先回顾RocketMQ的架构原理
- NameServer —— 负责管理集群里所有的Broker信息,让使用MQ的系统可以通过NameServer感知到集群里有哪些Broker。
- Broker —— 必须得在多台机器上部署一个集群,而且得从主从架构实现数据多副本存储和高可用。
- 消息生产者系统 —— 向MQ发送消息。
- 消息消费者系统 —— 从MQ获取消息。
NameServer部署机器原则
NameServer部署需要保证其高可用性,防止一台NameServer机器宕机之后导致所有的RocketMQ集群出现故障——无法通过NameServer知道集群里的Broker机器的信息。所以NameServer一定要多机器部署,实现一个集群,起到高可用的效果,保证任何一台机器宕机,其他机器的NameServer可以继续对外提供服务。
Broker注册到NameServer
集群里面的每个Broker在启动后都需要向所有的NameServer进行注册。也就是每个NameServer都会有一份集群里所有的Broker信息。
这样才能保证如果某个NameServer出现宕机之后,还有另外一个NameServer可以保证能够得到所有的Broker信息。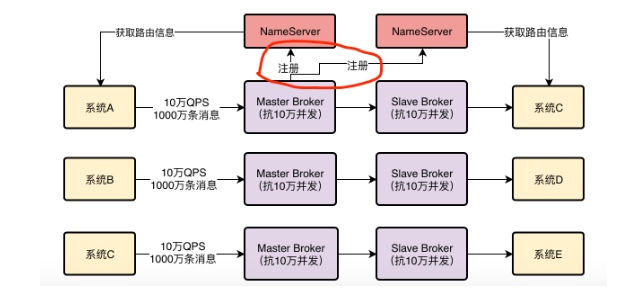
系统如何从NameServer获取Broker信息
每个系统自己会每隔一段时间,定时发送请求到NameServer去拉取最新的集群Broker信息。
所以,RocketMQ中的生产者和消费者,就是 自己主动去NameServer拉取Broker信息的。
路由信息:可以理解为集群里的Broker信息以及其他相关的数据信息(Topic等)。
通过这些路由信息,每隔系统就能知道发送消息或者获取消息去哪台Broker上去进行了,这起到一个把消息路由到Broker上的效果,所以一般把这种信息叫做路由信息。
NameServer的心跳机制和故障感知机制
每个Broker启动之后都会向NameServer注册,每个NameServer都知道集群里又这么一台Broker的存在,然后各个系统从NameServer里拉取到Broker信息,也知道了集群里又这么一台Broker。
心跳机制:每一台注册到NameServer的Broker,会定时(每隔30s)向所有的NameServer发送心跳,告诉每个NameServer自己目前还活着。每一个NameServer收到一个Broker的心跳,就可以更新一下他的最近一次心跳的时间。
故障感知机制:然后NameServer会每隔10s运行一个任务,去检查一下各个Broker的最近一次心跳时间,如果某个Broker超过120s都没有发送心跳了,那么就认为Broker已经挂掉了。
如果Broker挂掉了,作为生产者和消费者怎么感知
以生产者为例,生产者一开始并不能感知到哪个Broker已经宕机了,虽然在NameServer里已经感知到了哪个Broker出现了故障。那此时,假设生产者系统发送消息给已经故障的Broker,那其实发送消息的结果就是失败的,但是该Broker有对应的Slave机器作为备份,此时可以考虑等会去跟它的Slave机器进行通信。
生产者本身也有一套容错机制,即使一下子没有感知到某个Broker挂了,他也可以有别的方案去应对。然后再一段时间过后,生产者会重新从NameServer里拉取最新的路由信息,此时生产者就能知道哪一个Broker宕机了。
总结
NameServer的集群部署
Broker会注册到所有的NameServer机器上
30s的心跳机制和120s的故障感知机制
生产者和消费者的客户端容错机制

若有收获,就点个赞吧
0 人点赞
