转载:《58怎么玩数据库架构》
文章主要从高可用、读性能、一致性、扩展性这四个方面来设计数据库的整体架构。
介绍
了解一下数据库的基本概念。
单库
首先是“单库”,最开始的时候数据库都是这么玩的,几乎所有公司都会经历这个阶段。
分片
接下来是“分片”,也就是水平切分,它是用来解决数据量大的问题。有一些数据库支持 auto sharding,自动分片,例如 mongoDB,58同城也用过两年 mongoDB,后来发现 auto sharding 不太可控,不知道什么时候会进行数据迁移,数据迁移过程中会有大粒度的锁,读写被阻塞,业务会有抖动和毛刺,这些是业务不能接受的,于是后来又被我们弃用。
一旦进行分片,就会面临“数据路由”的问题,来了一个请求,要将请求路由到对应的数据库分片上。互联网常用的数据路由方法有三种:
1、按照数据范围路由,比如有两个分片,一个范围是0-1亿,一个范围是1亿-2亿,这样来路由。
优点:是非常的简单,并且扩展性好,假如两个分片不够了,增加一个2亿-3亿的分片即可。
缺点:虽然数据的分布是均衡的,每一个库的数据量差不多,但请求的负载会不均衡。例如有一些业务场景,新注册的用户活跃度更高,大范围的分片请求负载会更高。
2、按照 hash 路由,比如有两个分片,数据模2寻库即可。
优点:路由方式很简单,数据分布也是均衡的,请求负载也是均衡的。
缺点:是如果两个分片数据量过大,要变成三个分片,数据迁移会比较麻烦,即扩展性会受限。
3、路由服务。前面两个数据路由方法均有一个缺点,业务线需要耦合路由规则,如果路由规则发生变化,业务线是需要配合升级的。路由服务可以实现业务线与路由规则的解耦,业务线每次访问数据库之前先调用路由服务,来知道数据究竟存放在哪个分库上。
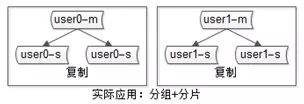
分组
接下来是“分组”与“复制”,这解决的是扩展读性能,保证读高可用的问题。
根据经验,大部分互联网的业务都是读多写少。淘宝、京东查询商品,搜索商品的请求可能占了99%,只有下单和支付的时候有写请求。
大部分互联网的场景都读多写少,一般来说读性能会最先成为瓶颈,怎么快速解决这个问题呢?
我们通常使用读写分离,扩充读库的方式来提升系统的读性能,同时多个读库也保证了读的可用性,一台读库挂了,另外一台读库可以持续的提供服务。
常见数据库软件架构的的玩法综合了“分片”和“分组”,数据量大进行分片,为了提高读性能,保证读的高可用,进行了分组,80%互联网公司数据库都是下图这种软件架构。
高可用
数据库大家都用,平时除了根据业务设计表结构,根据访问来设计索引之外,还应该在设计时考虑数据的可用性,可用性又分为读的高可用与写的高可用。
读的高可用
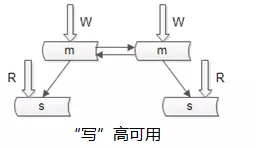
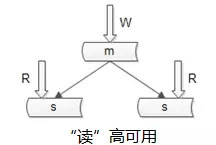
下图是“读”高可用的常见玩法,我们是怎么样保证读库的高可用的呢?解决高可用这个问题的思路是冗余。

解决站点的可用性问题冗余多个站点,解决服务的可用性问题冗余多个服务,解决数据的可用性问题冗余多份数据。
如果用一个读库,保证不了读高可用,就复制读库,一个读库挂了另一个仍然可以提供服务,这么用复制的方式来保证读的可用性。
数据的冗余会引发一个副作用,就是一致性的问题。
如果是单库,读和写都落在同一个库上,每次读到的都是最新的数据库,不存在一致性的问题。
但是为了保证可用性将数据复制到多个地方,而这多个地方的数据绝对不是实时同步的,会有同步时延,所以有可能会读到旧的数据。如何解决主从数据库一致性问题我们在后面再来讲。
写的高可用
很多互联网公司的数据库软件架构都是一主两从或者一主三从,不能够保证“写”的高可用,因为写其实还是只有一个库,仍是单点,如果这个库挂了的话,写会受影响。那小伙伴们为什么还使用这个架构呢?
