- 要求
- 稳定扩散 v1
- make sure you’re logged in with
huggingface-cli loginfrom torch import autocast from diffusers import StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained( “CompVis/stable-diffusion-v1-4”, use_auth_token=True ).to(“cuda”) prompt = “a photo of an astronaut riding a horse on mars” with autocast(“cuda”): image = pipe(prompt)[“sample”][0] image.save(“astronaut_rides_horse.png”) - ">**
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
由于与Stability AI和Runway的合作,Stable Diffusion 得以实现__,并建立在我们之前的工作之上:
具有潜在扩散模型的高分辨率图像合成
Robin Rombach 、 Andreas Blattmann 、 Dominik Lorenz、 Patrick Esser、 Björn Ommer
CVPR ‘22 Oral | GitHub | arXiv | 项目页面
 Stable Diffusion是一种潜在的文本到图像扩散模型。感谢Stability AI慷慨的计算捐赠和LAION的支持,我们能够在LAION-5B数据库的一个子集的 512x512 图像上训练潜在扩散模型。与 Google 的Imagen类似,该模型使用冻结的 CLIP ViT-L/14 文本编码器根据文本提示调节模型。凭借其 860M UNet 和 123M 文本编码器,该模型相对轻量级,并在至少具有 10GB VRAM 的 GPU 上运行。请参阅下面的这一部分和模型卡。
Stable Diffusion是一种潜在的文本到图像扩散模型。感谢Stability AI慷慨的计算捐赠和LAION的支持,我们能够在LAION-5B数据库的一个子集的 512x512 图像上训练潜在扩散模型。与 Google 的Imagen类似,该模型使用冻结的 CLIP ViT-L/14 文本编码器根据文本提示调节模型。凭借其 860M UNet 和 123M 文本编码器,该模型相对轻量级,并在至少具有 10GB VRAM 的 GPU 上运行。请参阅下面的这一部分和模型卡。
要求
可以创建并激活一个合适的名为conda 的环境:ldm
conda env create -f environment.yaml conda activate ldm
您还可以通过运行更新现有的潜在扩散环境
conda install pytorch torchvision -c pytorch pip install transformers==4.19.2 diffusers invisible-watermark pip install -e .
稳定扩散 v1
Stable Diffusion v1 指的是模型架构的特定配置,该架构使用下采样因子 8 自动编码器和 860M UNet 和 CLIP ViT-L/14 文本编码器用于扩散模型。该模型在 256x256 图像上进行预训练,然后在 512x512 图像上进行微调。
注意:Stable Diffusion v1 是一种通用的文本到图像扩散模型,因此反映了其训练数据中存在的偏见和(错误)概念。__有关训练过程和数据的详细信息,以及模型的预期用途,请参见相应的模型卡片。
这些权重可通过CompVis 组织在 Hugging Face获得许可,该许可包含特定的基于使用的限制,以防止模型卡告知的误用和伤害,但在其他方面仍然是允许的。虽然许可条款允许商业使用,但我们不建议在没有额外安全机制和考虑的情况下将提供的权重用于服务或产品,因为权重存在已知的限制和偏差,并且对安全和道德部署的研究通用的文本到图像模型是一项持续的工作。权重是研究工件,应该这样对待。
CreativeML OpenRAIL M 许可证是一个Open RAIL M 许可证,改编自BigScience和RAIL Initiative在负责任的 AI 许可领域共同开展的工作。另请参阅有关我们的许可证所基于的BLOOM Open RAIL 许可证的文章。
重量
我们目前提供以下检查点:
- sd-v1-1.ckpt256x256:在laion2B-en上分辨率为 237k 步。在laion 高分辨率512x512上分辨率为 194k 步(来自 LAION-5B 的分辨率为 170M 的示例)。>= 1024x1024
- sd-v1-2.ckpt: 从 恢复sd-v1-1.ckpt。512x512在laion-aesthetics v2 5+上分辨率为 515k 步(laion2B-en 的一个子集,具有估计的美学分数> 5.0,并另外过滤到具有原始大小>= 512x512和估计水印概率的图像< 0.5。水印估计来自LAION-5B 元数据,美学分数是使用LAION-Aesthetics Predictor V2估算的)。
- sd-v1-3.ckpt: 从 恢复sd-v1-2.ckpt。“laion-aesthetics v2 5+”分辨率512x512为 195k 步,文本条件下降 10%,以改进无分类器指导采样。
- sd-v1-4.ckpt: 从 恢复sd-v1-2.ckpt。“laion-aesthetics v2 5+”分辨率512x512为 225k 步,文本条件下降 10%,以改进无分类器指导采样。
使用不同的无分类器指导量表(1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)和 50 个 PLMS 采样步骤进行的评估显示了检查点的相对改进: 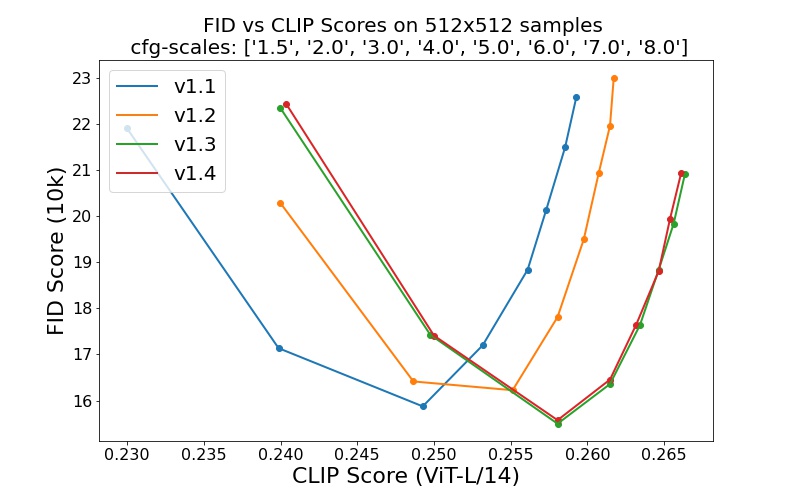
具有稳定扩散的文本到图像


