
前言
书接上回,我们继续来学习Dreambooth 官方文档的后续内容,这篇文章主要有图像处理、影响显存用量的高级设置等模块参数的说明,最后的 Concepts 面板放在第三篇文章中进行。
接下来我还是结合自己的理解,靠着 GPT4、NewBing 的帮助和大家一起修炼这份炼丹术进阶教程,继续踏上这炼丹修仙长生之路!
Training Parameters 训练参数
Image Processing**图像处理**
在这里,您将找到与图像处理相关的设置。

Resolution 分辨率
设置实例图像的分辨率。这应该是 512 或 768。使用高于 512 的分辨率将导致更多的显存使用。
最大分辨率一般默认512,如果有打算使用更大的训练集来训练的话才需要调大这个参数。还有一种说法是用大分辨的设定去训练512的数据集,也会有些不同的效果,等于让AI用放大镜看素材,这个说法我还未验证。
使用大分辨率素材进行训练的同时,可以考虑调低 Batch size 以降低显存压力,用时间换空间。
新版的Dreambooth已经支持自己把图切小了,但是切的比较粗糙,要来追求更好的效果的话,还是得手动来切效果最好。
样式说明:灰色正文主要来自官方文档翻译,有些地方不通顺,我会做一定程度的更改。黑色正文则是我自己的理解和总结,如有错漏,欢迎斧正。
Center Crop 中心裁剪
启用此选项可在输入图像尺寸大于指定分辨率时自动使用“简单裁剪”。
这个选项暂未找到,如果希望进行中心裁剪的话可以使用训练Tab下的图片处理。
Apply Horizontal Flip 应用水平翻转
应用水平翻转 - 启用后,在训练过程中,实例图像将随机水平翻转。这可以提高可编辑性,但可能需要更多的训练步数,因为我们实际上是在增加数据集的大小。
目前的认识是这样做的意义不大,但在业界这是通用方法,如果训练集图片特别少的话,可以尝试一下开启看是否有问题。
但是不能用于有特定方向性的训练集,比如需要体现交通标志的训练集,左右转就会混乱。
样式说明:灰色正文主要来自官方文档翻译,有些地方不通顺,我会做一定程度的更改。黑色正文则是我自己的理解和总结,如有错漏,欢迎斧正。
Advanced Settings 杂项
其他不容易归入其他类别的随机内容。
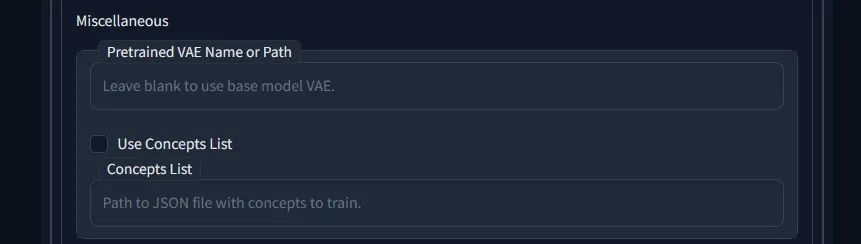
