MVCC
MVCC 的定义
MVCC(Multiversion concurrency control):多版本并发控制,并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
MVCC 逻辑流程
插入

MySQL 在每一行数据中都会默认添加一些隐藏列 DB_TRX_ID、DB_ROLL_PT。
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(1)
- 然后往 teacher 表中插入两条数据,同时设置数据行的版本号为当前事务ID,删除版本号为 NULL
思考:如果事务是自动提交的(SET AUTOCOMMIT = NO),且未手动开启事务,执行如下两条 SQL,插入的数据会是什么样子的?
INSERT INTO teacher (NAME, age) VALUE ('seven', 18) ;INSERT INTO teacher (NAME, age) VALUE ('qingshan', 19) ;
因为事务是自动提交的,所以两条插入语句会分别获取事务ID,所以这里插入的数据行的版本号是1和2。
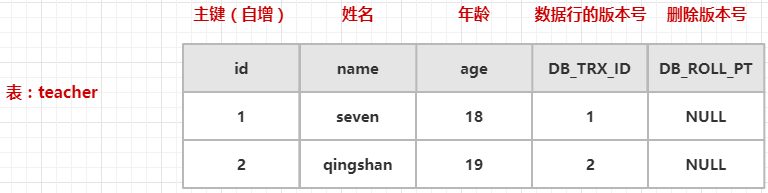
删除
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(22)
- 然后执行一条删除语句,InnoDB 会找到这条记录,把它的删除版本号设置为当前事务ID
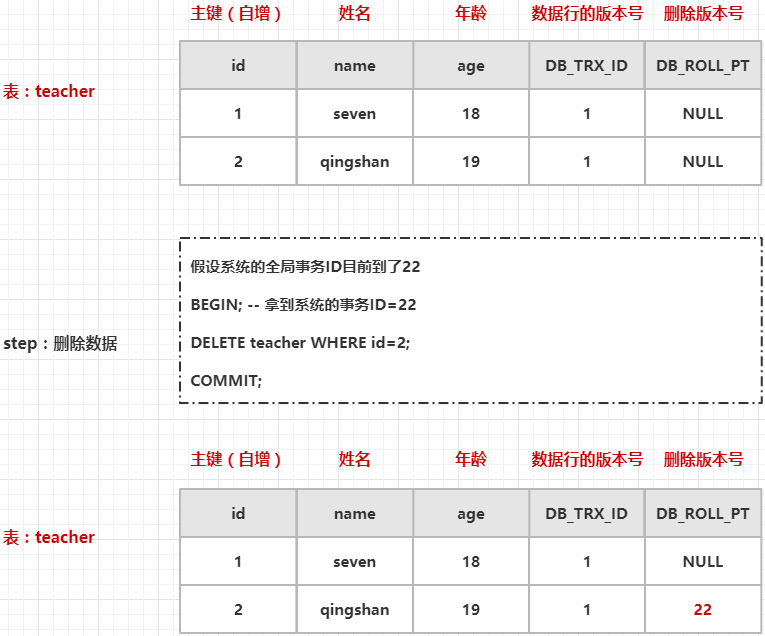
修改
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(33)
- 然后执行一条修改语句,InnoDB 会找到这条记录,copy 一份原数据插入到表中,将新行数据的数据行的版本号的值设置为当前事务ID,将原行数据的删除版本号的值设置为当前事务ID
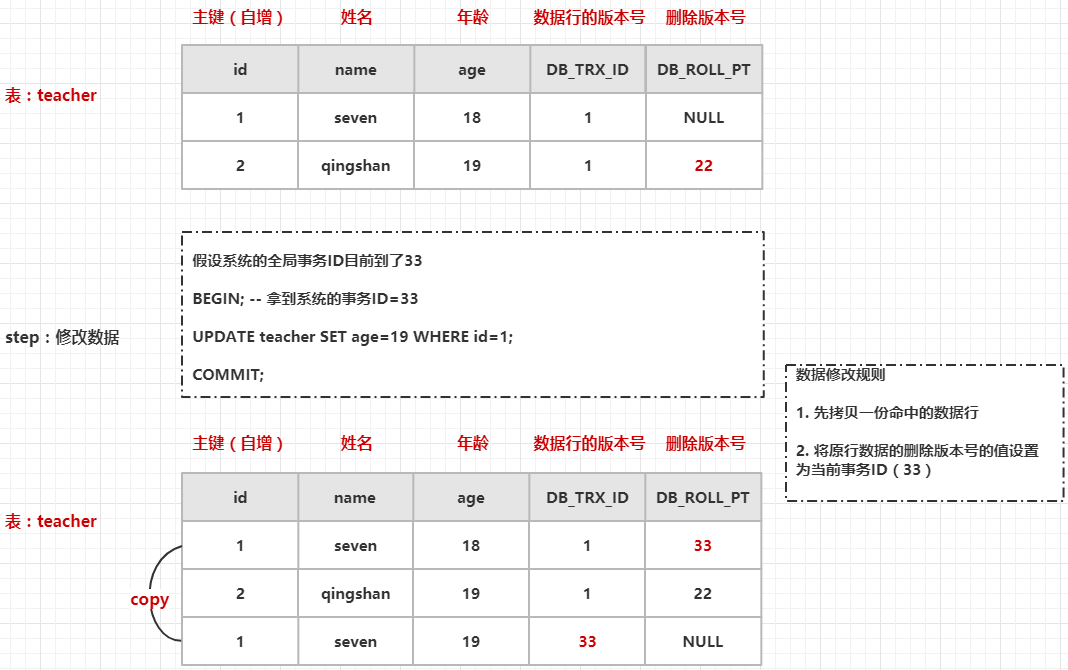
查询
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(44)
