谈谈一致性
强一致性
要求系统写入什么,读出来的就会是什么。
对于用户来说体验良好,但是会极大影响系统性能。
弱一致性
数据在写入系统成功之后,不一定能够立即督导写入的值,同时也无法保证到多久之后,数据才能达到一致。
但会竟可能地保证到某一个时间级别(比如秒级别)后,数据能够达到一致性的状态。
最终一致性
最终一致性是弱一致性的特例。系统会保证在一定时间内,能够达到数据一致的状态。
最终一致性是弱一致性中非常推崇的一种一致性模型,也是业界大型分布式系统的数据一致性上推崇的模型。
三个经典的缓存模式
Cache-Aside Pattern
旁路缓存模式。该模式是为了尽可能地解决缓存与数据库的数据不一致问题。
Cache-Aside读流程
先读缓存,如果缓存中找不到对应的数据,再读数据库,再将数据写入缓存。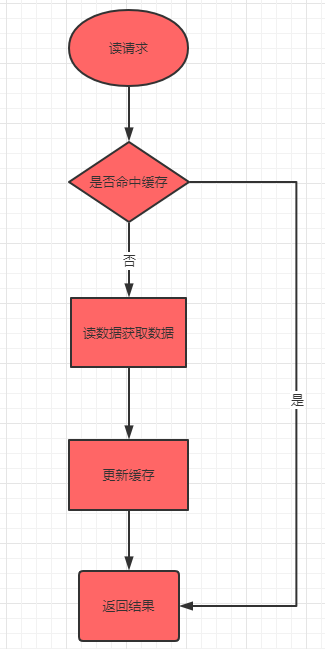
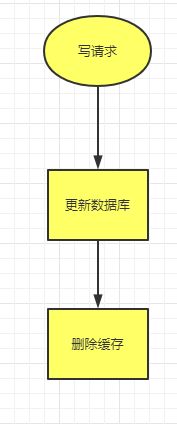
Cache-Aside写流程
更新数据库相关数据,同时删除缓存,等待下一次读数据时,再通过懒加载的方式,从数据库中更新缓存。
Read-Through/Write-Through(读写穿透)
数据库缓存双写时,为什么是删除缓存,不是更新缓存
容易因为网络原因造成数据库与缓存的不一致
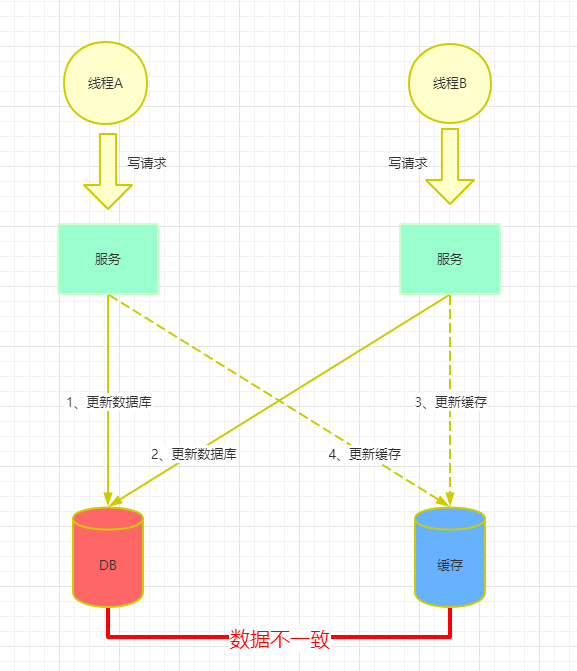
错误流程
(1)A线程发起写操作请求,更新数据库中的数据。
(2)B线程发起写操作请求,更新数据库中的数据。
(3)由于网络原因,B线程比A线程先更新了缓存。
(4)线程A更新了缓存。
—> 数据库与缓存中的数据出现了不一致。(缓存保存了线程A的旧数据,数据库保存了线程B的新数据)
正确流程
(1)A线程发起写操作请求,更新数据库中的数据。
(2)B线程发起写操作请求,更新数据库中的数据。