Pretrained VAE Name or Path 预训练 VAE 名称或路径
输入现有 vae .bin 文件的完整路径,系统将使用该文件代替源检查点中的 VAE。
这是一个高级设置,调用路径中的VAE替代原模型的VAE。如果有对应需求,比如训练成果发灰等,可以试试。
Use Concepts List 使用概念列表
启用此功能可忽略概念标签页,并从 JSON 文件中加载训练数据。
勾选后下方 Concepts List 概念列表输入框中的路径才会启用。概念标签页即是指下图的 Concept 标签页,部分高级需求中使用 JSON 文件的形式比在界面调整一项项调整更加方便快捷。
Concepts List 概念列表
包含要训练的概念的 JSON 文件的路径。
Advanced Settings 高级设置
在这里,您会找到更多与性能相关的设置。更改这些设置可能会影响训练所需的显存量。
Tuning 调优
Use CPU Only 仅使用 CPU
如所示,这是在无法使用任何其他设置进行训练时的最后手段。同时,如所示,这将非常缓慢。此外,您无法在 CPU 训练中使用 8Bit-Adam,否则会遇到问题。
仅使用CPU渲染会非常缓慢,通常不建议使用。这个选项未在界面上找到对应。
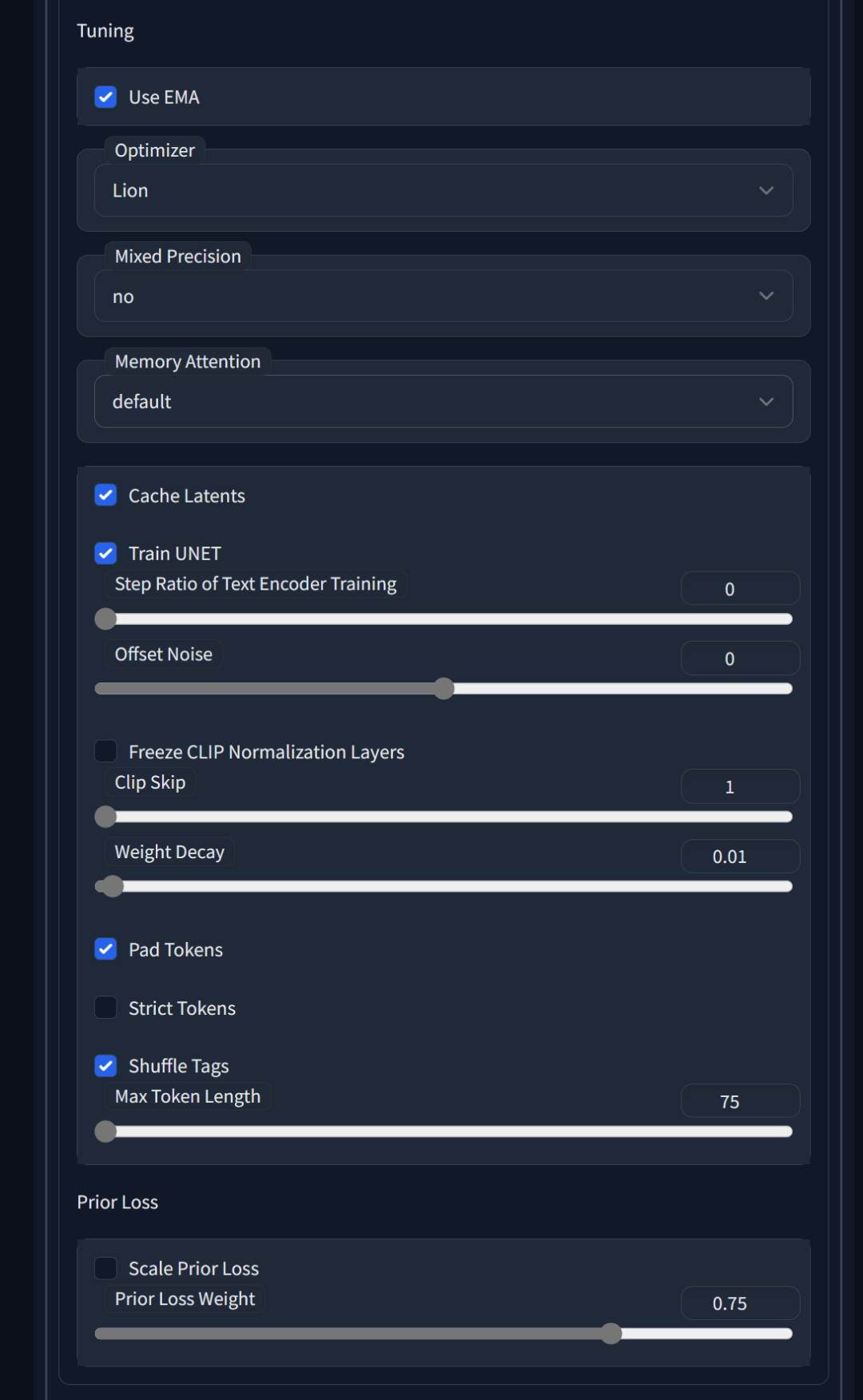
Use EMA 使用 EMA
在训练 unet 时使用估计移动平均值。据称,这对生成图像更有利,但对训练结果的影响似乎微乎其微。开启会使用更多显存。
在显存实在是花不完的情况下可以开启,反正没啥坏处。
在界面中除了 Tuning 面板还有三处对应:
Save EMA Weights to Generated Models:这个选项表示在训练过程中,将使用 EMA 方法计算的权重保存到生成的模型文件中。
Use EMA Weights for Inference:这个选项表示在使用训练好的模型进行预测或生成时,使用 EMA 平滑处理过的权重。
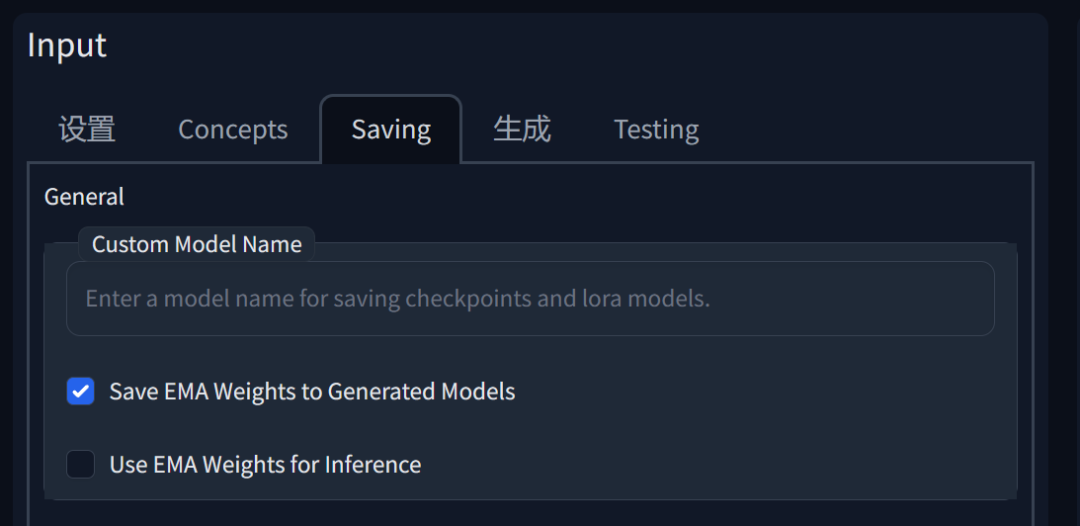
Use EMA for prediction : 这个选项和Use EMA Weights for Inference 类似,表示在模型测试时临时应用 EMA 权重。