- 根据数据查询规则的描述
- 查找数据行版本早于当前事务版本的数据行,发现表中三行数据都满足条件
- 查找删除版本号要么为 NULL,要么大于当前事务版本号的记录,发现只有最后一条数据满足条件(1, seven, 19)
案例分析
数据准备:
CREATE TABLE `teacher` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(32) NOT NULL,`age` int(11) NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;INSERT INTO teacher(id,NAME,age) VALUES (1,'seven',18);INSERT INTO teacher(id,NAME,age) VALUES (2,'qingshan',20);
案例一
-- 事务A执行BEGIN; -- 1SELECT * FROM teacher; -- 2COMMIT;--事务B执行BEGIN; -- 3UPDATE teacher SET age =28 WHERE id=1; -- 4COMMIT;
案例一的执行步骤是:1,2,3,4,2,执行效果如下图所示:
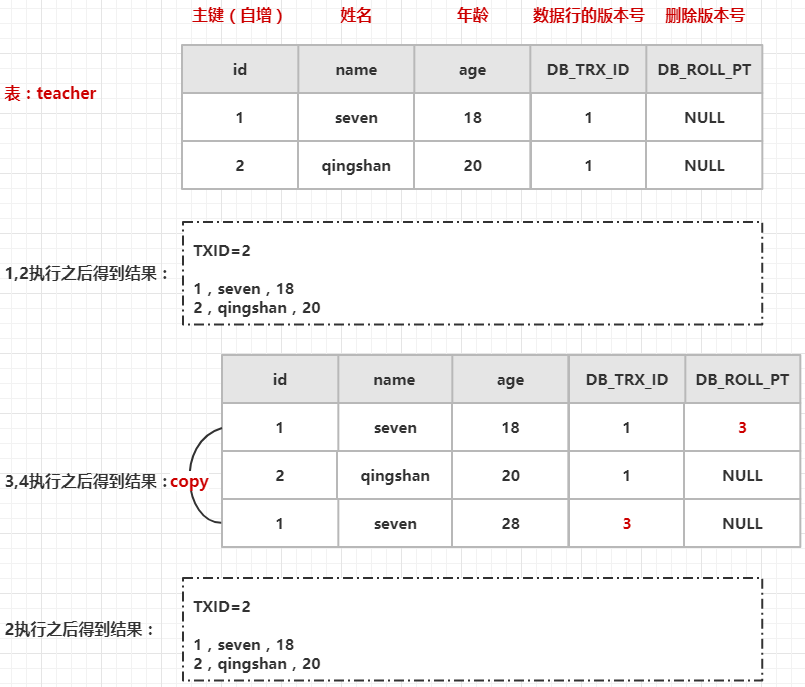
虽然在执行 3,4 步骤的时候更新 id=1 的数据,但是根据 MVCC 的查询逻辑流程,再次执行2,获取到的数据依然和第一次一样。
案例二
-- 事务A执行BEGIN; -- 1SELECT * FROM teacher; -- 2COMMIT;--事务B执行BEGIN; -- 3UPDATE teacher SET age =28 WHERE id=1; -- 4COMMIT;
案例二的执行步骤是:3,4,1,2,执行效果如下图所示:
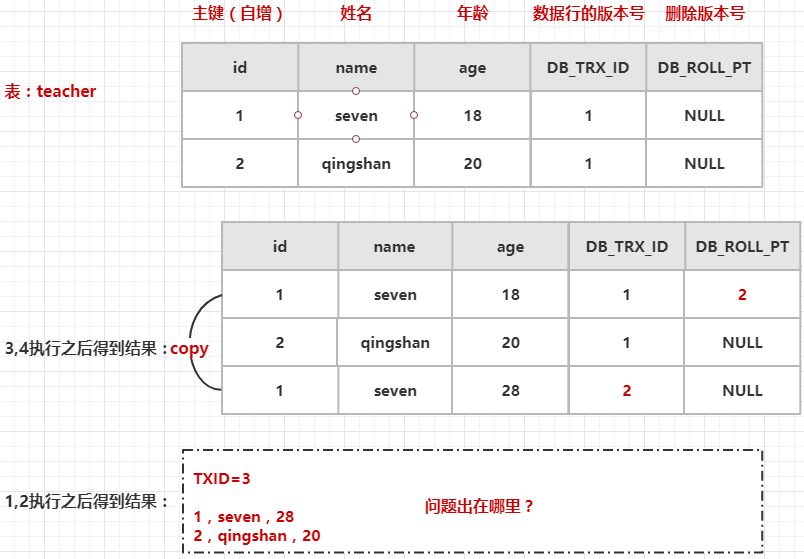
根据 MVCC 的查询逻辑流程,执行1,2,获取到的数据是事务B未提交的数据,这个是有问题的。