我刚才提到大部分互联网公司99%的业务都是“读”业务,写库不是主要矛盾,写库挂了,可能只有1%的用户会受影响。
如果要做到“写”的高可用,对数据库软件架构的冲击比较大,不一定值得,为了解决1%的问题引入了80%的复杂度,所以很多互联网公司都没有解决写数据库的高可用的问题。
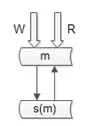
怎么来解决写的高可用问题呢?思路还是冗余,读的高可用是冗余读库,写的高可用是冗余写库。把一个写变成两个写,做一个双主同步,一个挂了的话,可以将写的流量自动切到另外一个,写库的高可用性。
用双主同步的方式保证写高可用性会存在什么样的问题?
刚才提到,用冗余的方式保证可用性会存在一致性问题。因为两个主相互同步,这个同步是有时延的,很多公司用到auto-increment-id 这样的一些数据库的特性,如果用双主同步的架构,一个主 id 由10变成11,在数据没有同步过去之前,另一个主又来了一个写请求,也由10变成11,双向同步会主键冲突,同步失败,造成数据丢失。
解决这个双主同步 id 冲突的方案有两种:
- 一个是双主使用不同的初始值,相同的步长来生成 id,一个库从0开始(生成02468),一个库从1开始(生成13579),步长都为2,这样两边同步数据就不会冲突。
- 另一个方式是不要使用数据库的 auto-increment-id,而由业务层来保证生成的 id 不冲突。
58同城没有使用上述两种方式来保证读写的可用性,我们使用的是“双主”当“主从”的方式来保证数据库的读写可用性。
虽然看上去是双主同步,但是读写都在一个主上,另一个主库没有读写流量,完全 standby。当一个主库挂掉的时候,流量会自动的切换到另外一个主库上,这一切对业务线都是透明的,自动完成。
58同城的这种方案,读写都在一个主库上,就不存同步延时而引发的一致性问题了,但缺点有两个:
- 数据库资源利用率只有50%;
- 没有办法通过增加读库的方式来扩展系统的读性能;
58同城的数据库软件架构如何来扩展读性能呢,我们接着来看下面的内容。
读性能
如何增加数据库的读性能,先看下传统的玩法:
1、增加从库,通过增加从库来提升读性能,缺点是什么呢?从库越多,写的性能越慢,同步的时间越长,不一致的可能性越高。
2、增加缓存,缓存是大家用的非常多的一种提高系统读性能的方法,特别是对于读多写少的互联网场景非常的有效。常用的缓存玩法如下图,上游是业务线,下游是读写分离主从同步和一个 cache。
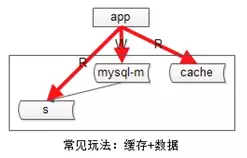
- 对于写操作:会先淘汰 cache,再写数据库。
- 对于读操作:先读 cache,如果 cache hit 则返回数据,如果 cache miss 则读从库,然后把读出来的数据再入缓存。
传统的 cache 玩法在一种异常时序下,会引发严重的一致性问题,考虑这样一个特殊的时序:
- 先来了一个写请求,淘汰了 cache,写了数据库;
- 又来了一个读请求,读 cache,cache miss 了,然后读从库,此时写请求还没有同步到从库上,于是读了一个脏数据,接着脏数据入缓存;
- 最后主从同步完成;
这个时序会导致脏数据一直在缓存中没有办法被淘汰掉,数据库和缓存中的数据严重不一致。
58同城也是采用缓存的方式来提升读性能的,那我们会不会有数据一致性问题呢,我们接着来看下面的内容。
一致性
主从不一致
58同城采用“服务+缓存+数据库”一套的方式来保证数据的一致性,由于58同城使用“双主当主从用”的数据库读写高可用架构,读写都在一个主库上,不会读到所谓“读库的脏数据”,所以数据库与缓存的不一致情况也不会存在。
传统玩法中,主从不一致的问题有一些什么样的解决方案呢?