EMA(Exponential Moving Average,指数移动平均)是一种常用的平滑技术,用于平滑数据并减少噪声。在深度学习中,EMA 通常用于更新模型参数,以便在训练过程中获得更稳定的参数值。它通过对最近的参数更新应用更高的权重,从而在参数更新中引入了一种衰减效应。这有助于减少过拟合和梯度更新中的噪声。
在以下场景中,可以考虑使用 EMA:希望提高模型生成结果的质量时,例如生成更清晰、更平滑的图像。想要减少梯度更新中的噪声,并降低过拟合风险时。
Mixed Precision混合精度
当使用 8bit AdamW 时,您必须将其设置为 fp16 或 bf16。Bf16 精度仅由较新的 GPU 支持,并默认启用/禁用。
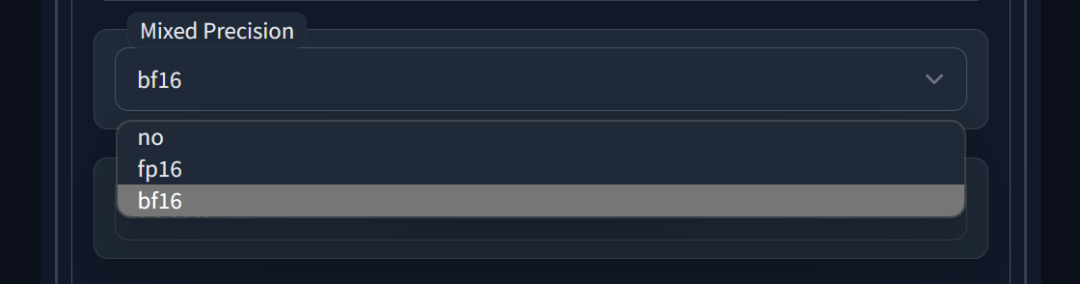
这是一种节约算力和显存的方案,设置为No就代表不用节约,使用fp16等节约方案一般不会对模型质量有影响。
普通显卡可以设置为fp16,如果是A100等专业显卡,那么肯定支持bf16。3090等30系显卡也可以尝试一下,使用4090可以成功开始训练,训练效果暂时无法准确评估。
bf16(bfloat16)是一种浮点数表示格式,旨在提供与FP32(32位浮点数)类似的精度,但使用较少的内存和计算资源。
在深度学习中,使用不同的浮点数精度(如no、fp16、bf16)会对运算速度、显存使用和模型质量产生不同的影响
fp16(16位浮点数):FP16精度将数值范围和精度降低到16位,从而减少计算资源和显存使用。这通常会导致更快的运算速度和更低的显存使用。使用FP16时,可能会出现数值不稳定的问题,例如梯度消失和梯度爆炸。这可能会影响模型训练和生成图像的质量。然而,通过使用混合精度训练(结合FP32和FP16),可以在保持较高模型质量的同时,充分利用FP16的优势。
bf16(bfloat16,16位浮点数):bf16是一种介于FP32和FP16之间的精度设置。它在运算速度和显存使用方面的性能优于FP32,但低于FP16。bf16的精度接近FP32,因此在许多情况下,它能够保持较高的模型质量和图像生成质量。然而,bf16目前只受限于一些特定的AI硬件和GPU支持。
Memory Attention 显存注意力类型
可选项包括:’default’:通常最快,但使用最多显存;‘xformers’:较慢,使用较少显存,只能与 Mixed Precision = ‘fp16’ 一起使用(对 Apple Silicon 无影响);’flash_attention’:最慢,需要最低显存。
