CPU 高速缓存
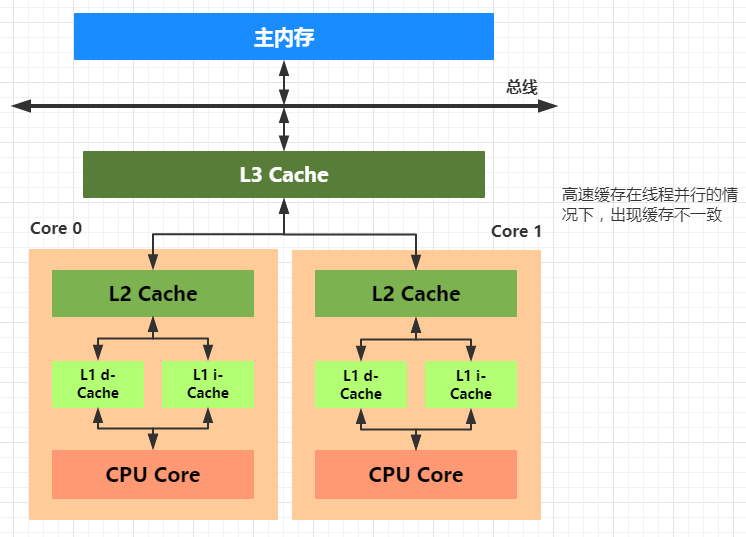
线程是 CPU 调度的最小单元,线程涉及的目的最终仍然是更充分的利用计算机处理的效能,但是绝大部分的运算任务不能只依靠处理器“计算”就能完成,处理器还需要与内存交互,比如读取运算数据、存储运算结果,这个 I/O 操作是很难消除的。而由于计算机的存储设备与处理器的运算速度差距非常大,所以现代计算机系统都会增加一层读写速度尽可能接近处理器运算速度的高速缓存来作为内存和处理器之间的缓冲:将运算需要使用的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步到内存之中。
高速缓存从下到上越接近 CPU 速度越快,同时容量也越小。现在大部分的处理器都有二级或者三级缓存,从下到上依次为 L3 cache,L2 cache,L1 cache。 L1 cache 缓存又可以分为指令缓存和数据缓存,指令缓存用来缓存程序的代码,数据缓存用来缓存程序的数据。
L1 Cache,一级缓存,本地 core 的缓存,分成 32K 的数据缓存 L1d 和 32k 指令缓存 L1i,访问 L1 需要 3cycles,耗时大约 1ns。
L2 Cache,二级缓存,本地 core 的缓存,被设计为 L1 缓存与共享的 L3 缓存之间的缓冲,大小为 256K,访问 L2 需要 12cycles,耗时大约 3ns。
L3 Cache,三级缓存,在同插槽的所有 core 共享 L3 缓存,分为多个 2M 的段,访问 L3 需要 38cycles,耗时大约 12ns。
缓存一致性问题
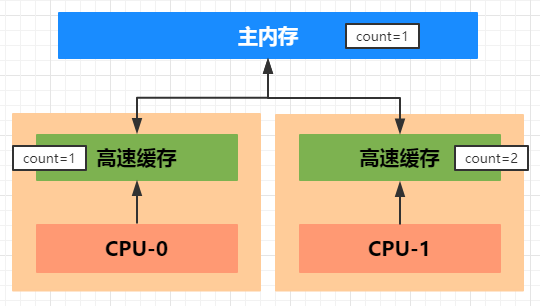
CPU 高速缓存的引入导致了缓存一致性问题,CPU-0 读取主存的数据,缓存到 CPU-0 的高速缓存中,CPU-1 也做了同样的事情,而 CPU-1 把 count 的值修改成了 2,并且同步到 CPU-1 的高速缓存,但是这个修改以后的值并没有写入到主存中,CPU-0 访问该字节,由于缓存没有更新,所以仍然是之前的值,就会导致数据不一致的问题引发这个问题的原因是因为多核心 CPU 情况下存在指令并行执行,而各个 CPU 核心之间的数据不共享从而导致缓存一致性问题,为了解决这个问题,CPU 生产厂商提供了相应的解决方案。
总线锁
当一个 CPU 对其缓存中的数据进行操作的时候,往总线中发送一个 Lock 信号。其他处理器的请求将会被阻塞,那么该处理器可以独占共享内存。总线锁相当于把 CPU 和内存之间的通信锁住了,所以这种方式会导致 CPU 的性能下降,所以 P6 系列以后的处理器,出现了另外一种方式,就是缓存锁。
缓存锁
如果缓存在处理器缓存行中的内存区域在 LOCK 操作期间被锁定,当它执行锁操作回写内存时,处理不在总线上声明 LOCK 信号,而是修改内部的缓存地址,然后通过缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域的数据,当其他处理器回写已经被锁定的缓存行的数据时会导致该缓存行无效。所以如果声明了 CPU 的锁机制,会生成一个 LOCK 指令,**会产生两个作用**
- Lock 前缀指令会引起引起处理器缓存回写到内存,在 P6 以后的处理器中,LOCK 信号一般不锁总线,而是锁缓存
- 一个处理器的缓存回写到内存会导致其他处理器的缓存无效
缓存一致性协议(MESI)
处理器上有一套完整的协议,来保证 Cache 的一致性,比较经典的应该就是 MESI 协议了,它的方法是在 CPU 缓存中保存一个标记位,这个标记为有四种状态
- M(Modified):修改缓存,当前 CPU 缓存已经被修改,表示已经和内存中的数据不一致了
- I(Invalid):失效缓存,说明 CPU 的缓存已经不能使用了
- E(Exclusive):独占缓存,当前 CPU 的缓存和内存中数据保持一直,而且其他处理器没有缓存该数据
- S(Shared):共享缓存,数据和内存中数据一致,并且该数据存在多个 CPU 缓存中
嗅探(snooping)协议:每个 Core 的 Cache 控制器不仅知道自己的读写操作,也监听其它核心 Cache 的读写操作。
CPU 的读取会遵循几个原则:
- 如果缓存的状态是 I,那么就从内存中读取,否则直接从缓存读取
- 如果缓存处于 M 或者 E 的 CPU 嗅探到其他 CPU 有读的操作,就把自己的缓存写入到内存,并把自己的状态设置为 S
- 只有缓存状态是 M 或 E 的时候,CPU 才可以修改缓存中的数据,修改后,缓存状态变为 M
CPU 的优化执行
除了增加高速缓存以为,为了更充分利用处理器内部的运算单元,处理器可能会对输入的代码进行乱序执行(Out-Of-OrderExecution)优化,处理器会在计算之后将对乱序执行的代码进行结果重组,保证该结果与顺序执行的结果一致,但并不保证程序中各个语句执行的先后顺序与输入代码中的顺序一致,这个是处理器的优化执行;还有一个就是编程语言的编译器也会有类似的优化,比如做指令重排来提升性能。
总结
线程的原子性、可见性、有序性问题,是我们抽象出来的概念,他们的核心本质就是刚刚提到的缓存一致性问题、处理器优化执行问题。
比如缓存一致性问题会导致可见性问题,处理器的乱序执行优化会导致原子性、有序性问题,为了解决这些问题,所以在 JVM 中引入了 JMM 的概念。
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/tbfmhv 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
