| 表空间 |
|---|
| 内部有多个段对象(Segment)组成 |
| 每个段(Segment)由区(Extent)组成 |
| 每个区(Extent)由页(Page)组成 |
| 每个页里面报存数据(或者叫记录 Row) |

表空间 - 段
- 段对用户来说是透明的
- 段也是一个逻辑概念
- 目前为止在 information_schema 中无法找到段的概念
- 重点需要理解区(Extent)和页(Page)的概念
表空间 - 区
- 区是最小的空间申请单位
- 比如共享表空间,初始化的时候会分配 12M 的大小,随着数据量的增加,表空间会以区的大小申请空间
- 区的大小固定为 1M
- 如果 page_size = 16K,1M * 1024 / 16 = 64,那么 1M 就对应 64 页
- 同理 page_size = 8K 就是 128 个页
- 同理 page_size = 4K 就是 256 个页
- 通常说来,一次申请4个区(4M)的大小(存在一次申请5个区的时候,但是绝大部分情况就是申请4个区)
- 单个区的 1M 空间内,物理上是连续的(一次申请的4个区的空间之间(1M 和 1M 之间)不保证连续)
表空间 - 页
页的定义
- 页是最小的 I/O 操作单位
- data 的最小单位不是页,而是页中的记录(row)
- 普通用户表中 MySQL 默认的每个页为 16K
- 从 MySQL 5.6 开始使用 innodb_page_size 可以控制页大小(模板中设置为 8K)
- 一旦数据库通过 innodb_page_size 创建完成,则后续无法更改
- innodb_page_size 是针对普通表的,压缩表不受其限制
页的结构

File Header
| 名称 | 大小(Bytes) | 备注 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | |
| FIL_PAGE_OFFSET | 4 | |
| FIL_PAGE_PREV | 4 | page_number(前一个) |
| FIL_PAGE_NEXT | 4 | page_number(后一个) |
| FIL_PAGE_LSN | 8 | |
| FIL_PAGE_TYPE | 2 | |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 |
如何定位到页
- SpaceID
- 每个表空间都对应一个 SpaceID,而表空间又对应一个 ibd 文件,那么一个 ibd 文件也对应一个 SpaceID
- 每创建一个表空间(ibd 文件),SpaceID 自增长(全局)
- PageNumber
- 在一个表空间中,第几个 16K 的页(假设 innodb_page_size = 16K)即为 PageNumber

- 可以通过(SpaceID,PageNumber)定位到某一个页
- 在一个 SpaceID(ibd文件)中,PageNumber 是唯一且自增的
- 这里的区(extent)的概念已经弱化。在这个例子中,第一个区的 PageNumber是(0~63)且这64个页在物理上是连续的;第二个区的 PageNumber 是(64~127)且这64个页在物理上也是连续的;但是(0~63)和(64~127)之间在物理上则不一定是连续的,因为区和区之间在物理上不一定是连续的。
- 删除表的时候,SpaceID 不会回收,SpaceID 是全局自增长的
如何获取 SpaceID
从元数据表中获取 SpaceID。
mysql> select * from information_schema.innodb_sys_tables limit 1\G -- INNODB_SYS_TABLES 表*************************** 1. row ***************************TABLE_ID: 14NAME: SYS_DATAFILESFLAG: 0N_COLS: 5SPACE: 0 -- 这个就是SpaceID,由于这个表存放在ibdata1中,所以SpaceID是0FILE_FORMAT: AntelopeROW_FORMAT: RedundantZIP_PAGE_SIZE: 0SPACE_TYPE: System1 row in set (0.00 sec)mysql> select name, space, table_id from information_schema.innodb_sys_tables where space=0;+------------------+-------+----------+| name | space | table_id |+------------------+-------+----------+| SYS_DATAFILES | 0 | 14 || SYS_FOREIGN | 0 | 11 || SYS_FOREIGN_COLS | 0 | 12 || SYS_TABLESPACES | 0 | 13 || SYS_VIRTUAL | 0 | 15 |+------------------+-------+----------+5 rows in set (0.00 sec)mysql> select name, space, table_id from information_schema.innodb_sys_tables where space<>0 limit 5;+---------------------+-------+----------+| name | space | table_id |+---------------------+-------+----------+| burn_test/Orders | 77 | 89 || burn_test/Orders_MV | 79 | 91 || burn_test/child | 37 | 52 || burn_test/parent | 33 | 49 || burn_test/t1 | 58 | 78 |+---------------------+-------+----------+5 rows in set (0.00 sec)