(3)线程A更新了缓存。
(4)线程B更新了缓存。
—> 数据库与缓存中的数据保持一致。
更新缓存成本代价过高
(1)对一个缓存的更新,并不一定是简单的从一张表里面获取字段后,存储到缓存当中的。往往一个缓存值,可能需要经过多表查询相关字段和经过大量复杂的计算才能获得到。
比如更新人员表某个用户的age字段,对应的缓存为某个地区男性的平均年龄,此时,对应的缓存就需要涉及到地区表,人员表,然后筛选男性,经过复杂的计算之后,平均年龄的数据才会计算出来,然后更新至缓存。 所以,就有了 简单的更新数据表字段值,但是却需要多表关联与复杂的计算才能更新对应的缓存值。
(2)一个缓存的更新,并不一定代表它就是热点数据,会被频繁地访问到。如果每一次的写操作,伴随的都是缓存的更新,但是更新后的缓存,在1分钟,10分钟内被访问的次数只有1到10次,那更新了缓存的最新值意义并不大。频繁更新缓存极大影响开销,但是获得的结果却不尽人意。
(3)所以,redis aside pattern使用了懒加载的思想,只有当真正要访问到缓存时,再从数据库中获取数据,然后经过复杂的计算后,在将最新的缓存值存入redis当中。
数据库与缓存双写的情况下,为什么先更新数据库,再删除缓存
比如有两个线程A,B,A线程对数据发起写请求,B线程对数据发起读请求。
如果此时是先删除缓存,再更新数据库的情况下,会执行如下流程
(1)线程A发起写请求,删除缓存;
(2)线程B发起读请求,首先读取缓存,缓存未命中;
(3)线程B查询数据库,将数据库的旧值获取到,并更新到缓存中;
(4)线程A更新数据库中的数据,数据变为新值。
—-> 数据库与缓存中的数据出现了不一致。(缓存存储的是线程B的旧值,数据库存储的是线程A的新值)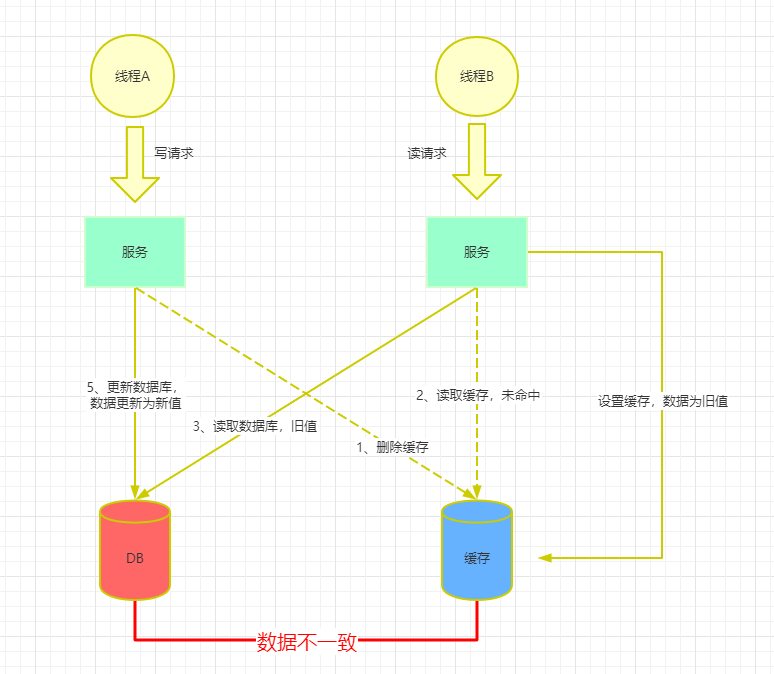

若有收获,就点个赞吧
0 人点赞
