内容概览:
🎨 Midjourney 和 Stable Diffusion 等 GenAI 模型的惊人进步
🤖 Midjourney v5 向照片写实主义的令人难以置信的飞跃
👩 GenAI 集成到 3D 渲染和 VFX 工作流中
📸 产品摄影将如何从这些突破中受益
🕹️ GenAI 对 3D 引擎和虚拟场景的潜在影响
📽️ 视频和互动内容与 GenAI 的未来
今天,我们将总结生成人工智能模型在过去 3-6 个月中取得的显著飞跃,以及研究 Gen AI 如何在中长期内将内容融入 3D 渲染和 VFX 工作流程。 前言,我们先科普两个概念,什么是恐怖谷效应以及视觉图灵测试。 恐怖谷效应(Uncanny Valley)是一个由日本工程师日本机器人专家森政弘于 1970 年提出的概念,指的是当人类与非人类对象(如机器人、虚拟人物等)在外表和行为上越来越相似时,观察者对它们的亲近感和好感度会随之增加,直到某个临界点,超过这个临界点后,好感度和亲近感突然降至谷底,产生不适和厌恶的情绪,而随着相似度进一步提高,这种情绪会逐渐消失,直到达到真实对象的感受。这个谷底被称为“恐怖谷”,是指当观察者看到的对象越接近真实人类,但不够真实时,会产生一种让人不舒服的感觉,这种感觉类似于恐惧或厌恶。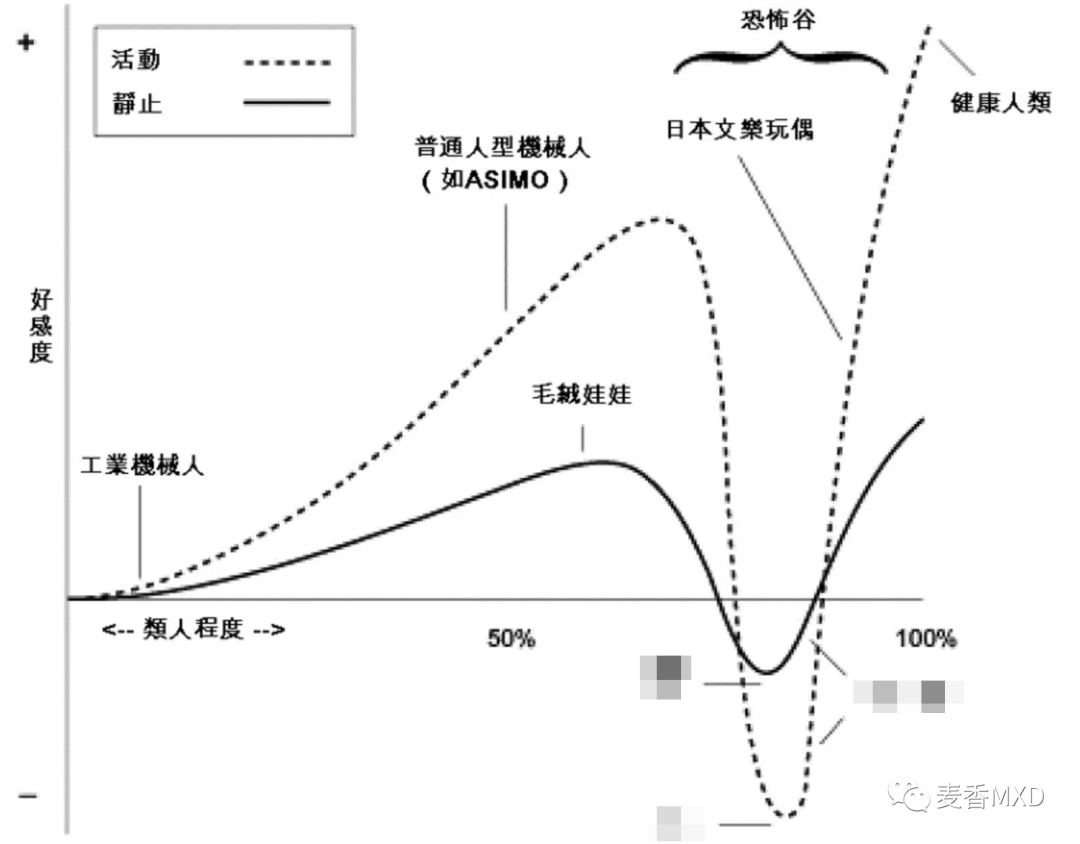

回到正题,首先,让我们总结一下生成式人工智能的最新进展:
