这两天被Ai各种轰炸,先是GPT-4,后是百度“温馨义演”,今天还有一个重磅——Midjourney发布了V5。
上一篇《放心,Ai暂时还取代不了这类设计师》中才提到Midjourney现阶段还无法生成可用的B端微软风3D质感图标,今天发布的V5版本,反手就把我的认知吊着打。
不多说,先看图。



前提在于,跟上次V4喂的是完全一样的图,和提示词,来看一下V4和V5的效果对比。
没有对比没有伤害,非常直观了吧,如果说V4生成的图像还是婴儿在牙牙学语,那V5的作品已经可以中学毕业了。
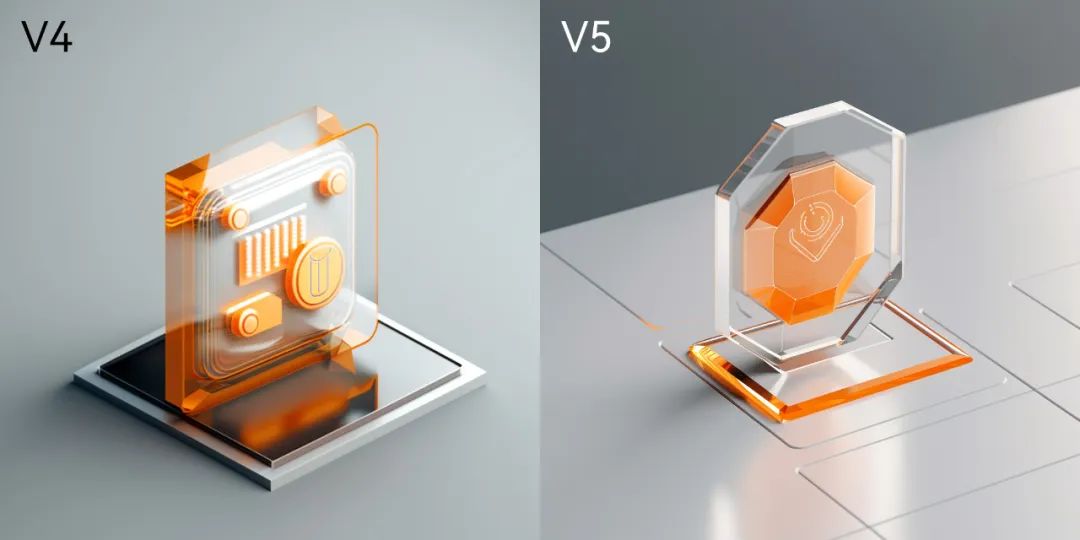
根据官方给出的V5升级优化点,可以在新的作品中一一找到影子,比如材质系统整体提升了一个层次,玻璃更像玻璃、亚克力更通透、地面有菲涅尔反射;比如光影质感更真实,V4的细节明显有很多结构模糊交代不清的地方,V5的光源环境更贴近真实物理环境,几乎达到了摄影级水准;再比如语义理解,V4的元素表达不知所云,V5的主体物已经做到能让人看懂意思了,在元素的几何结构上也有明显的升级,大眼看过去没有明显的结构错误。
还有相当重要的一点,上一篇吐槽过Mj无法理解我想要的“light gray background with simple linear detail”(带有简单线条状细节的浅灰色背景)。
再看看V5的作品,地面上出现了非常精准的细节!有一些具有科技感的块面和线条,甚至局部线槽里还联想到了发光,这背后的思考量,想想都觉得可怕。
以及分辨率的提升,以上的四宫格图都是按照2048*2048px的规格生成。传闻V5模型的训练只花了5个月,这迭代速度,不服不行。
抛开这个案例,来看看别的。






目前已知V5相比V4有着以下的提升:
① 图像真实感提升,之前版本生成的结果更偏插画,V5的结果更偏照片
② 图像的光感提升,照明系统和光源层次更丰富
③ 局部细节的刻画优化,如人物的眼部、手部,降低形体物理结构上出bug的概率
④ 改进了图像提示性能,提升了语义理解精度,使其更为可靠和准确
⑤ 图像处理技术大幅优化,包括更广的风格范围和更敏捷的反应速度,更高质量的图像,以及更精细准确的细节呈现
⑥ 添加了一些实验性的新功能,包括无缝拼接 —tile参数、支持长宽比大于2:1的图像—ar参数,以及通过调整 —iw参数 来平衡图像提示和文本提示的关系
关于第1点,我们可以再看一组案例(以下组图引用自公众号:AIDEAS)
提示词:street photo in new york, medium shot, natural lighting, shot on fujifilm, detailed and realistic environment, cinematic —ar 2:1
先看V4的作品效果:



接着看V5的作品:




一个字,惊!
作为一个端着相机扫街多年的人,完全看不出这组图并非真实摄影。那句话怎么说来着?对,摄影学不存在了。
还有其他领域的案例,比如空间设计。


再比如,美食摄影。

相信今晚的你我难安,一部分情绪被Ai创造的审美高地牢牢地拿捏,一部分情绪陷在对未来不确定性的迷惘之中。
也许未来所有人的职业都会重新再分配,成为不同行业、不同领域的Ai训练师,或者模型开发者。总之一切向前看,保持能量不停学习,Ai目前给人类提供的还是“术”而非“道”。
“有道无术术尚可求,有术无道,止于术”
截止此刻,朋友给我发来了资讯:微软新版ffice Copilot可实现Ai自动制作PPT,不说了,看介绍去😂
https://news.microsoft.com/reinventing-productivity/
#**推荐阅读**#
#**认识一下**#


若有收获,就点个赞吧
0 人点赞