- 独立表空间的 table_id 和 SpaceID 一一对应
- 共享表空间是多个 table_id 对应 一个 SpaceID
表空间 - 行记录
这篇博客(InnoDB — 行记录格式)写的很详细,大家可以进去看看。
用户的记录保存在数据页中,它在物理存储上有一定的格式,在创建表时可以通过 ROW_FORMAT 选项决定。不同的行记录格式,是可以影响数据操作性能的。
行格式分类
行格式分为如下几类:

InnoDB 早期的文件格式(页格式)为 Antelope,定义了两种行记录格式,分别是 Compact 和 Redundant。Barracuda 兼容 Antelope,支持所有 InnoDB 行记录格式,包括两种新定义的行记录格式 Compressed 和 Dynamic。
- REDUDENT:兼容老版本的 InnoDB,MySQL 4.1 版本之前。
- COMPACT:MySQL 5.6 版本的默认格式。
- COMPRESSED:支持压缩。
- DYNAMIC:MySQL 5.7 版本默认格式,优化大对象记录。
- 至于怎么优化大对象记录,参考上面博客中行溢出。
通过变量 innodb_file_format 和 innodb_default_row_format 可以设置默认的文件格式和行记录格式。
mysql> SHOW VARIABLES LIKE 'innodb_file_format';+--------------------+-----------+| Variable_name | Value |+--------------------+-----------+| innodb_file_format | Barracuda |+--------------------+-----------+1 row in set (0.00 sec)mysql> SHOW VARIABLES LIKE '%row%format%';+---------------------------+---------+| Variable_name | Value |+---------------------------+---------+| innodb_default_row_format | dynamic |+---------------------------+---------+1 row in set (0.38 sec)
CHAR 类型
多字节字符集
char(n) 中的 n 表示的是字符,在多字节字符集下,比如数据表使用的是 UTF8mb4 字符集,而 UTF8mb4 字符集会使用 1 ~ 4 个字节表示字符数据(英文字符使用1个字节,一些特殊的表情符号使用4个字节),这就意味着 char 类型的字段也变成了一个变长字段,会存放 n ~ 4n 个字节。
这样我们就有一个疑问了:对于 char(10) 字段,我插入一条数据 “aa”,我是填8个20,还是38个20?
当存储数据的长度 M ,未达到 N 时,则填充空格(0x20),且空格的长度取最小的长度 N-M,而不是 4N-M。
注意:char 数据类型本来是定长数据,但是在多字节字符集下,表现的行为和 varchar 类似,失去了原来的优势,当数据更新变长后可能无法原地更新。
原地更新
假设 16K 的页,有一行数据 row1,四个字段(c1,c2,c3,c4),假设 c3 列是 char(10),更新 c3 这个字段,更新后 c3 列还是 char(10),那么这行数据在页中的位置就不需要改变,原地更新即可。
如果 c3 列是 varchar(10),更新 c3 这个字段,从5个字节到10个字节,这个时候在原地就更新不了这列,这个时候只能把 row1 删掉,在当前页的空闲空间中再插入新的 row1,这就不叫原地更新了。
原地更新的特点:
- 原地更新不会占用新的存储空间。
- 非原地更新需要删除(物理删除)原来的空间的数据,然后将更新后的数据插入到页的后面。
- 删除的数据的空间,会插入到 Free_List 链表的头部。
- 原地更新不会触发页的分裂,减少页的分裂次数。
Free_List 是将页中被删除的空间串联在一起(组成一个链表),当有数据被插到页内时,先看一下 Free_List 中第一个空间的大小,如果空间合适,就将该记录插入到第一个空间中去,如果不合适,直接插入到页的尾部的剩余空间( 不会去看 Free_List 的第二个空间)。
当该页的数据被插满了,不会马上进行分页,而是进行 reorganize 操作,即将页内的数据在内存中进行整理,然后覆盖原来的页(不影响性能),所以 InnoDB 不需要碎片整理。
COMPACT
这篇博客(MySQL原理 - InnoDB引擎 - 行记录存储 - Compact 行格式)写的很详细,大家可以进去看看。
格式
| 变长字段 长度列表 |
NULL 标志位 | 记录头信息 | ROWID | Transaction ID | Roll Pointer | 列1 | …… | 列 n |
|---|---|---|---|---|---|---|---|---|