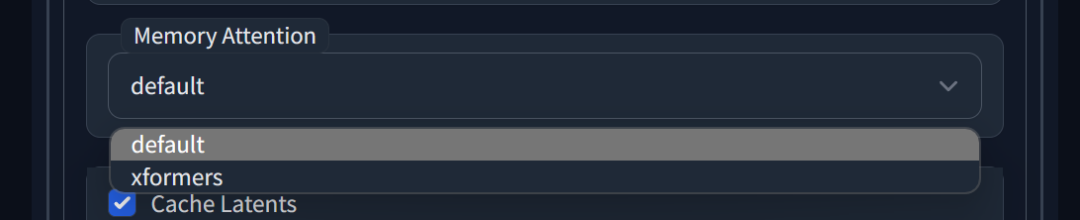
这是一种显存使用方案,default 不会对模型质量造成影响,xformers 和flash_attention 是有影响,但很微小。可以根据自己的显存情况选择,一般设定为 xformers 。
Don’t Cache Latents 不缓存潜变量
为什么这个选项不直接叫做“缓存”潜变量呢?因为这是原始脚本所使用的术语,我希望尽可能简单地更新它。无论如何…勾选此框时,潜变量将不会被缓存。当潜变量未被缓存时,您可以节省一些显存,但训练速度会稍慢。
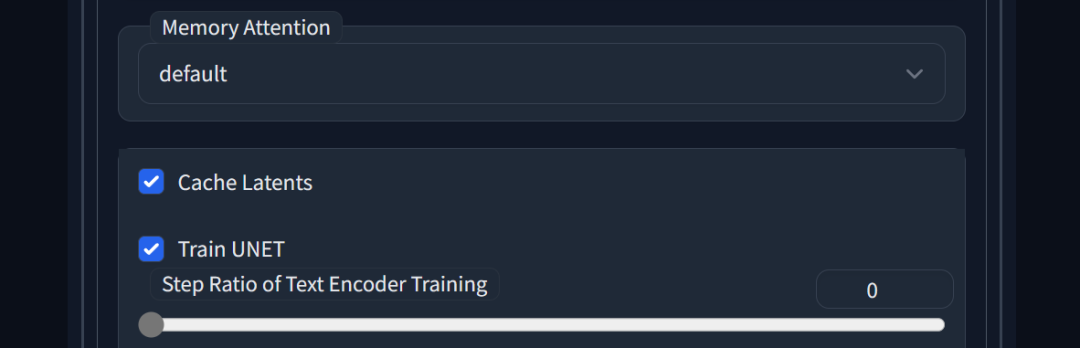
这也是个显存使用方案,一样的开启则多用一点显存,关闭则会有微小的负面影响,但一般也没啥问题。还是有足够显存的建议开启。
Train Text Encoder 训练文本编码器
非必需,但推荐。需要更多显存,可能无法在 <12 GB 的 GPU 上工作。大幅改善输出结果。
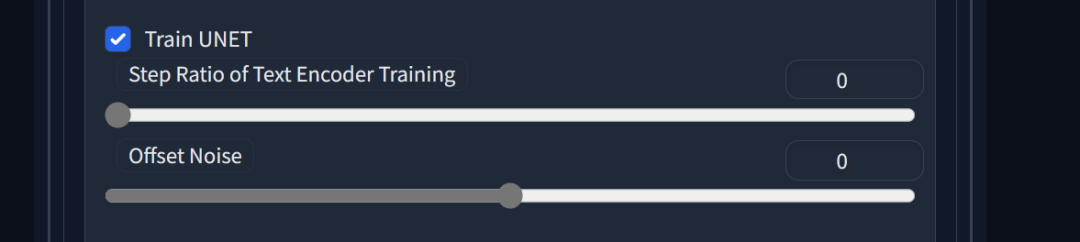
这是一个重点选项,有条件的建议都开启这个Train Text Encoder,可以考虑使用前面的节约显存方案节约出足够的显存给Train Text Encoder 使用,毕竟能有显著正面影响的参数实在不多。
Train UNET 复选框默认勾选,Step Ratio of Text Encoder Training 这个参数控制文本编码器训练的频率,它表示训练文本编码器的步数与训练整个模型的步数之间的比例。
较低的值意味着文本编码器训练较少,而较高的值意味着文本编码器训练较多。较高的值可能有助于提高模型对文本的理解能力,但可能需要更多的显存和算力,可以略大一点。
Offset Noise 这个参数控制在训练过程中添加到输入文本向量的噪声量。增加噪声可以提高模型的泛化能力,因为它可以防止模型过拟合训练数据。然而,太高的噪声水平可能导致模型性能下降,所以可以保持默认为0,当你需要模型有更强的泛化能力时再尝试开启。
训练文本编码器(Train Text Encoder)可以大幅改善模型质量和图像生成质量,因为它使得模型能够更好地理解和处理输入文本。当你训练一个深度学习模型以生成图像时,通常会有一个文本编码器负责将文本描述转换为可以被模型理解的向量表示。这个向量表示能够捕捉文本中的语义信息,使模型能够根据文本生成相应的图像。
