPORT="7001"
(3)使用启动脚本进行redis-server启动: /etc/init.d/redis_7001 start;
(4)将每个配置文件的slaveof/replicaof配置信息删除;
(5)分别在3台机器上,启动6个redis实例。
集群部署
yum install -y rubyyum install -y rubygemyum install redis# 安装ruby、gem相关依赖cp /usr/local/redis-5.0.8/src/redis-trib.rb /usr/local/bincd /usr/local/binredis-trib.rb create --replicas 1 192.168.0.10:7001 192.168.0.10:7002 192.168.0.11:7003 192.168.0.11:7004 192.168.0.12:7005 192.168.0.12:7006# --replicas 每一个master有几个slave# 6台机器,3个master,3个salveredis-trib.rb check 192.168.0.10# 验证集群搭建情况
部署示例
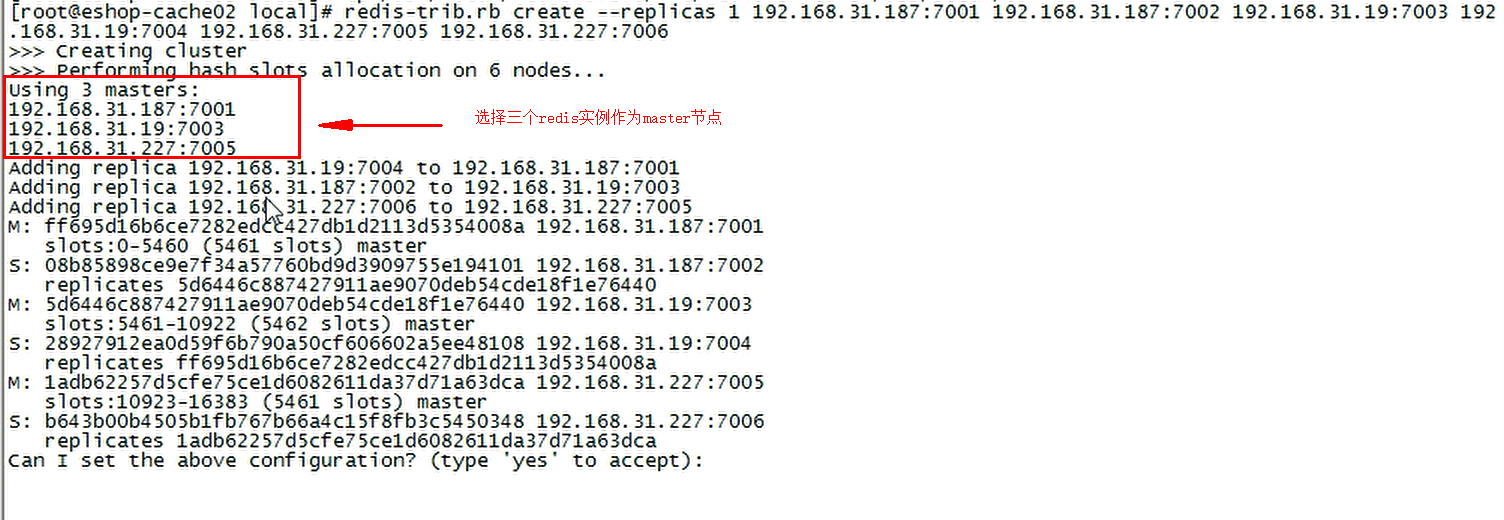
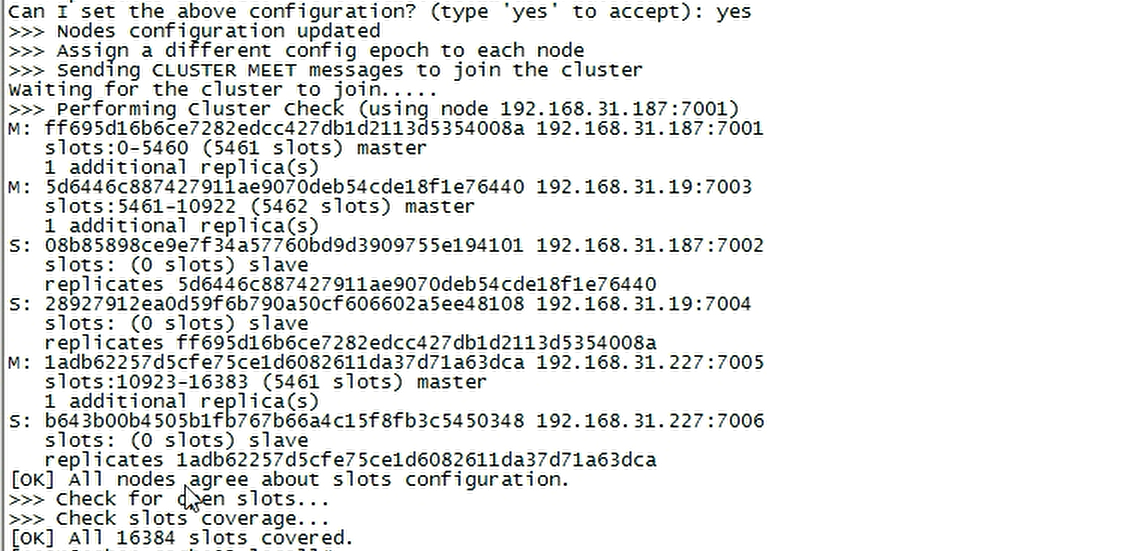
集群实验
redis cluster集群搭建完毕,提供了多个master和多个slave。
master负责数据的写入操作;
slave可以支撑读写分离操作,同时,可以保证在master节点宕机的时候,自动切换为master,实现高可用。
实验多master写入数据
在redis cluster写入数据时,会计算写入数据的key对应的CRC16值,然后对16384个hash slot取模,找到key对应的hash slot,然后也能找到hash slot对应的master。
如果计算出来的hash slot对应的master就在本地的话,set 和 get操作都能正常处理。
如果计算出来的hash slot对应的master不再本地的话,则会返回给客户端一个moved error,告诉需要到哪个master上去u执行set 和 get命令。
可以通过 redis-cli -c实现操作数据的重定向。
实验不同master+slave的读写分离
在redis cluster中,如果要在slave节点读取数据,需要先执行readonly指令,然后再进行get操作。