- 变长字段长度列表
- 存储的条件:列的字段类型是 varchar,varbinary,text 等,或者是变长编码(如 UTF8)下的 char 类型。
- 存储的顺序:逆序显示。
- 存储的内容:变长字段的长度数据,比如有一列是 varchar 类型,且存储的内容是 “aa”,会使用 1byte 存储当前变长字段的长度(02)。
- NULL 标志位:标记行记录中是否有 NULL 值,是一个位向量。
- NULL 标志位占几个字节,参考:InnoDB 物理行中 null 值的存储的推断与验证,初始值占一个字节,会随着 NULL 列的增加而增加。
- 说明当行记录中的数据为 NULL 时,不会为该列设置一个 NULL 值,只是用一个标志位标记一下该列是否为 NULL 值。
- 记录头信息:5个字节,比较底层(比如看该记录有没有被删除)
- ROWID:B+Tree 索引键值。
- Transaction ID:事物 ID,6个字节。
- Roll Pointer:回滚指针,7个字节。
记录头信息:
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否已被删除 |
| min_rec_flag | 1 | 如果该行记录是预定义为最小的记录,为1 |
| n_owned | 4 | 该记录拥有的记录数,用于Slot |
| heap_no | 13 | 索引堆中该条记录的索引号 |
| record_type | 3 | 记录类型,000(普通),001(B+Tree 节点指针),010(Infimum),011(Supremum) |
| next_record | 16 | 页中下一条记录的相对位置 |
| Total | 40(5 Byte) |
关注一下 heap_no,它记录的是页中每行记录插入的顺序序号,是物理上的,更新操作对 heap_no 没有影响。
假设顺序插入的行记录是 rowa、rowb、rowc、rowd、rowe,则对应的 heap_no 是 2,3,4,5,6。
0 和 1 被 infimum 和 supermum 使用了:
- infimum:对应最小的 heap_no。
- supermum:对应最大的 heap_number,随着数据的插入,该值会更新。
一般我们在分析 show engine innodb status 信息的时候会遇到 heap_no,heap_no 被用来标记页中的哪条记录。
-- 终端1mysql> create table test_heap(a int primary key);Query OK, 0 rows affected (0.13 sec)mysql> insert into test_heap values (1); -- 插入a=1的记录Query OK, 1 row affected (0.03 sec)mysql> begin; -- 开启事物Query OK, 0 rows affected (0.00 sec)mysql> delete from test_heap where a=1; -- 删除a=1的记录,此时加上了锁Query OK, 1 row affected (0.00 sec)-- 终端2mysql>mysql> show variables like "%innodb_status_output_locks%";+----------------------------+-------+| Variable_name | Value |+----------------------------+-------+| innodb_status_output_locks | OFF |+----------------------------+-------+mysql> set global innodb_status_output_locks=1;Query OK, 0 rows affected (0.00 sec)mysql> pager less -- 使用类似linux中的less命令方式进行查看,可上下翻页PAGER set to 'less'mysql> show engine innodb status\G-- -----------省略其他输出-------------TABLE LOCK table `burn_test`.`test_heap` trx id 16943 lock mode IXRECORD LOCKS space id 122 page no 3 n bits 72 index PRIMARY of table `burn_test`.`test_heap` trx id 16943 lock_mode X locks rec but not gapRecord lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 320: len 4; hex 80000001; asc ;; -- 插入的主键a=1,8的二进制1000,最高位为1,表示有符号的1: len 6; hex 00000000422f; asc B/;; -- 0x422f的 十进制就是16943 ,表示事物id(trx id)2: len 7; hex 2c000000450dcf; asc , E ;; -- roll pointer(回滚指针)-- -----------省略其他输出--------------- space id 122 : 表空间id是122-- page no 3 : 对应的页号是3(表示第4个页,是root页)-- heap no 