不训练文本编码器(使用预训练的编码器)可能导致模型在处理特定任务或领域的文本时性能较差,因为预训练的编码器可能无法完全捕捉到与任务相关的语义信息。相反,训练文本编码器可以使其适应特定任务,从而提高模型对输入文本的理解能力。这样,模型可以生成更准确、更高质量的图像,更好地符合输入文本的描述。
Prior Loss Weight先验损失权重
在计算先验损失(prior loss)时使用的权重。您可能想将这个值保留为1。
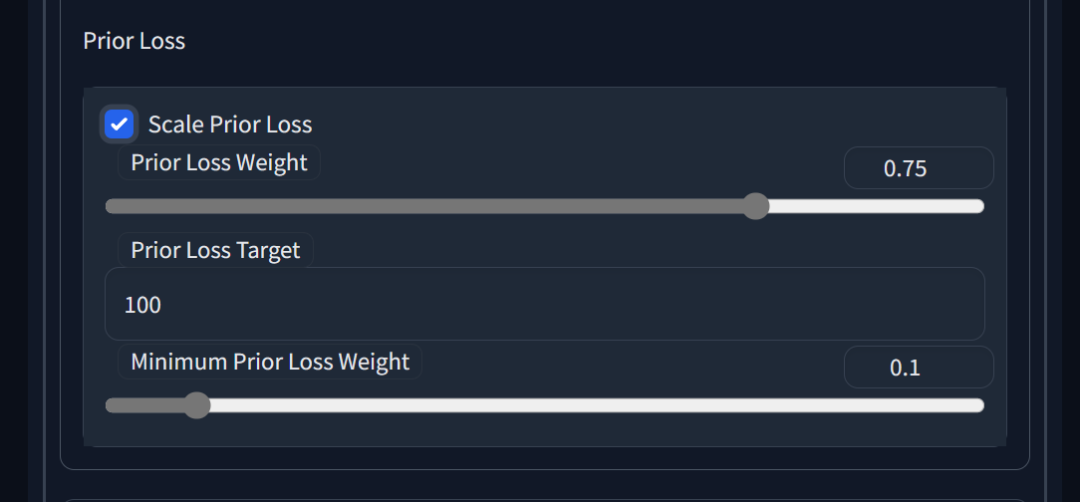
先验损失权重(Prior Loss Weight)数值为1就满足大部分场景了,如果需要调整的话,原则是当先验损失权重设置较高时,模型会更注重优化先验损失,从而更贴近训练数据。相反,若权重较低,则模型会更关注其他损失部分,从而提高泛化能力。
先验损失权重(Prior Loss Weight)就像是一位明智的指挥家,在不同音符之间找到和谐的平衡,使整个乐章更加优美。
在神经网络中,损失函数(Loss Function)是用来衡量模型预测结果与实际目标之间差异的指标。训练过程中,模型通过不断优化损失函数的值来提升预测性能。
Scale Prior Loss(缩放先验损失):启用此选项,可以根据训练过程中的先验损失目标(Prior Loss Target)和最小先验损失权重(Minimum Prior Loss Weight)动态调整先验损失权重(Prior Loss Weight)。这有助于使模型在训练过程中自动调整权重,以便在不同阶段关注不同的损失部分。
Prior Loss Weight(先验损失权重):此滑杆用于设置先验损失权重的初始值。
Prior Loss Target(先验损失目标):此输入框用于设置先验损失的目标值。当启用缩放先验损失功能时,模型会根据此目标值动态调整先验损失权重,以保持先验损失在接近目标值的范围内。
Minimum Prior Loss Weight(最小先验损失权重):当启用缩放先验损失功能时,此滑杆用于设置先验损失权重的最小值。这可以防止权重过低,从而确保模型在训练过程中始终关注先验损失,保证足够贴近训练数据。
Center Crop 中心裁剪