主从为什么会不一致?刚才提到读写会有时延,有可能读到从库上的旧数据。常见的方法是引入中间件,业务层不直接访问数据库,而是通过中间件访问数据库,这个中间件会记录哪一些 key 上发生了写请求,在数据主从同步时间窗口之内,如果 key 上又出了读请求,就将这个请求也路由到主库上去(因为此时从库可能还没有同步完成,是旧数据),使用这个方法来保证数据的一致性。
中间件的方案很理想,那为什么大部分的互联网的公司都没有使用这种方案来保证主从数据的一致性呢?
那是因为数据库中间件的技术门槛比较高,有一些大公司,例如百度,腾讯,阿里他们可能有自己的中间件,并不是所有的创业公司互联网公司有自己的中间件产品,况且很多互联网公司的业务对数据一致性的要求并没有那么高。比如说同城搜一个帖子,可能5秒钟之后才搜出来,对用户的体验并没有多大的影响。
除了中间件,读写都路由到主库,58同城就是这么干的,也是一种解决主从不一致的常用方案。
数据库和缓存的不一致
解决完主从不一致,第二个要解决的是数据库和缓存的不一致,上一章提到 cache 传统的玩法,脏数据有可能入 cache,我们怎么解决呢?
两个实践:第一个是缓存双淘汰机制,第二个是建议为所有 item 设定过期时间(前提是允许 cache miss)。
- 缓存双淘汰,传统的玩法在进行写操作的时候,先淘汰 cache 再写主库。上文提到,在主从同步时间窗口之内可能有脏数据入 cache,此时如果再发起一个异步的淘汰,即使不一致时间窗内脏数据入了 cache,也会再次淘汰掉。
- 为所有 item 设定超时时间,例如10分钟。极限时序下,即使有脏数据入 cache,这个脏数据也最多存在十分钟。带来的副作用是,可能每十分钟,这个 key 上有一个读请求会穿透到数据库上,但我们认为这对数据库的从库压力增加是非常小的。
扩展性
扩展性也是架构师在做数据库架构设计的时候需要考虑的一点。我分享一个58同城非常帅气的秒级数据扩容的方案。这个方案解决什么问题呢?原来数据库水平切分成 N 个库,现在要扩容成 2 N个库,要解决这个问题。
假设原来分成两个库,假设按照 hash 的方式分片,如下图分为奇数库和偶数库。
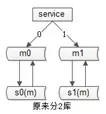
1、提升从库,底下一个从库放到上面来(其实什么动作都没有做);
2、修改配置,此时扩容完成,原来是2个分片,修改配置后变成4个分片,这个过程没有数据的迁移。原来偶数的那一部分现在变成了两个部分,一部分是0,一部分是2,奇数的部分现在变成1和3。0库和2库没有数据冲突,只是扩容之后在短时间内双主的可用性这个特性丢失掉了。
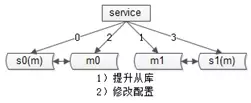
3、还要做一些收尾操作,把旧的双主给解除掉,为了保证可用性增加新的双主同步,原来拥有全部的数据,现在只为一半的数据提供服务了,我们把多余的数据删除掉,结尾这三个步骤可以事后慢慢操作。整个扩容在过程在第二步提升从库,修改配置其实就秒级完成了,非常的帅气。
这个方案的缺点是只能实现N库到2N 库的扩容,2变4、4变8,不能实现2库变3库,2库变5库的扩容,如何能够实现这种扩容呢?
参考《数据迁移方案》
作者:殷建卫 链接:https://www.yuque.com/yinjianwei/vyrvkf/khaonv 来源:殷建卫 - 架构笔记 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
