volatile 可以认为是轻量级的锁,解决了可见性、有序性两个问题,接下来通过 volatile 生成的汇编指令来分析底层实现原理。
Eclipse 输出汇编指令
1.下载 hsdis 工具:https://sourceforge.net/projects/fcml/files/fcml-1.1.1/hsdis-1.1.1-win32-amd64.zip/download
2.解压后的内容放置到 jdk 安装目录的 jre\bin\server 目录下
3.运行 java 程序时添加如下 JVM 参数:-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*VisibleDemo.getInstance(替换成实际运行的代码)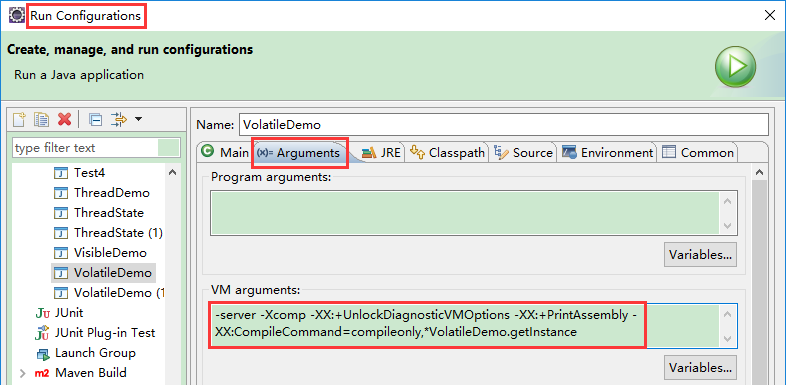
4.运行如下代码,查看汇编指令,发现通过 volatile 关键字修饰的属性在执行写操作的时候会加上 lock 指令
public class VolatileDemo {private static volatile VolatileDemo instance = null;public static VolatileDemo getInstance() {if (instance == null) {instance = new VolatileDemo();}return instance;}public static void main(String[] args) {VolatileDemo.getInstance();}}

volatile 如何保证可见性
volatile 修饰的共享变量,在进行写操作的时候会多出一个 lock 前缀的汇编指令,这个指令在前面我们讲解 CPU 高速缓存的时候提到过,会触发总线锁或者缓存锁,通过缓存一致性协议来解决可见性问题。
volatile 防止重排序
重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从 Java 源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图所示。

指令重排序必须要遵循的原则是,不影响代码执行的最终结果,编译器和处理器不会改变存在数据依赖关系的两个
操作的执行顺序,(这里所说的数据依赖性仅仅是针对单个处理器中执行的指令和单个线程中执行的操作)
这个语义,实际上就是 as-if-serial 语义,不管怎么重排序,单线程程序的执行结果不会改变,编译器、处理器都必
须遵守 as-if-serial 语义。
我们来通过代码来看一下重排序造成的问题
public class ThreadDemo01 {private static int x = 0, y = 0;private static int a = 0, b = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {a = 1;x = b;});Thread t2 = new Thread(() -> {b = 1;y = a;});t1.start();t2.start();t1.join();t2.join();System.out.println("x=" + x + ",y=" + y + ";");}}
上面代码可能的输出结果是:x=0,y=1;、x=1,y=0;、x=1,y=1; 这三种结果,因为可能是先后执行t1/t2,也可能是反过来,还可能是t1/t2交替执行,但是这段代码的执行结果也有可能是 x=0,y=0;。这就是在乱序执行的情况下会导致的一种结果,因为线程 t1 内部的两行代码之间不存在数据依赖,因此可以把 x=b 乱序到 a=1 之前;同时线程 t2 中的 y=a 也可以早于 t1 中的 a=1 执行,那么他们的执行顺序可能是
t1:x=bt2:b=1t2:y=at1:a=1
所以从上面的例子来看,重排序会导致可见性问题。但是重排序带来的问题的严重性远远大于可见性,因为并不是所有指令都是简单的读或写,比如DCL(Double Check Lock:双重检查锁)的部分初始化问题。所以单纯的解决可见性问题还不够,还需要解决处理器重排序问题。
lock 指令实际上加了一个内存屏障
内存屏障
内存屏障需要解决我们前面提到的两个问题,一个是编译器的优化乱序和CPU的执行乱序,我们可以分别使用优化
屏障和内存屏障这两个机制来解决。
从CPU层面来了解一下什么是内存屏障
CPU 的乱序执行,本质还是 CPU 多核心、CPU 高速缓存。存在多个缓存的时候,就必须通过缓存一致性协议(MESI)来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的问题,也就是运行时的内存乱序访问。