如果图像尺寸不正确,是否进行裁剪?我不使用这个功能,建议您直接将图像裁剪到合适的尺寸。
未在界面中找到对应选项,想要产出优质的模型的话,最好自己处理好训练集图像。
Pad Tokens 填充文本标记
将文本标记填充到更长的长度,让输入序列具有相同的长度,从而使得它们可以在神经网络中进行批量处理。

默认开启,一般不需要调整。
Shuffle Tags 打乱标签
启用此选项将输入提示视为逗号分隔的列表,并对列表进行随机排序,这可以提高编辑性。
启用 Shuffle Tags 可以让模型更好地理解和捕捉输入文本中各个标签之间的关系,从而有助于提高图像生成的质量。
如果你的提示词之间是有明确排序(排序会影响到提示词的权重),那么就不要打开这个选项。
Max Token Length 最大文本标记长度
提高分词器的默认限制,使其超过75。对于大于75的长度,需要使用Pad Tokens进行填充。
调大 Max Token Length 加长文本序列会包含更多的细节和信息,这有助于模型生成更丰富的图像。但是如果文本序列过长,可能会导致模型难以处理和理解,从而影响生成的图像质量。
AdamW Weight Decay (**AdamW 权重衰减)**
用于训练的AdamW优化器的权重衰减。接近0的值使模型更贴近训练数据集,接近1的值使模型更具泛化性,偏离训练数据集。默认值为1e-2(0.01),建议使用低于0.1的值。
一般情况无需调整。
总结
写这一部分的时候深刻的感受到了自己的贫穷,有显存你就用不着一堆节约的选项,随便造作哈哈哈哈,尤其是训练文本编码器(Train Text Encoder)的大幅度改善模型质量的描述着实令人心动。没显存的就只能精打细算,分配好有限的显存,以争取取得当前条件下最优的结构。
有好几个节约显存的方案都是有微小的负面影响,我觉得可能单个方案的影响微小,多个方案的负面影响叠加可能就会明显一点了,所以有显存的情况下,还是关闭节约显存的方案可能更好,这一点欢迎小伙伴们分享自己的感受。
官方文档到这里就读了大半了,主要剩下 Concepts 面板 没讲,其中的提示词部分也是最重要的参数之一,下篇再一起好好聊聊。
更多细节讨论也可以加入 Stable Diffusion 炼丹阁 和道友们一起交流丹道奥秘,比如 讨论药材的选取与火候的控制,成丹的评估方案等等~ 仙途漫漫,携手同行哈哈哈


若有收获,就点个赞吧
0 人点赞