分析了案例一和案例二,发现 MVCC 不能解决案例二的问题,InnoDB 会使用 Undo log 解决案例二的问题。
Undo Log
Undo Log 的定义
Undo:意为取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务提交之前,会将事务修改数据的镜像(即修改前的旧版本)存放到 undo 日志里,当事务回滚时,或者数据库奔溃时,可以利用 undo 日志,即旧版本数据,撤销未提交事务对数据库产生的影响。。
- 对于 insert 操作,undo 日志记录新数据的 PK(ROW_ID),回滚时直接删除;
- 对于 delete/update 操作,undo 日志记录旧数据 row,回滚时直接恢复;
- 他们分别存放在不同的buffer里。
| Undo Log 是为了实现事务的原子性而出现的产物。 Undo Log 实现事务原子性:事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。 |
|---|
InnoDB 发现可以基于 Undo Log 来实现多版本并发控制。
| Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。 Undo Log 实现多版本并发控制:事务未提交之前,Undo Log 保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。 |
|---|
分析下图中 SQL 的执行过程。
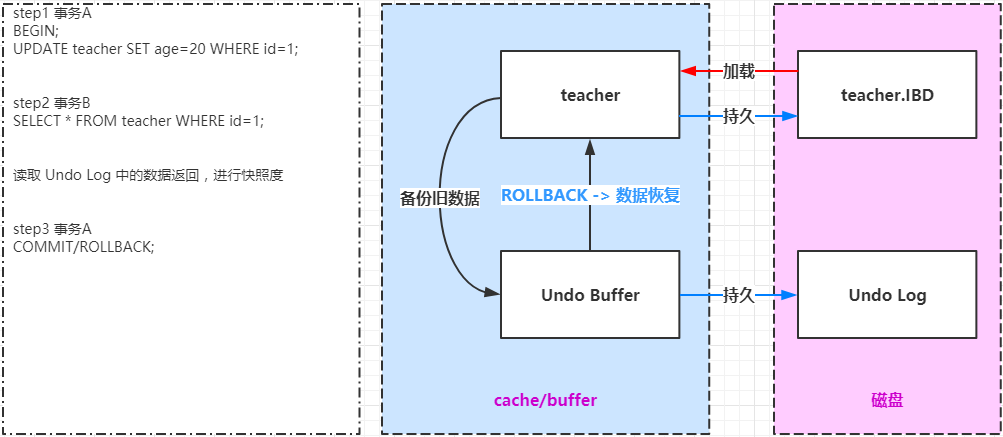
- 事务A手动开启事务,执行更新操作,首先会把更新命中的数据拷贝到 Undo Buffer 中
- 事务B手动开启事务,执行查询操作,会读取 Undo Log 中数据返回,进行快照度
当前读和快照读
快照读
SQL 读取的数据是快照版本,也就是历史版本,普通的 SELECT 就是快照读。
InnoDB 快照读,数据的读取将由 cache(原本数据)+ Undo Log(事务修改过的数据)两部分组成。
当前读
SQL 读取的数据是最新版本,通过锁机制来保证读取的数据无法通过其他事务进行修改。