现在的 CPU 架构都提供了内存屏障功能,在 x86 的 CPU 中,实现了相应的内存屏障,写屏障(Store Barrier)、读屏障(Load Barrier)和全屏障(Full Barrier),主要的作用是:
- 防止指令之间的重排序
- 保证数据的可见性
Store Barrier
Store Barrier 称为写屏障,相当于 StoreStore Barrier,强制所有在 StoreStore 内存屏障之前的所有执行,都要在该内存屏障之前执行,并发送缓存失效的信号。所有在 StoreStore Barrier 指令之后的 Store 指令,都必须在 StoreStore Barrier 屏障之前的指令执行完后再被执行。限制了写屏障前后指令进行重排序,使得所有 Store Barrier 之前发生的内存更新都是可见的。
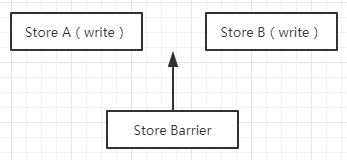
Store Barrier 保证 Store A 在 Store B 之前执行,并且 Store A 改变的值要同步到主内存,Store B 能够从主内存获取到最新的值。
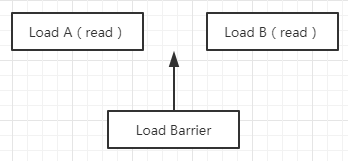
Load Barrier
Load Barrier 称为读屏障,相当于 LoadLoad Barrier,强制所有在 Load Barrier 读屏障之后的 Load 指令,都在 Load Barrier 屏障之后执行。也就是限制对 Load barrier 读屏障前后的 Load 指令进行重排序, 配合 Store Barrier,使得所有 Store Barrier 之前发生的内存更新,对 Load Barrier 之后的 Load 操作是可见的。
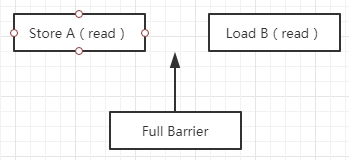
Full Barrier
Full Barrier 成为全屏障,相当于 StoreLoad,是一个全能型的屏障,因为它同时具备前面两种屏障的效果。限制了所有在 StoreLoad Barrier 之前的 Store/Load 指令,都在该屏障之前被执行,所有在该屏障之后的的 Store/Load 指令,都在该屏障之后被执行。禁止对 StoreLoad 屏障前后的指令进行重排序。
编译器层面如何解决指令重排序问题
在编译器层面,通过 volatile 关键字,取消编译器层面的缓存和重排序。保证编译程序是在优化屏障之前的指令不会在优化屏障之后执行。这就保证了编译时期的优化不会影响到实际代码逻辑顺序。
如果硬件架构本身已经保证了内存可见性,那么 volatile 就是一个空标记,不会插入相关语义的内存屏障。如果硬件架构本身不进行处理器重排序,有更强的重排序语义,那么 volatile 就是一个空标记,不会插入相关语义的内存屏障。
在 JMM 中把内存屏障指令分为4类,通过在不同的语义下使用不同的内存屏障来限制特定类型的处理器重排序,从而来保证内存的可见性。
- LoadLoad Barriers:load1 ; LoadLoad; load2,确保 load1 数据的装载优先于 load2 及所有后续装载指令的装载。
- StoreStore Barriers:store1; StoreStore; store2 , 确保 store1 数据对其他处理器可见优先于 store2 及所有后续存储指令的存储。
- LoadStore Barries:load1; LoadStore; store2, 确保 load1 数据装载优先于 store2 以及后续的存储指令刷新到内存。
- StoreLoad Barries:store1; StoreLoad; load2, 确保 store1 数据对其他处理器变得可见, 优先于 load2 及所有后续装载指令的装载;这条内存屏障指令是一个全能型的屏障,在前面讲 CPU 层面的内存屏障的时候有提到,它同时具有其他3条屏障的效果。
下面是基于保守策略的 JMM 内存屏障插入策略:
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
- 在每个 volatile 读操作的前面插入一个 LoadLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
查看源码
参考:http://www.importnew.com/27863.html
参考文章
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/cmkx14 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