> readonly> get key1
redis cluster实现的每个master挂载多个slave的操作,主要是为了实现集群节点的高可用,保证如果master节点出现故障,可以进行主备切换。
针对读写分离的支持并不友好。读写分离的本质是为了建立一主多从的架构,然后能够横向扩展slave节点去支撑更大的读吞吐量。在redis cluster架构下,本身是可以针对master进行任意扩展的,如果要支撑更大的读写吞吐量,可以直接针对master进行横向扩容。
实验自动故障的主备切换
使用kill -9命令杀掉其中一个master节点的进程,然后观察对应的slave节点是否切换为master
redis-trib.rb check 192.168.0.10:7001
查看slave节点192.168.0.11:7004的运行日志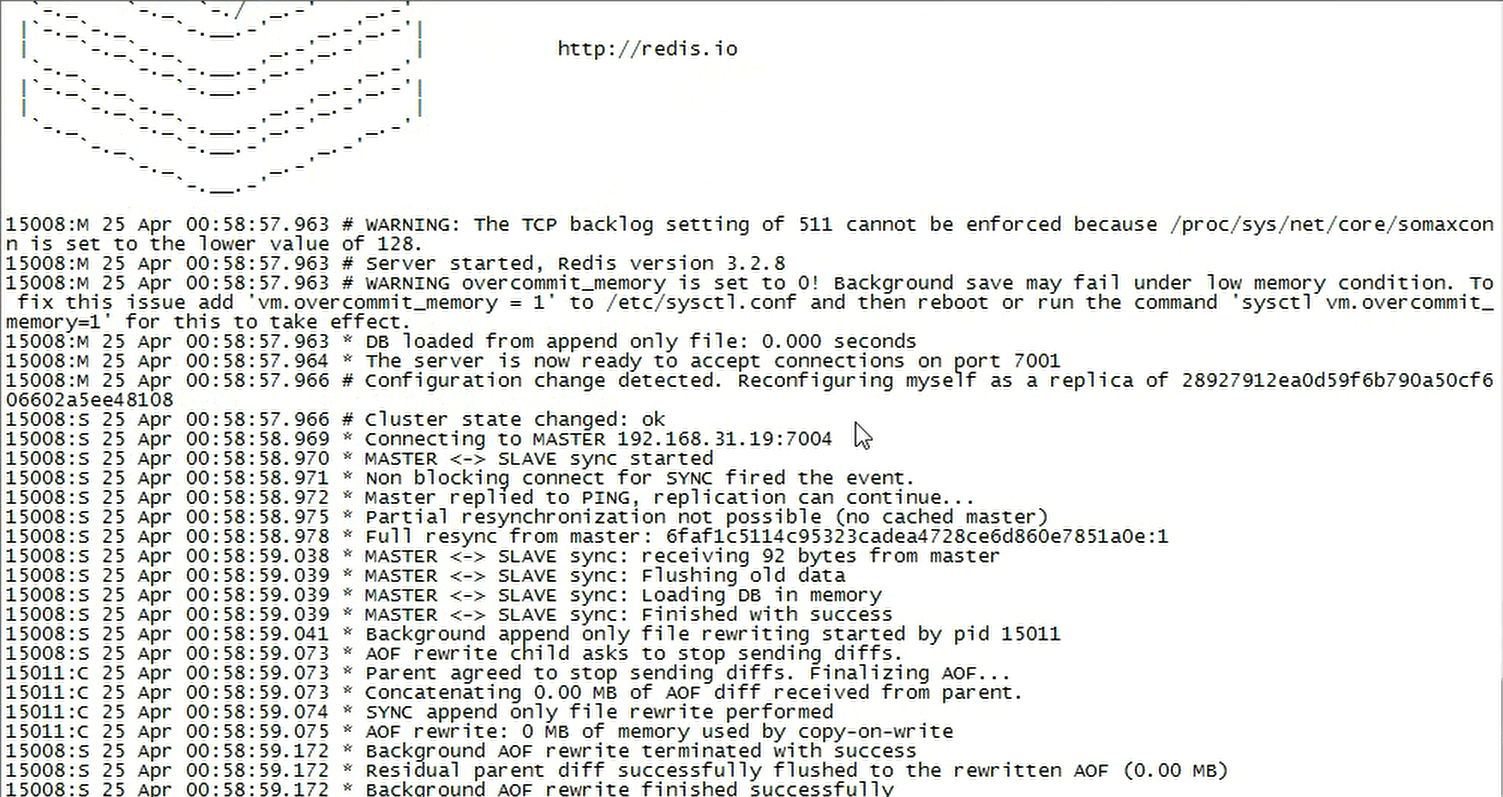
日志中记录了slave节点切换为master节点的过程,切换完毕后,会基本aof进行数据的rewrite操作。
旧master节点重新启动,会自动作为slave节点挂载到新的master节点192.168.0.11:7004上面去。
Master节点扩容
(1)配置redis.conf(7007.conf)
port 7007cluster-enabled yescluster-config-file /etc/redis-cluster/node-7007.confcluster-node-timeout 15000daemonize yespidfile /var/run/redis_7007.piddir /var/redis/7007logfile /var/log/redis/7007.logbind 192.168.0.11appendonly yes
(2)配置redis_7007启动脚本
(3)手动启动一个新的redis实例,并加入到cluster集群
# 添加节点redis-trib.rb add-node 192.168.0.12:7007 192.168.0.10:7001# 确认节点是否加入到集群redis-trib.rb check 192.168.31.187:7001
(4)reshard移动一些hash slot数据到新节点