UPDATE 、DELETE 、INSERT 、SELECT … LOCK IN SHARE MODE 、SELECT … FOR UPDATE 都是当前读,这些操作在《MySQL InnoDB 锁》这篇文章中有过演示,事务A执行这些 SQL,会阻塞事务B的 SQL 执行。
在 InnoDB 引擎里面,快照读通过 MVCC 解决幻读的问题,当前读通过 Next-Key Locks 解决幻读的问题。
Redo Log
Redo Log 的定义
Redo:顾名思义就是重做。以恢复操作为目的,重现操作。
Redo Log:指事务中操作的任何数据,将最新的数据备份到一个地方(Redo Log)。
Redo Log 的持久化:不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入 Redo Log 中,具体的落盘策略可以进行配置。
Redo Log 是为了实现事务的持久性而出现的产物。
Redo Log 实现事务持久性:防止在发生故障的时间点,尚有脏页未写入表的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
根据下图分析 Redo Log 的执行流程
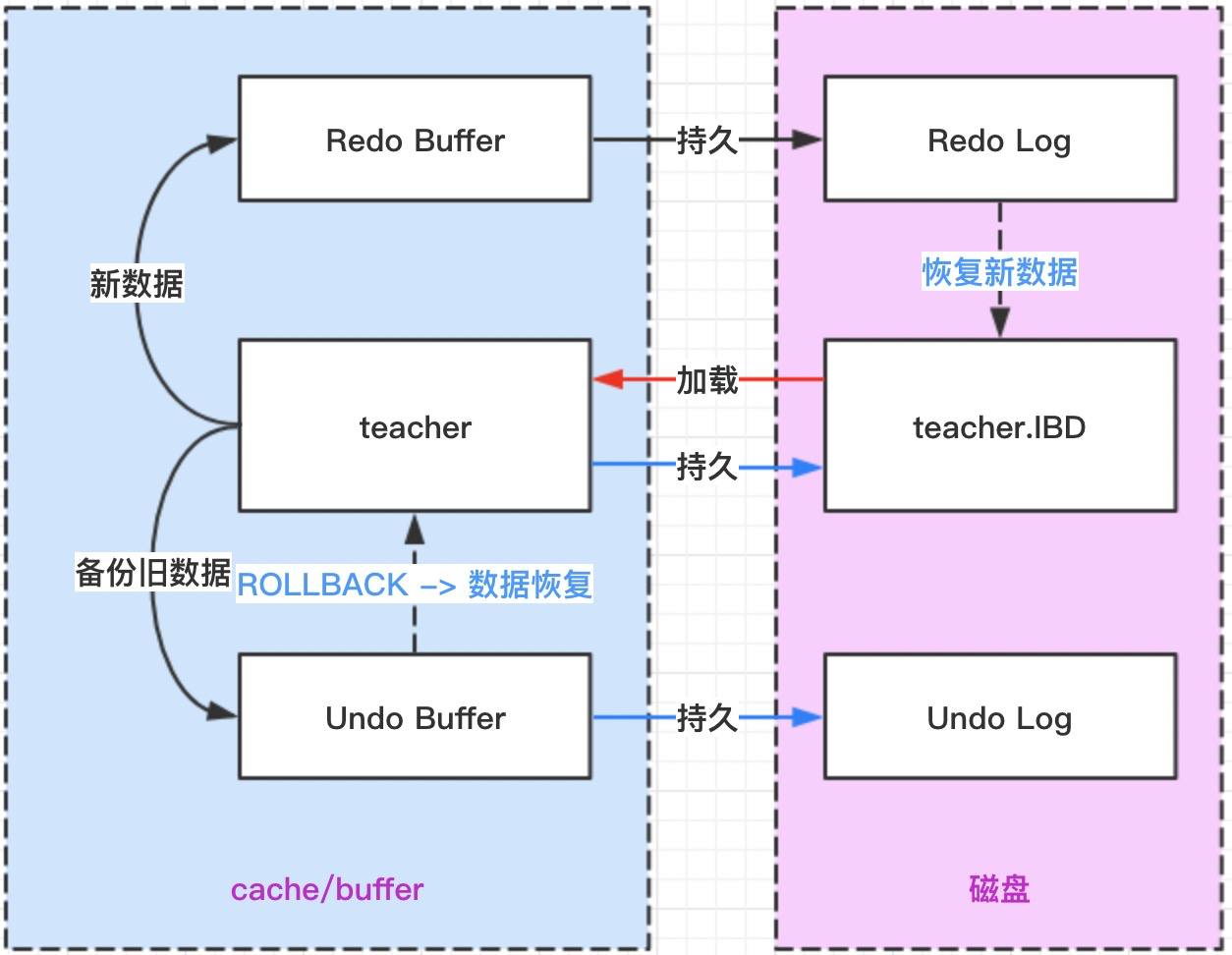
InnoDB 不是每一次提交事务都把数据从缓存区持久化到硬盘的,因为每次提交事务都把数据持久化到硬盘,效率很低,每一次持久化都需要执行 IO 操作。
InnoDB 会把每次数据变化会先进入 Redo Buffer 中,事务提交了,会根据策略把新的数据写入 Redo Log 中,InnoDB 就会认为这次事务提交成功了,数据并不一定马上就进入表的 IBD 文件中。
疑问:持久化到 Redo Log 中和持久化到表的 IBD 文件一样都是 IO 操作,为什么要设计 Redo Log 呢?
其实是因为持久化到 Redo Log 中是顺序 IO 的操作,而持久化到表的 IBD 文件中是一个随机 IO 的操作,比如我们需要更新 id=1 和 id=8 的数据,如果是 Redo Log,就只需要把更新的数据顺序存入 Redo Log 中;但如果是表的 IBD 文件,就需要先找到 id=1 和 id=8 的两个不连续的磁盘文件地址,再做持久化操作,影响数据库服务的并发性能。