2 : heap number是2(表示是新插入的第一条记录)-- heap no = 1 的一种情况-- 终端1mysql> rollback;Query OK, 0 rows affected (0.00 sec)mysql> set tx_isolation='repeatable-read';Query OK, 0 rows affected (0.00 sec)mysql> select * from test_heap where a>1 for update;Empty set (0.00 sec)-- 终端2mysql> show engine innodb status\G-- -----------省略其他输出-------------Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 00: len 8; hex 73757072656d756d; asc supremum;; -- 一条伪记录Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 00: len 4; hex 80000001; asc ;;1: len 6; hex 00000000422e; asc B.;;2: len 7; hex ab000000470110; asc G ;;-- -----------省略其他输出-------------
示例
创建 mytest 表,格式为 compact,且没有显示定义主键和非空唯一键,故使用系统定义的 ROWID,并插入三条记录。
create table mytest (t1 varchar(10),t2 varchar(10),t3 char(10),t4 varchar(10)) engine=innodb charset=latin1 row_format=compact;insert into mytest values ('a','bb','bb','ccc');insert into mytest values ('d','ee','ee','fff');insert into mytest values ('d',NULL,NULL,'fff');
将 mytest 表结构进行 dump,图中红色部分对应第一条记录,黄色部分对应第二条记录,深蓝色部分对应第三条记录。
将红色部分对应的第一条记录进行解析
- 变长字段长度列表:03 02 01,表示有三个变长字段,且逆序存放(为了提高 CPU 的 cache 的命中率)
- 列 t1 长度为1
- 列 t2 长度为2
- 列 t3 在 LATIN1 单字节编码下长度固定,因此不会出现在该列表中
- 列 t4 长度为3
- NULL 标志位:00
- 00表示没有字段为 NULL
- 记录头信息:00 00 10 00 2c
- ROWID:00 00 00 2b 68 00,从这个值可以看出,不是每张表从1开始递增的,是全局的 ROWID
- Transaction ID:00 00 00 00 06 05
- Roll Pointer:80 00 00 00 32 01 10
- t1:61
- 字符 a,VARCHAR(10),1个字符只占用了 1Byte
- t2:62 62
- 字符 bb,VARCHAR(10),2个字符只占用了 2Byte
- t3:62 62 20 20 20 20 20 20 20 20
- 字符 bb,CHAR(10),2个字符依旧占用了 10Byte
- t4:63 63 63
- 字符 ccc,VARCHAR(10),3个字符只占用了 3Byte
DYNAMIC
DYNAMIC 是 COMPACT 的变种,用来处理优化大对象记录的存储。
行溢出
- 当行记录的长度没有超过行记录最大长度时,所有数据都会存储在当前页。
- 当行记录的长度超过行记录最大长度时,变长列(variable-length column)会选择外部溢出页(overflow page,一般是 Uncompressed BLOB Page)进行存储。
那么这个行记录的最大长度是多长呢?
B+Tree 底层的叶子节点是一个双向链表,因此每个页中至少应该有两行记录,这就决定了 InnoDB 在存储一行数据的时候不能够超过 8kb,但事实上应该更小,因为还有一些 InnoDB 内部数据结构要存储。
COMPACT VS DYNAMIC
假设有一条记录有 A,B,C,D 四列,其中 D 列的是 text 类型,且含有 2W 个字节的长度,那么当前行记录的字节数超过一页(16k = 16384)能够存放的字节数,肯定会使用溢出页。
- COMPACT 会存储 text 中的前768个字节的数据,剩余的数据通过20个字节的指针指向溢出页。

- DYNAMIC 只会存储20个字节的指针指向溢出页,真实的数据存放在溢出页中。
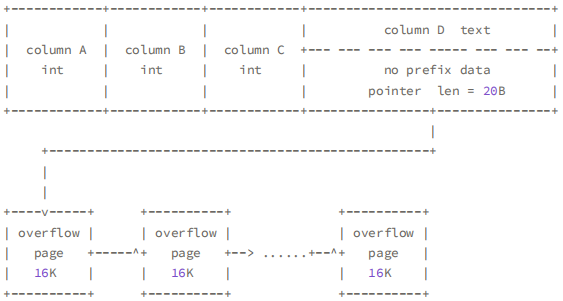
对比 COMPACT,DYNAMIC 在一个页中存储的记录数更多,因为 COMPACT 有768字节的 prefix,一条记录的字节假设是800字节,那 16K 的页只能存放20条记录,这样一来,B+Tree 的高度可能会变高,读取的 IO 次数可能会变多。
所以 DYNAMIC 的性能更好,innodb_default_row_format 默认设置为 DYNAMIC。
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/igecym 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