Stable Diffusion 是一种以 CLIP ViT-L/14 文本编码器的(非池化)文本嵌入为条件的潜在扩散模型。我们提供了采样的参考脚本,但也存在扩散器集成,我们希望看到更活跃的社区发展。
参考采样脚本
我们提供了一个参考采样脚本,其中包含
- 一个安全检查器模块,以减少显式输出的可能性,
- 输出的不可见水印,以帮助观众识别图像是机器生成的。
获得stable-diffusion-v1-*-original权重后,将它们链接起来
mkdir -p models/ldm/stable-diffusion-v1/ ln -s
并采样
python scripts/txt2img.py —prompt “a photograph of an astronaut riding a horse” —plms
默认情况下,它使用Katherine Crowson 实施的PLMS采样—scale 7.5器的指导比例,并以 50 步渲染大小为 512x512(它在其上进行训练)的图像。下面列出了所有支持的参数(类型)。python scripts/txt2img.py —help
usage: txt2img.py [-h] [—prompt [PROMPT]] [—outdir [OUTDIR]] [—skip_grid] [—skip_save] [—ddim_steps DDIM_STEPS] [—plms] [—laion400m] [—fixed_code] [—ddim_eta DDIM_ETA] [—n_iter N_ITER] [—H H] [—W W] [—C C] [—f F] [—n_samples N_SAMPLES] [—n_rows N_ROWS] [—scale SCALE] [—from-file FROM_FILE] [—config CONFIG] [—ckpt CKPT] [—seed SEED] [—precision {full,autocast}] optional arguments: -h, —help show this help message and exit —prompt [PROMPT] the prompt to render —outdir [OUTDIR] dir to write results to —skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples —skip_save do not save individual samples. For speed measurements. —ddim_steps DDIM_STEPS number of ddim sampling steps —plms use plms sampling —laion400m uses the LAION400M model —fixed_code if enabled, uses the same starting code across samples —ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling —n_iter N_ITER sample this often —H H image height, in pixel space —W W image width, in pixel space —C C latent channels —f F downsampling factor —n_samples N_SAMPLES how many samples to produce for each given prompt. A.k.a. batch size —n_rows N_ROWS rows in the grid (default: n_samples) —scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty)) —from-file FROM_FILE if specified, load prompts from this file —config CONFIG path to config which constructs model —ckpt CKPT path to checkpoint of model —seed SEED the seed (for reproducible sampling) —precision {full,autocast} evaluate at this precision
注意:所有 v1 版本的推理配置旨在与仅限 EMA 的检查点一起使用。为此use_ema=False在配置中设置,否则代码将尝试从非 EMA 权重切换到 EMA 权重。如果您想检查 EMA 与无 EMA 的效果,我们提供包含两种类型权重的“完整”检查点。对于这些,use_ema=False将加载并使用非 EMA 权重。
扩散器集成
下载和采样 Stable Diffusion 的一种简单方法是使用diffusers 库:
make sure you’re logged in with huggingface-cli login from torch import autocast from diffusers import StableDiffusionPipeline pipe = StableDiffusionPipeline.from_pretrained( “CompVis/stable-diffusion-v1-4”, use_auth_token=True ).to(“cuda”) prompt = “a photo of an astronaut riding a horse on mars” with autocast(“cuda”): image = pipe(prompt)[“sample”][0] image.save(“astronaut_rides_horse.png”)
具有稳定扩散的图像修改
通过使用SDEdit首次提出的扩散去噪机制,该模型可用于不同的任务,例如文本引导的图像到图像的转换和放大。类似于 txt2img 采样脚本,我们提供了一个脚本来使用 Stable Diffusion 执行图像修改。
下面描述了一个示例,其中将在Pinta中制作的粗略草图转换为详细的艺术品。
python scripts/img2img.py —prompt “A fantasy landscape, trending on artstation” —init-img
这里,强度是一个介于 0.0 和 1.0 之间的值,它控制添加到输入图像的噪声量。接近 1.0 的值允许很多变化,但也会产生与输入在语义上不一致的图像。请参见以下示例。
输入

产出


例如,此过程也可用于从基本模型中放大样本。
**
**

若有收获,就点个赞吧
0 人点赞