在 2022 年的大部分时间里,创作者已经能够使用 Stable Diffusion 和 DALL-E2 等工具结合一系列修复和后处理工具来创建看起来与现实难以区分的图像。
从 2023 年开始,随着 ControlNet 和可组合 LoRAs 的兴起,技术艺术家已经能够对 Stable Diffusion 施加更大的艺术控制,以获得更加逼真的效果。
Midjourney v5 现在将这个多步骤过程变成了一个单一的、定义明确的文本提示。无需输入多个提示一起传递。凭借 Discord 界面,虽然Midjourney 缺乏 Adobe Firefly 以创作者为中心的用户体验,但改进后的自然语言动态范围还是值得被吹捧
真实摄像
Midjourney 和 Stable Diffusion 在真实图像生成方面取得的巨大进步

3D渲染
Linus 用 Midjourney 生成的汽车上的人,看看挡风玻璃和引擎盖上的倒影……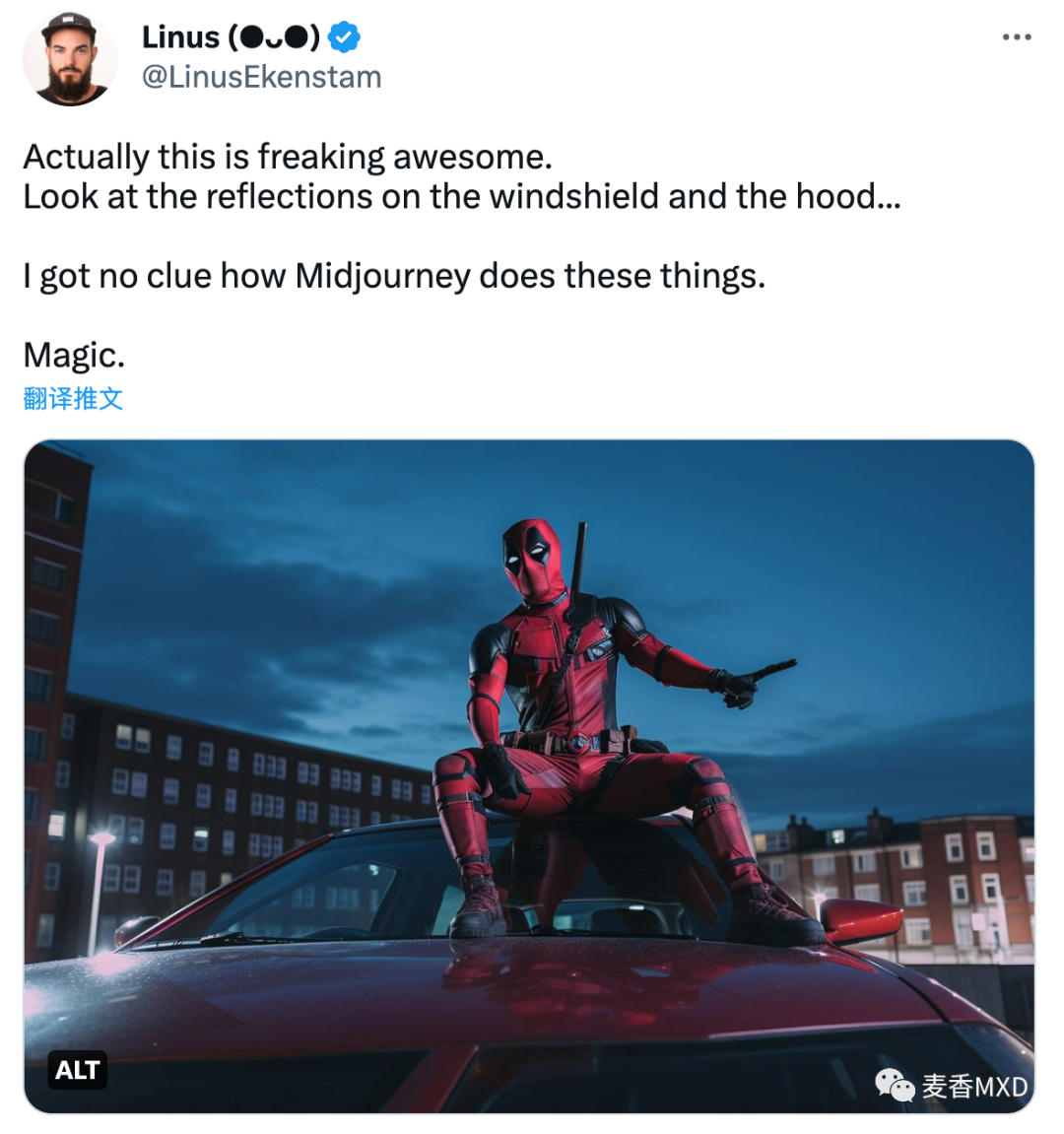
电影特效
生成 AI 穿越恐怖谷,电影级别的特效场景
虚拟场景
虚拟场景也没问题。看下面这个图,只要看看图中的椅子、编织物、窗户的高光等细节,Midjourney 已轻松超越了 Unreal Engine 或 Octane 渲染器的质量,动态范围完美无缺! 这个场景是波西米亚风格客厅的一个阳光明媚的角落,客厅里有一张花边吊椅。

产品摄影