redis-trib.rb reshard 192.168.0.10:7001 # master节点redis-trib.rb reshard 192.168.0.11:7003 # master节点redis-trib.rb reshard 192.168.0.12:7005 # master节点# How many slots do you want to move (from 1 to 16384)?# 1000
(5)添加新节点作为slave
mkdir -p /var/redis/7008=== 7008.conf====port 7008cluster-enabled yescluster-config-file /etc/redis-cluster/node-7008.confcluster-node-timeout 15000daemonize yespidfile /var/run/redis_7008.piddir /var/redis/7008logfile /var/log/redis/7008.logbind 192.168.0.12appendonly yes=== 7008.conf====# 添加新节点作为slaveredis-trib.rb add-node --slave --master-id <master-id> 192.168.0.12:7008 192.168.0.10:7001# 检验是否添加成功redis-trib.rb check 192.168.31.187:7001
删除集群节点
(1)先用reshard将hash slot数据移到其他节点,确保节点数据为空后,才进行删除节点操作;
(2)当清空一个master的hashslot后,redis cluster会自动将slave挂载到其他的master节点上;
(3)删除master节点。
redis-trib.rb del-node 192.168.0.10:7001 <master-id>
Slave节点自动迁移
redis cluster集群中,存在一个master节点有多个slave节点,即master节点出现了slave冗余。
如果此时某个master的slave节点挂了,那么redis cluster会自动迁移一个冗余的slave节点给那个master节点。
保证在如果这个master节点宕机后,仍然有可用的slave节点可以做主备切换,保证其高可用性。
可以通过 redis-trib.rb check 192.168.9.10:7001进行检查。
具体查看下slave节点做自动迁移的日志信息打印

若有收获,就点个赞吧
0 人点赞