Redo Log 的持久化配置
指定 Redo Log 记录在 {datadir}/ib_logfile1 和 ib_logfile2 两个文件中,可以通过 innodb_log_group_home_dir配置指定目录存储。
一旦事务成功提交且数据持久化到表的 IBD 文件中之后,此时 Redo Log 中的对应事务数据记录就失去了意义,所 以 Redo Log 的写入是日志文件循环写入的过程,也就是覆盖写的过程。
- 指定 Redo Log 日志文件组中的数量 innodb_log_files_in_group 默认为2
- 指定 Redo Log 每一个日志文件最大存储量 innodb_log_file_size 默认48M
指定 Redo Log 在 cache/buffer 中的 buffer 池大小 innodb_log_buffer_size 默认16M
<br />**Redo Buffer 持久化到 Redo Log 的策略**,通过设置 Innodb_flush_log_at_trx_commit 的值:
取值0:每秒提交 Redo buffer -> Redo Log OS cache -> flush cache to disk,可能丢失一秒内的事务数据。
- 取值1(默认值):每次事务提交执行 Redo Buffer -> Redo Log OS cache -> flush cache to disk,最安全,性能最差的方式
- 取值2:每次事务提交执行 Redo Buffer -> Redo log OS cache 再每一秒执行 -> flush cache to disk 操作
一般建议选择取值2,因为 MySQL 挂了最多损失一次事务提交的数据,整个服务期挂了才会损失一秒的事务提交数据。
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/skszul 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