产品摄影也得到了巨大的提升,在创建产品之前想象产品,或者使用实际产品摄影,微调模型进行虚拟拍摄。
3D引擎
在玩过 ControlNet 之后,NVIDIA CEO 黄仁勋所说:“每个像素都将很快生成”也就不足为奇了 在短期内,我们将看到融合经典 3D + 生成 AI 的混合方法将占据主导地位。第一次运行轻量级 3D 引擎,然后在顶部运行生成过滤器以将其转换为 AAA 质量。
视频互动
随着生成式 AI 的兴起,对于许多可视化用例而言,显式建模现实似乎被高估了。相反,混合AI已经可以实现! 例如,投入一个看起来不可思议的虚幻模型,用它来驱动性能。然后通过生成式 AI“过滤器”运行它并获得更加逼真的效果,如图:
GenAI未来
视频还处于起步阶段,但显然是下一个目标。乔恩在他的公寓里拍摄用 iPhone + Midjourney + Runway.ml Gen-1 制作了一部短片。个人就可以做出像詹姆斯·卡梅隆 (James Cameron) 风格的虚拟制作。 想象一下我们 6 个月后…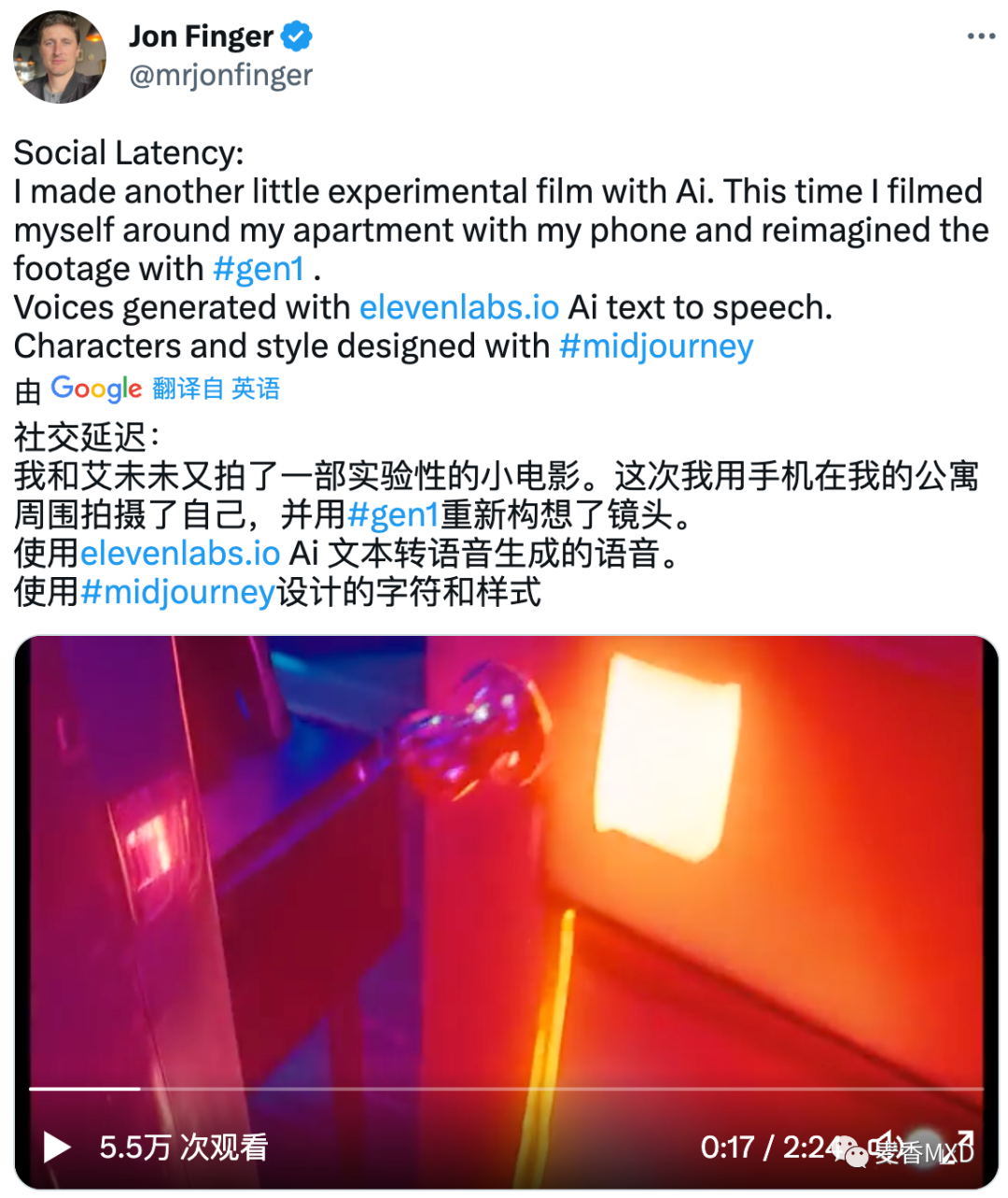
现有AIGC交流群,大量实用资源和干货等你来拿,加V:maixiang188,拉你入群免费领取资源。 如果想催更文章,麻烦小伙伴们多给本篇点一下 **“ 在看 ” 和“ 赞 ”** ,并在右上角“ … ” 里面将麦香MXD设为星标,这样就不会做过后续精彩文章的推送啦🥳


若有收获,就点个赞吧
0 人点赞
